 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning ON Large Datasets Using Bit-String Trees
Aug 23, 2025This thesis develops computational methods in similarity-preserving hashing, classification, and cancer genomics. Standard space partitioning-based hashing relies on Binary Search Trees (BSTs), but their exponential growth and sparsity hinder efficiency. To overcome this, we introduce Compressed BST of Inverted hash tables (ComBI), which enables fast approximate nearest-neighbor search with reduced memory. On datasets of up to one billion samples, ComBI achieves 0.90 precision with 4X-296X speed-ups over Multi-Index Hashing, and also outperforms Cellfishing.jl on single-cell RNA-seq searches with 2X-13X gains. Building on hashing structures, we propose Guided Random Forest (GRAF), a tree-based ensemble classifier that integrates global and local partitioning, bridging decision trees and boosting while reducing generalization error. Across 115 datasets, GRAF delivers competitive or superior accuracy, and its unsupervised variant (uGRAF) supports guided hashing and importance sampling. We show that GRAF and ComBI can be used to estimate per-sample classifiability, which enables scalable prediction of cancer patient survival. To address challenges in interpreting mutations, we introduce Continuous Representation of Codon Switches (CRCS), a deep learning framework that embeds genetic changes into numerical vectors. CRCS allows identification of somatic mutations without matched normals, discovery of driver genes, and scoring of tumor mutations, with survival prediction validated in bladder, liver, and brain cancers. Together, these methods provide efficient, scalable, and interpretable tools for large-scale data analysis and biomedical applications.
Cost-Effective, Low Latency Vector Search with Azure Cosmos DB
May 09, 2025Vector indexing enables semantic search over diverse corpora and has become an important interface to databases for both users and AI agents. Efficient vector search requires deep optimizations in database systems. This has motivated a new class of specialized vector databases that optimize for vector search quality and cost. Instead, we argue that a scalable, high-performance, and cost-efficient vector search system can be built inside a cloud-native operational database like Azure Cosmos DB while leveraging the benefits of a distributed database such as high availability, durability, and scale. We do this by deeply integrating DiskANN, a state-of-the-art vector indexing library, inside Azure Cosmos DB NoSQL. This system uses a single vector index per partition stored in existing index trees, and kept in sync with underlying data. It supports < 20ms query latency over an index spanning 10 million of vectors, has stable recall over updates, and offers nearly 15x and 41x lower query cost compared to Zilliz and Pinecone serverless enterprise products. It also scales out to billions of vectors via automatic partitioning. This convergent design presents a point in favor of integrating vector indices into operational databases in the context of recent debates on specialized vector databases, and offers a template for vector indexing in other databases.
Enhash: A Fast Streaming Algorithm For Concept Drift Detection
Nov 07, 2020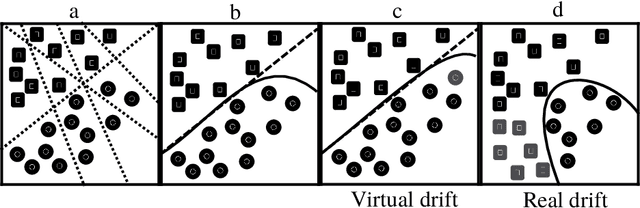

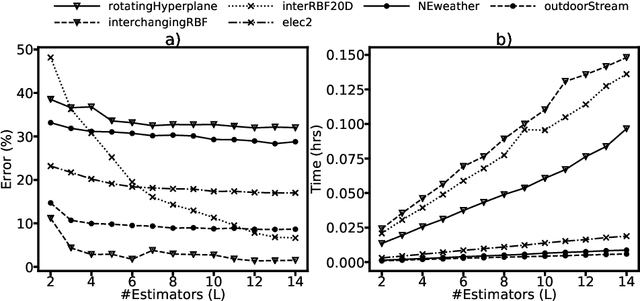
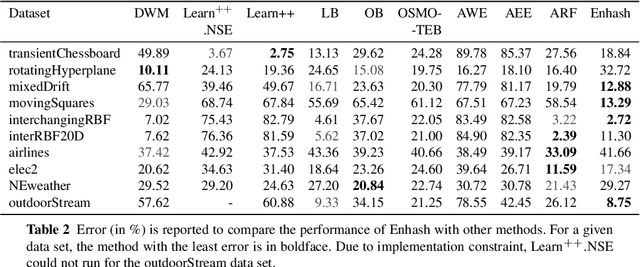
We propose Enhash, a fast ensemble learner that detects \textit{concept drift} in a data stream. A stream may consist of abrupt, gradual, virtual, or recurring events, or a mixture of various types of drift. Enhash employs projection hash to insert an incoming sample. We show empirically that the proposed method has competitive performance to existing ensemble learners in much lesser time. Also, Enhash has moderate resource requirements. Experiments relevant to performance comparison were performed on 6 artificial and 4 real data sets consisting of various types of drifts.
A Weighted Mutual k-Nearest Neighbour for Classification Mining
May 14, 2020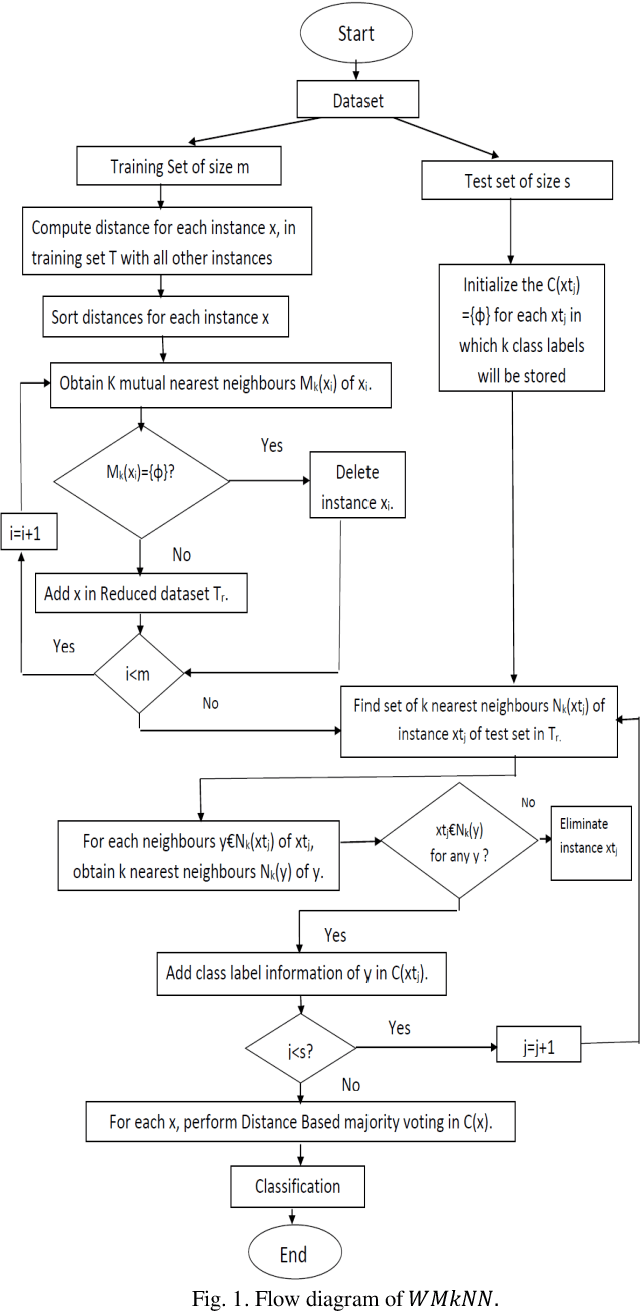
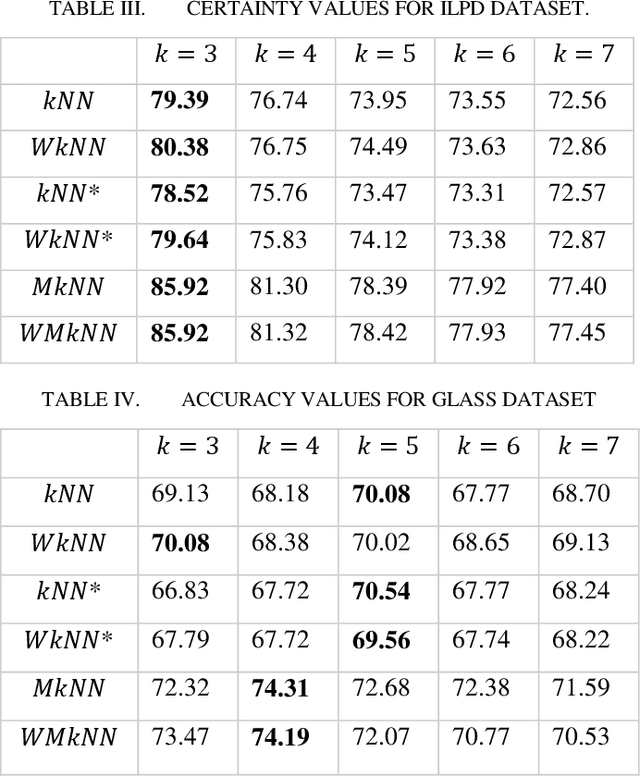
kNN is a very effective Instance based learning method, and it is easy to implement. Due to heterogeneous nature of data, noises from different possible sources are also widespread in nature especially in case of large-scale databases. For noise elimination and effect of pseudo neighbours, in this paper, we propose a new learning algorithm which performs the task of anomaly detection and removal of pseudo neighbours from the dataset so as to provide comparative better results. This algorithm also tries to minimize effect of those neighbours which are distant. A concept of certainty measure is also introduced for experimental results. The advantage of using concept of mutual neighbours and distance-weighted voting is that, dataset will be refined after removal of anomaly and weightage concept compels to take into account more consideration of those neighbours, which are closer. Consequently, finally the performance of proposed algorithm is calculated.
Guided Random Forest and its application to data approximation
Sep 02, 2019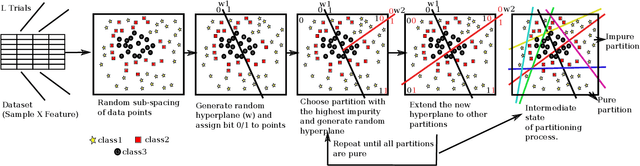

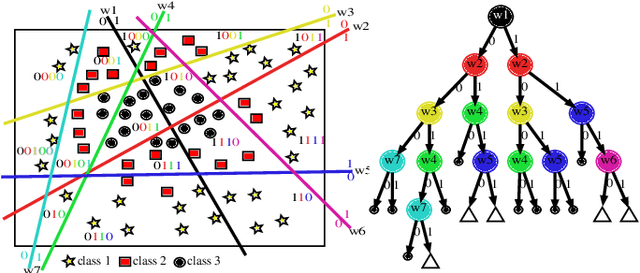
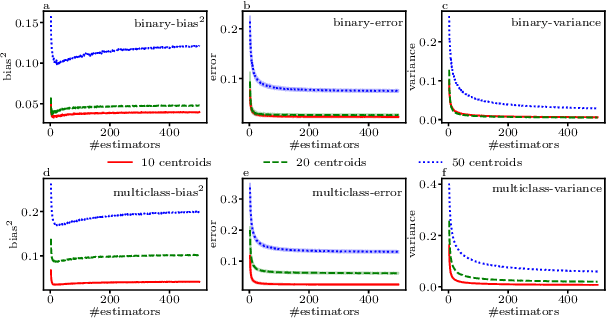
We present a new way of constructing an ensemble classifier, named the Guided Random Forest (GRAF) in the sequel. GRAF extends the idea of building oblique decision trees with localized partitioning to obtain a global partitioning. We show that global partitioning bridges the gap between decision trees and boosting algorithms. We empirically demonstrate that global partitioning reduces the generalization error bound. Results on 115 benchmark datasets show that GRAF yields comparable or better results on a majority of datasets. We also present a new way of approximating the datasets in the framework of random forests.
Continuous Toolpath Planning in Additive Manufacturing
Aug 19, 2019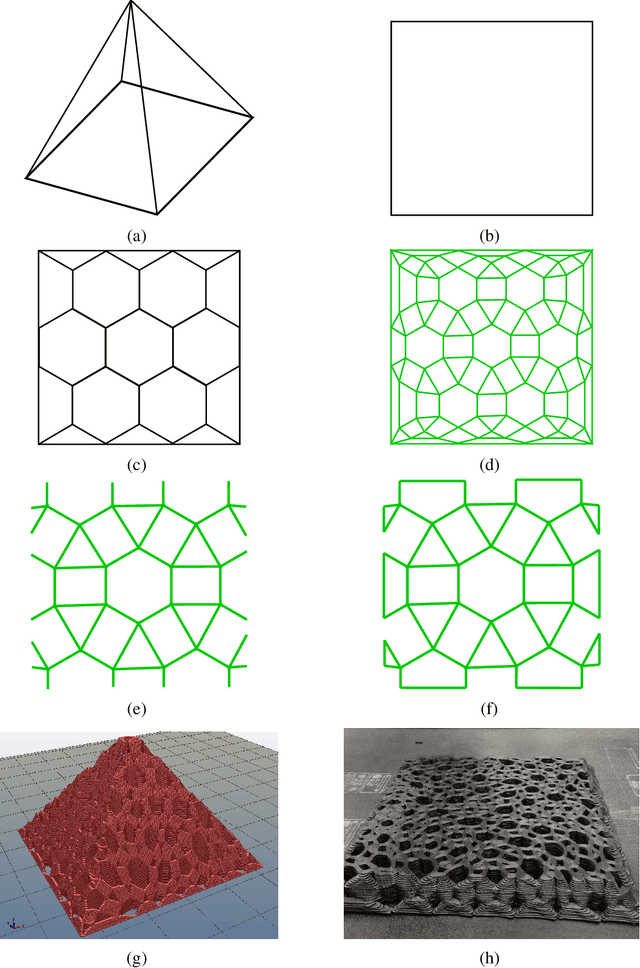
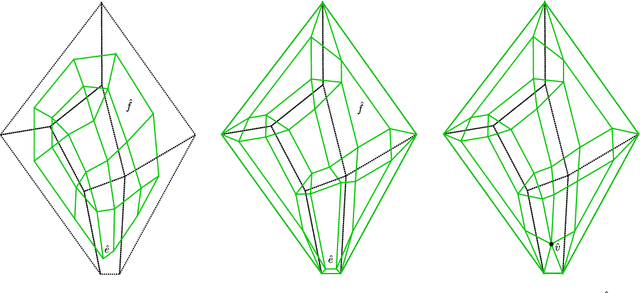
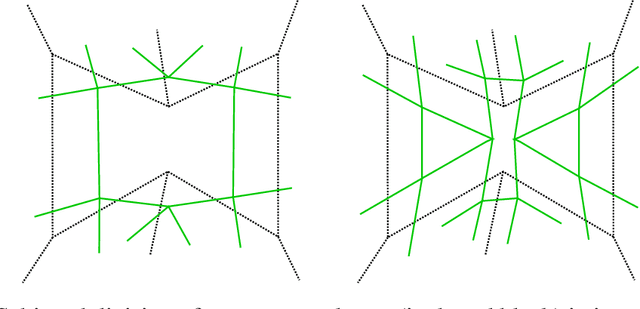
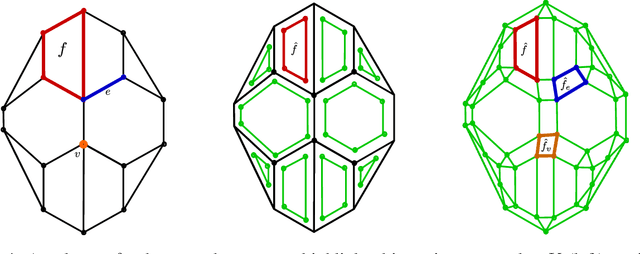
We develop a framework that creates a new polygonal mesh representation of the 3D domain of a layer-by-layer 3D printing job on which we identify single, continuous tool paths covering each connected piece of the domain in every layer. We present a tool path algorithm that traverses each such continuous tool path with no crossovers. The key construction at the heart of our framework is a novel Euler transformation that we introduced recently in a separate manuscript. Our Euler transformation converts a 2-dimensional cell complex K into a new 2-complex K^ such that every vertex in the 1-skeleton G^ of K^ has degree 4. Hence G^ is Eulerian, and an Eulerian tour can be followed to print all edges in a continuous fashion without stops. We start with a mesh K of the union of polygons obtained by projecting all layers to the plane. First we compute its Euler transformation K^. In the slicing step, we clip K^ at each layer i using its polygon to obtain K^_i. We then patch K^_i by adding edges such that any odd-degree nodes created by slicing are transformed to have even degrees again. We print extra support edges in place of any segments left out to ensure there are no edges without support in the next layer above. These support edges maintain the Euler nature of K^_i. Finally, we describe a tree-based search algorithm that builds the continuous tool path by traversing "concentric" cycles in the Euler complex. Our algorithm produces a tool path that avoids material collisions and crossovers, and can be printed in a continuous fashion irrespective of complex geometry or topology of the domain (e.g., holes).
Pentagon at MEDIQA 2019: Multi-task Learning for Filtering and Re-ranking Answers using Language Inference and Question Entailment
Jul 01, 2019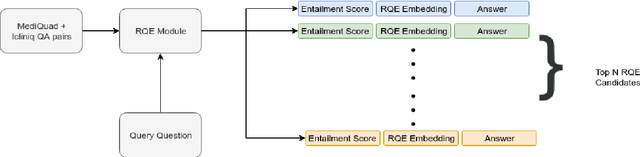
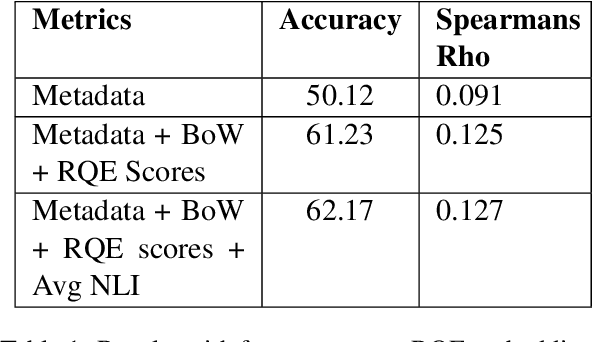
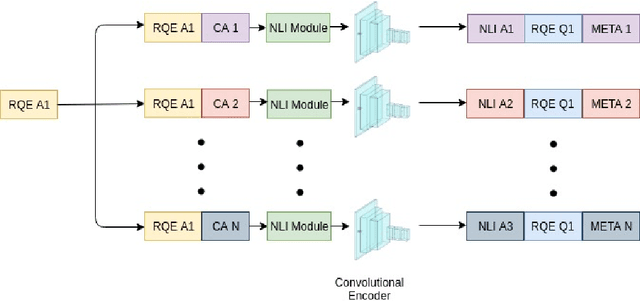
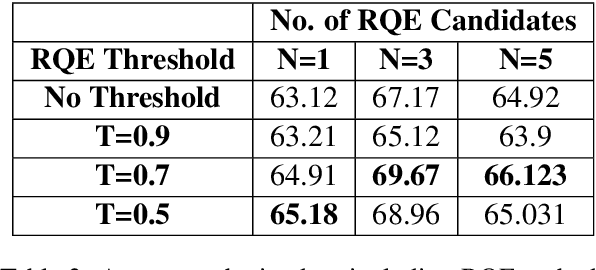
Parallel deep learning architectures like fine-tuned BERT and MT-DNN, have quickly become the state of the art, bypassing previous deep and shallow learning methods by a large margin. More recently, pre-trained models from large related datasets have been able to perform well on many downstream tasks by just fine-tuning on domain-specific datasets . However, using powerful models on non-trivial tasks, such as ranking and large document classification, still remains a challenge due to input size limitations of parallel architecture and extremely small datasets (insufficient for fine-tuning). In this work, we introduce an end-to-end system, trained in a multi-task setting, to filter and re-rank answers in the medical domain. We use task-specific pre-trained models as deep feature extractors. Our model achieves the highest Spearman's Rho and Mean Reciprocal Rank of 0.338 and 0.9622 respectively, on the ACL-BioNLP workshop MediQA Question Answering shared-task.