 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Pseudo-Label assisted Learning for ALS Point Cloud Semantic Segmentation
Paper and Code
May 05, 2021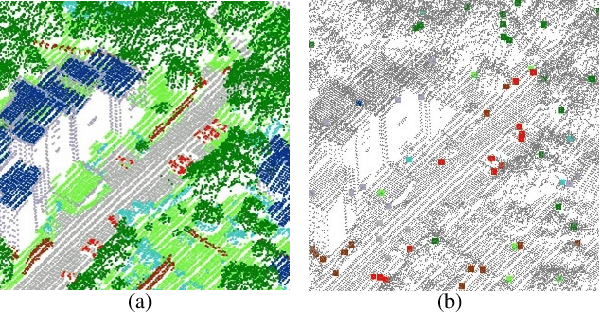
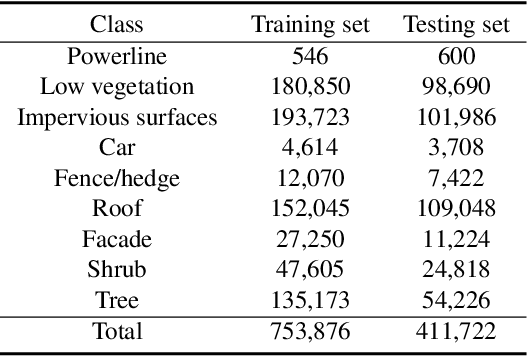

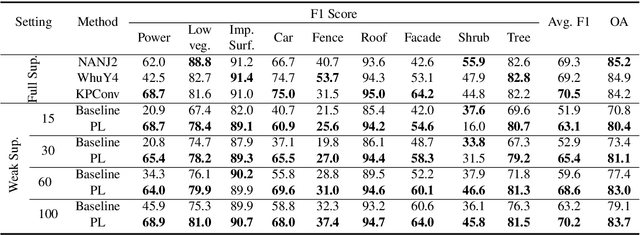
Competitive point cloud semantic segmentation results usually rely on a large amount of labeled data. However, data annotation is a time-consuming and labor-intensive task, particularly for three-dimensional point cloud data. Thus, obtaining accurate results with limited ground truth as training data is considerably important. As a simple and effective method, pseudo labels can use information from unlabeled data for training neural networks. In this study, we propose a pseudo-label-assisted point cloud segmentation method with very few sparsely sampled labels that are normally randomly selected for each class. An adaptive thresholding strategy was proposed to generate a pseudo-label based on the prediction probability. Pseudo-label learning is an iterative process, and pseudo labels were updated solely on ground-truth weak labels as the model converged to improve the training efficiency. Experiments using the ISPRS 3D sematic labeling benchmark dataset indicated that our proposed method achieved an equally competitive result compared to that using a full supervision scheme with only up to 2$\unicode{x2030}$ of labeled points from the original training set, with an overall accuracy of 83.7% and an average F1 score of 70.2%.