 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time adaptation for geospatial point cloud semantic segmentation with distinct domain shifts
Jul 08, 2024Domain adaptation (DA) techniques help deep learning models generalize across data shifts for point cloud semantic segmentation (PCSS). Test-time adaptation (TTA) allows direct adaptation of a pre-trained model to unlabeled data during inference stage without access to source data or additional training, avoiding privacy issues and large computational resources. We address TTA for geospatial PCSS by introducing three domain shift paradigms: photogrammetric to airborne LiDAR, airborne to mobile LiDAR, and synthetic to mobile laser scanning. We propose a TTA method that progressively updates batch normalization (BN) statistics with each testing batch. Additionally, a self-supervised learning module optimizes learnable BN affine parameters. Information maximization and reliability-constrained pseudo-labeling improve prediction confidence and supply supervisory signals. Experimental results show our method improves classification accuracy by up to 20\% mIoU, outperforming other methods. For photogrammetric (SensatUrban) to airborne (Hessigheim 3D) adaptation at the inference stage, our method achieves 59.46\% mIoU and 85.97\% OA without retraining or fine-turning.
A sustainable development perspective on urban-scale roof greening priorities and benefits
Apr 21, 2024



Greenspaces are tightly linked to human well-being. Yet, rapid urbanization has exacerbated greenspace exposure inequality and declining human life quality. Roof greening has been recognized as an effective strategy to mitigate these negative impacts. Understanding priorities and benefits is crucial to promoting green roofs. Here, using geospatial big data, we conduct an urban-scale assessment of roof greening at a single building level in Hong Kong from a sustainable development perspective. We identify that 85.3\% of buildings reveal potential and urgent demand for roof greening. We further find green roofs could increase greenspace exposure by \textasciitilde61\% and produce hundreds of millions (HK\$) in economic benefits annually but play a small role in urban heat mitigation (\textasciitilde0.15\degree{C}) and annual carbon emission offsets (\textasciitilde0.8\%). Our study offers a comprehensive assessment of roof greening, which could provide reference for sustainable development in cities worldwide, from data utilization to solutions and findings.
UB-FineNet: Urban Building Fine-grained Classification Network for Open-access Satellite Images
Mar 04, 2024Fine classification of city-scale buildings from satellite remote sensing imagery is a crucial research area with significant implications for urban planning, infrastructure development, and population distribution analysis. However, the task faces big challenges due to low-resolution overhead images acquired from high altitude space-borne platforms and the long-tail sample distribution of fine-grained urban building categories, leading to severe class imbalance problem. To address these issues, we propose a deep network approach to fine-grained classification of urban buildings using open-access satellite images. A Denoising Diffusion Probabilistic Model (DDPM) based super-resolution method is first introduced to enhance the spatial resolution of satellite images, which benefits from domain-adaptive knowledge distillation. Then, a new fine-grained classification network with Category Information Balancing Module (CIBM) and Contrastive Supervision (CS) technique is proposed to mitigate the problem of class imbalance and improve the classification robustness and accuracy. Experiments on Hong Kong data set with 11 fine building types revealed promising classification results with a mean Top-1 accuracy of 60.45\%, which is on par with street-view image based approaches. Extensive ablation study shows that CIBM and CS improve Top-1 accuracy by 2.6\% and 3.5\% compared to the baseline method, respectively. And both modules can be easily inserted into other classification networks and similar enhancements have been achieved. Our research contributes to the field of urban analysis by providing a practical solution for fine classification of buildings in challenging mega city scenarios solely using open-access satellite images. The proposed method can serve as a valuable tool for urban planners, aiding in the understanding of economic, industrial, and population distribution.
Urban GeoBIM construction by integrating semantic LiDAR point clouds with as-designed BIM models
Apr 23, 2023Developments in three-dimensional real worlds promote the integration of geoinformation and building information models (BIM) known as GeoBIM in urban construction. Light detection and ranging (LiDAR) integrated with global navigation satellite systems can provide geo-referenced spatial information. However, constructing detailed urban GeoBIM poses challenges in terms of LiDAR data quality. BIM models designed from software are rich in geometrical information but often lack accurate geo-referenced locations. In this paper, we propose a complementary strategy that integrates LiDAR point clouds with as-designed BIM models for reconstructing urban scenes. A state-of-the-art deep learning framework and graph theory are first combined for LiDAR point cloud segmentation. A coarse-to-fine matching program is then developed to integrate object point clouds with corresponding BIM models. Results show the overall segmentation accuracy of LiDAR datasets reaches up to 90%, and average positioning accuracies of BIM models are 0.023 m for pole-like objects and 0.156 m for buildings, demonstrating the effectiveness of the method in segmentation and matching processes. This work offers a practical solution for rapid and accurate urban GeoBIM construction.
One Class One Click: Quasi Scene-level Weakly Supervised Point Cloud Semantic Segmentation with Active Learning
Nov 23, 2022
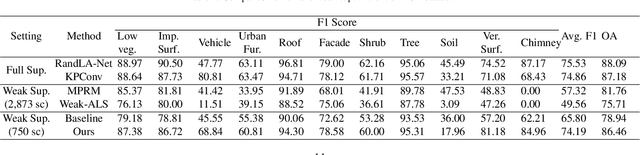
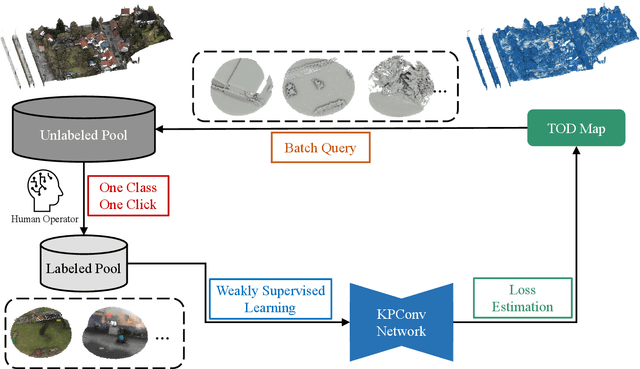

Reliance on vast annotations to achieve leading performance severely restricts the practicality of large-scale point cloud semantic segmentation. For the purpose of reducing data annotation costs, effective labeling schemes are developed and contribute to attaining competitive results under weak supervision strategy. Revisiting current weak label forms, we introduce One Class One Click (OCOC), a low cost yet informative quasi scene-level label, which encapsulates point-level and scene-level annotations. An active weakly supervised framework is proposed to leverage scarce labels by involving weak supervision from global and local perspectives. Contextual constraints are imposed by an auxiliary scene classification task, respectively based on global feature embedding and point-wise prediction aggregation, which restricts the model prediction merely to OCOC labels. Furthermore, we design a context-aware pseudo labeling strategy, which effectively supplement point-level supervisory signals. Finally, an active learning scheme with a uncertainty measure - temporal output discrepancy is integrated to examine informative samples and provides guidance on sub-clouds query, which is conducive to quickly attaining desirable OCOC annotations and reduces the labeling cost to an extremely low extent. Extensive experimental analysis using three LiDAR benchmarks collected from airborne, mobile and ground platforms demonstrates that our proposed method achieves very promising results though subject to scarce labels. It considerably outperforms genuine scene-level weakly supervised methods by up to 25\% in terms of average F1 score and achieves competitive results against full supervision schemes. On terrestrial LiDAR dataset - Semantics3D, using approximately 2\textpertenthousand{} of labels, our method achieves an average F1 score of 85.2\%, which increases by 11.58\% compared to the baseline model.
A new weakly supervised approach for ALS point cloud semantic segmentation
Oct 06, 2021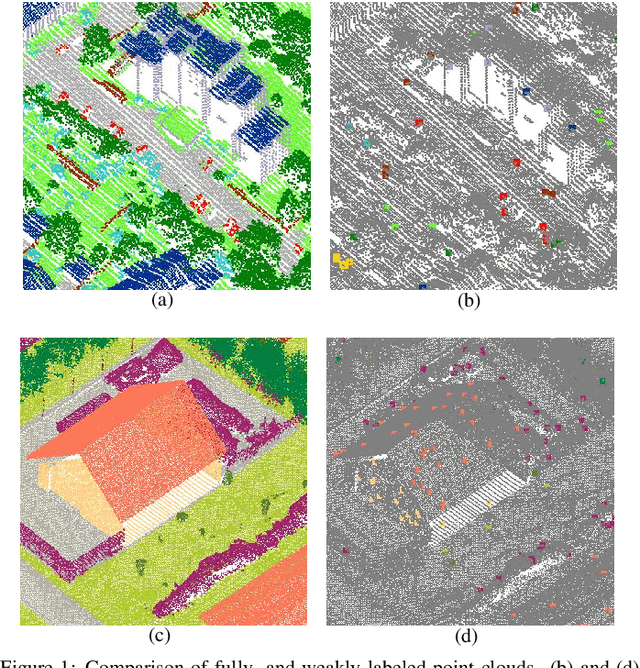
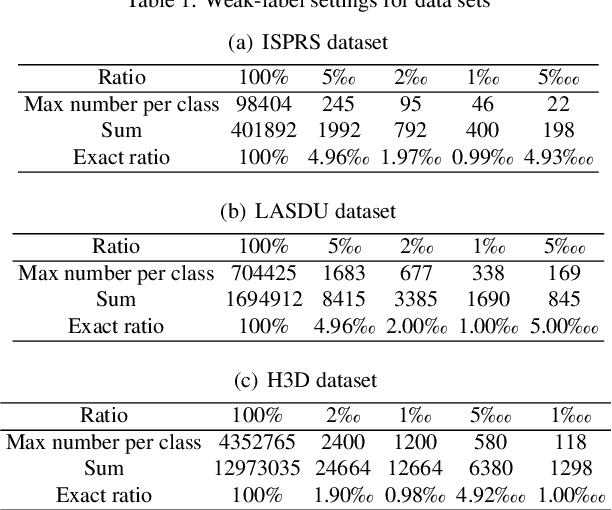
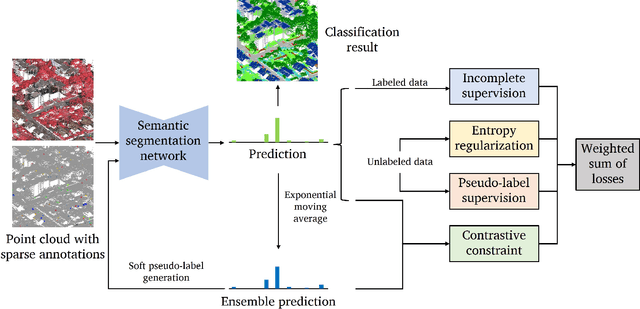
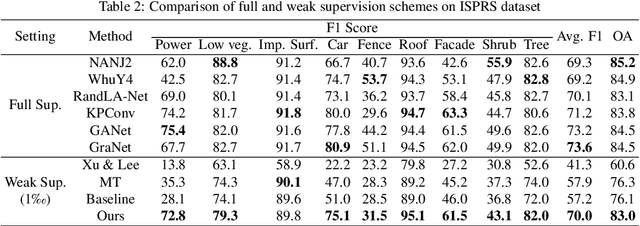
While there are novel point cloud semantic segmentation schemes that continuously surpass state-of-the-art results, the success of learning an effective model usually rely on the availability of abundant labeled data. However, data annotation is a time-consuming and labor-intensive task, particularly for large-scale airborne laser scanning (ALS) point clouds involving multiple classes in urban areas. Thus, how to attain promising results while largely reducing labeling works become an essential issue. In this study, we propose a deep-learning based weakly supervised framework for semantic segmentation of ALS point clouds, exploiting potential information from unlabeled data subject to incomplete and sparse labels. Entropy regularization is introduced to penalize the class overlap in predictive probability. Additionally, a consistency constraint by minimizing the discrepancy distance between instant and ensemble predictions is designed to improve the robustness of predictions. Finally, we propose an online soft pseudo-labeling strategy to create extra supervisory sources in an efficient and nonpaprametric way. Extensive experimental analysis using three benchmark datasets demonstrates that in case of sparse point annotations, our proposed method significantly boosts the classification performance without compromising the computational efficiency. It outperforms current weakly supervised methods and achieves a comparable result against full supervision competitors. For the ISPRS 3D Labeling Vaihingen data, by using only 0.1% of labels, our method achieves an overall accuracy of 83.0% and an average F1 score of 70.0%, which have increased by 6.9% and 12.8% respectively, compared to model trained by sparse label information only.
Weakly Supervised Pseudo-Label assisted Learning for ALS Point Cloud Semantic Segmentation
May 05, 2021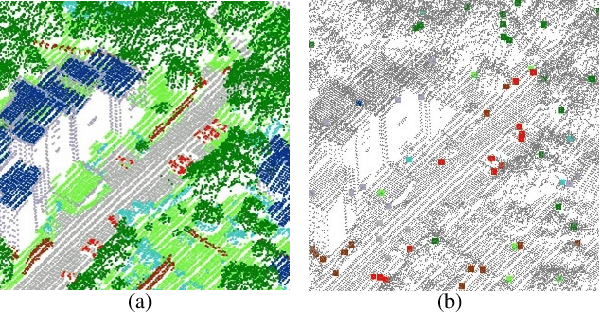
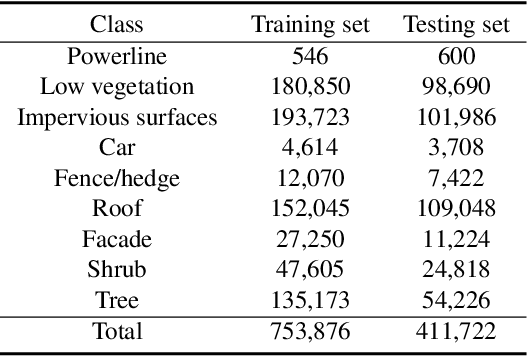

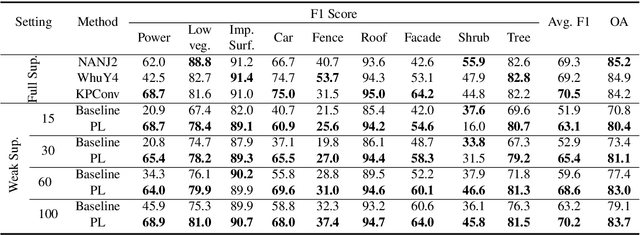
Competitive point cloud semantic segmentation results usually rely on a large amount of labeled data. However, data annotation is a time-consuming and labor-intensive task, particularly for three-dimensional point cloud data. Thus, obtaining accurate results with limited ground truth as training data is considerably important. As a simple and effective method, pseudo labels can use information from unlabeled data for training neural networks. In this study, we propose a pseudo-label-assisted point cloud segmentation method with very few sparsely sampled labels that are normally randomly selected for each class. An adaptive thresholding strategy was proposed to generate a pseudo-label based on the prediction probability. Pseudo-label learning is an iterative process, and pseudo labels were updated solely on ground-truth weak labels as the model converged to improve the training efficiency. Experiments using the ISPRS 3D sematic labeling benchmark dataset indicated that our proposed method achieved an equally competitive result compared to that using a full supervision scheme with only up to 2$\unicode{x2030}$ of labeled points from the original training set, with an overall accuracy of 83.7% and an average F1 score of 70.2%.