 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide and Seek: Outwitting Community Detection Algorithms
Feb 22, 2021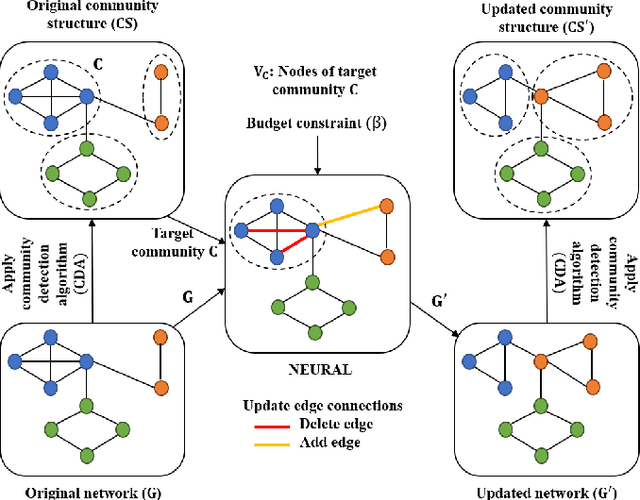
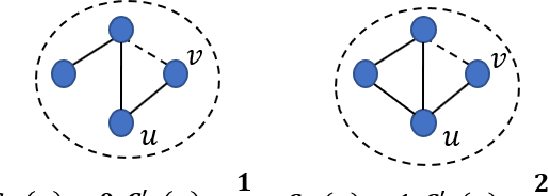
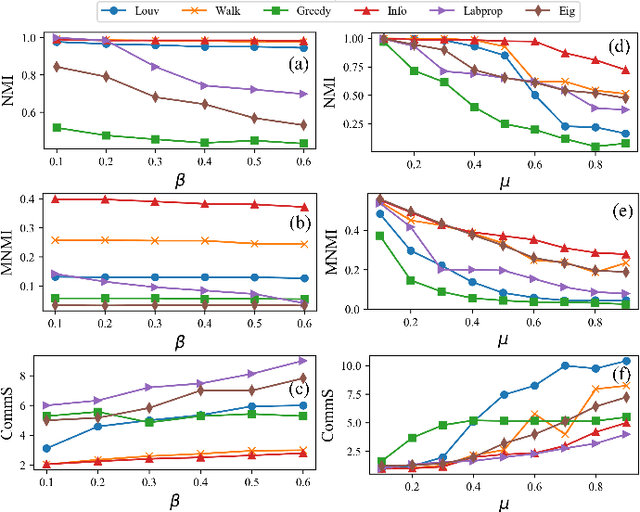
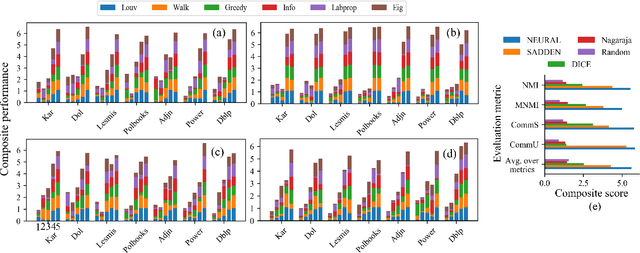
Community affiliation of a node plays an important role in determining its contextual position in the network, which may raise privacy concerns when a sensitive node wants to hide its identity in a network. Oftentimes, a target community seeks to protect itself from adversaries so that its constituent members remain hidden inside the network. The current study focuses on hiding such sensitive communities so that the community affiliation of the targeted nodes can be concealed. This leads to the problem of community deception which investigates the avenues of minimally rewiring nodes in a network so that a given target community maximally hides from a community detection algorithm. We formalize the problem of community deception and introduce NEURAL, a novel method that greedily optimizes a node-centric objective function to determine the rewiring strategy. Theoretical settings pose a restriction on the number of strategies that can be employed to optimize the objective function, which in turn reduces the overhead of choosing the best strategy from multiple options. We also show that our objective function is submodular and monotone. When tested on both synthetic and 7 real-world networks, NEURAL is able to deceive 6 widely used community detection algorithms. We benchmark its performance with respect to 4 state-of-the-art methods on 4 evaluation metrics. Additionally, our qualitative analysis of 3 other attributed real-world networks reveals that NEURAL, quite strikingly, captures important meta-information about edges that otherwise could not be inferred by observing only their topological structures.
* 10 tables, 7 figures, 10 main pages, 3 supplementary pages, Accepted in IEEE Transactions on Computational Social Systems
Enhash: A Fast Streaming Algorithm For Concept Drift Detection
Nov 07, 2020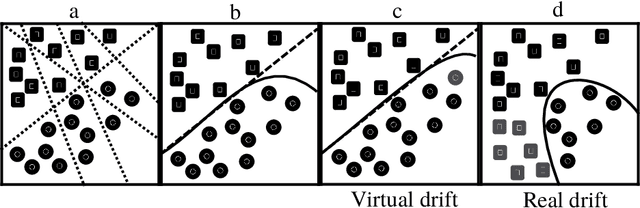

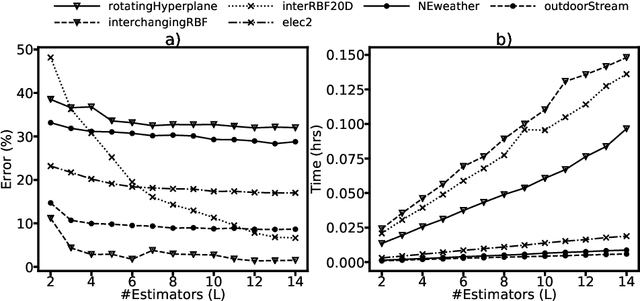
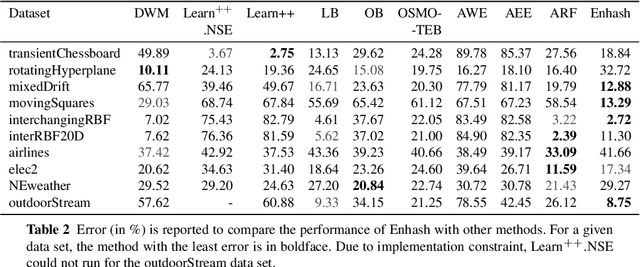
We propose Enhash, a fast ensemble learner that detects \textit{concept drift} in a data stream. A stream may consist of abrupt, gradual, virtual, or recurring events, or a mixture of various types of drift. Enhash employs projection hash to insert an incoming sample. We show empirically that the proposed method has competitive performance to existing ensemble learners in much lesser time. Also, Enhash has moderate resource requirements. Experiments relevant to performance comparison were performed on 6 artificial and 4 real data sets consisting of various types of drifts.
Guided Random Forest and its application to data approximation
Sep 02, 2019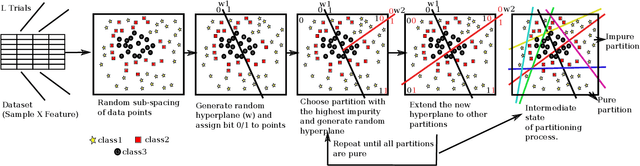

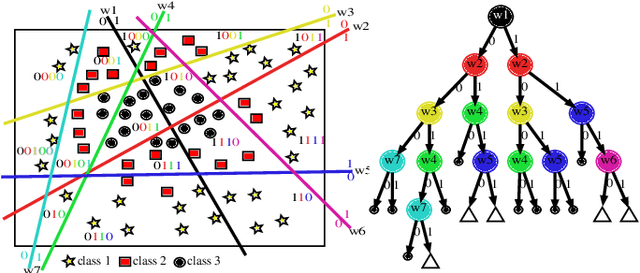
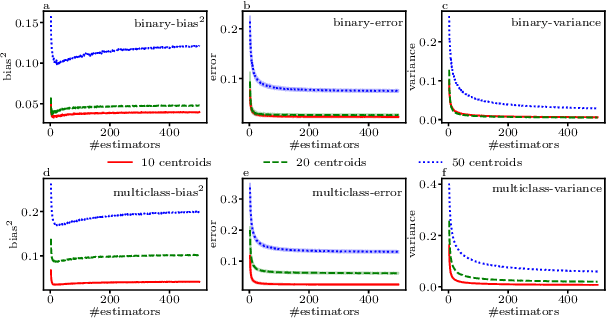
We present a new way of constructing an ensemble classifier, named the Guided Random Forest (GRAF) in the sequel. GRAF extends the idea of building oblique decision trees with localized partitioning to obtain a global partitioning. We show that global partitioning bridges the gap between decision trees and boosting algorithms. We empirically demonstrate that global partitioning reduces the generalization error bound. Results on 115 benchmark datasets show that GRAF yields comparable or better results on a majority of datasets. We also present a new way of approximating the datasets in the framework of random forests.