Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction recognition in real-world videos
Paper and Code

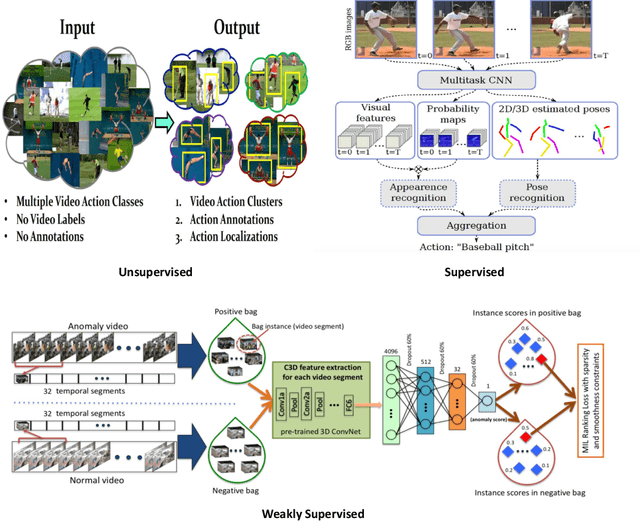
The goal of human action recognition is to temporally or spatially localize the human action of interest in video sequences. Temporal localization (i.e. indicating the start and end frames of the action in a video) is referred to as frame-level detection. Spatial localization, which is more challenging, means to identify the pixels within each action frame that correspond to the action. This setting is usually referred to as pixel-level detection. In this chapter, we are using action, activity, event interchangeably.
View paper on