 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRESTomics: Analyzing Carotid Plaques in the CREST-2 Trial with a New Additive Classification Model
Mar 04, 2026Accurate characterization of carotid plaques is critical for stroke prevention in patients with carotid stenosis. We analyze 500 plaques from CREST-2, a multi-center clinical trial, to identify radiomics-based markers from B-mode ultrasound images linked with high-risk. We propose a new kernel-based additive model, combining coherence loss with group-sparse regularization for nonlinear classification. Group-wise additive effects of each feature group are visualized using partial dependence plots. Results indicate our method accurately and interpretably assesses plaques, revealing a strong association between plaque texture and clinical risk.
X-Mark: Saliency-Guided Robust Dataset Ownership Verification for Medical Imaging
Feb 10, 2026High-quality medical imaging datasets are essential for training deep learning models, but their unauthorized use raises serious copyright and ethical concerns. Medical imaging presents a unique challenge for existing dataset ownership verification methods designed for natural images, as static watermark patterns generated in fixed-scale images scale poorly dynamic and high-resolution scans with limited visual diversity and subtle anatomical structures, while preserving diagnostic quality. In this paper, we propose X-Mark, a sample-specific clean-label watermarking method for chest x-ray copyright protection. Specifically, X-Mark uses a conditional U-Net to generate unique perturbations within salient regions of each sample. We design a multi-component training objective to ensure watermark efficacy, robustness against dynamic scaling processes while preserving diagnostic quality and visual-distinguishability. We incorporate Laplacian regularization into our training objective to penalize high-frequency perturbations and achieve watermark scale-invariance. Ownership verification is performed in a black-box setting to detect characteristic behaviors in suspicious models. Extensive experiments on CheXpert verify the effectiveness of X-Mark, achieving WSR of 100% and reducing probability of false positives in Ind-M scenario by 12%, while demonstrating resistance to potential adaptive attacks.
Expanding the Horizon: Enabling Hybrid Quantum Transfer Learning for Long-Tailed Chest X-Ray Classification
Apr 30, 2024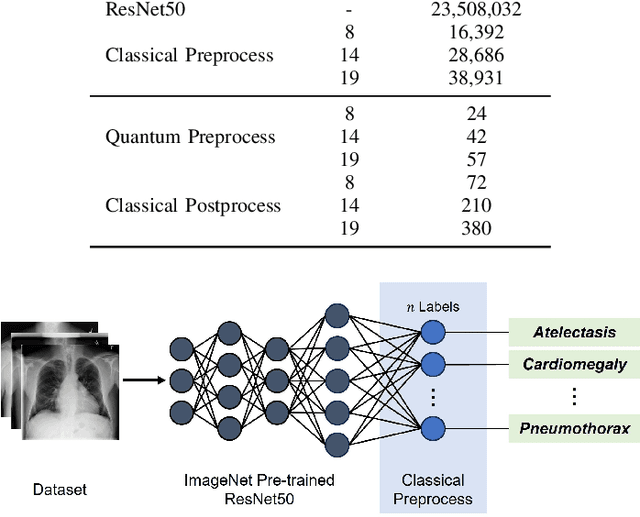
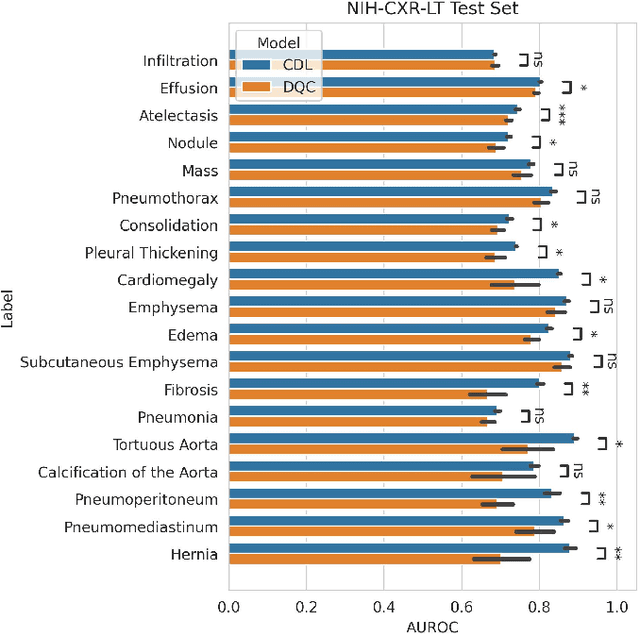
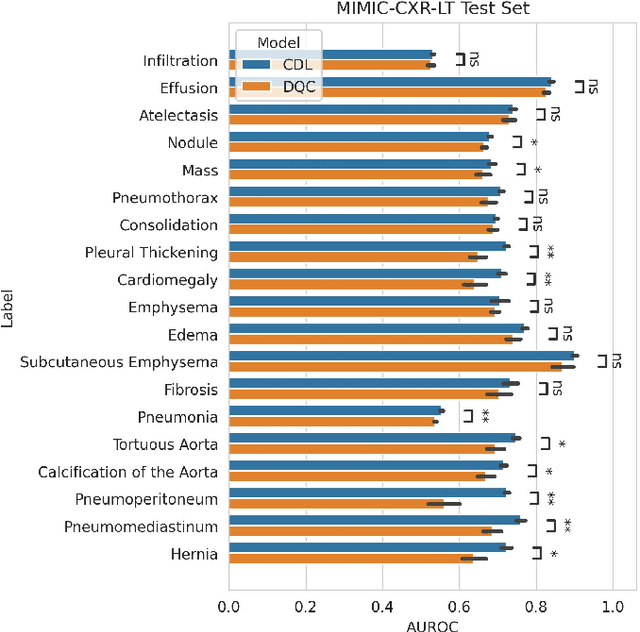
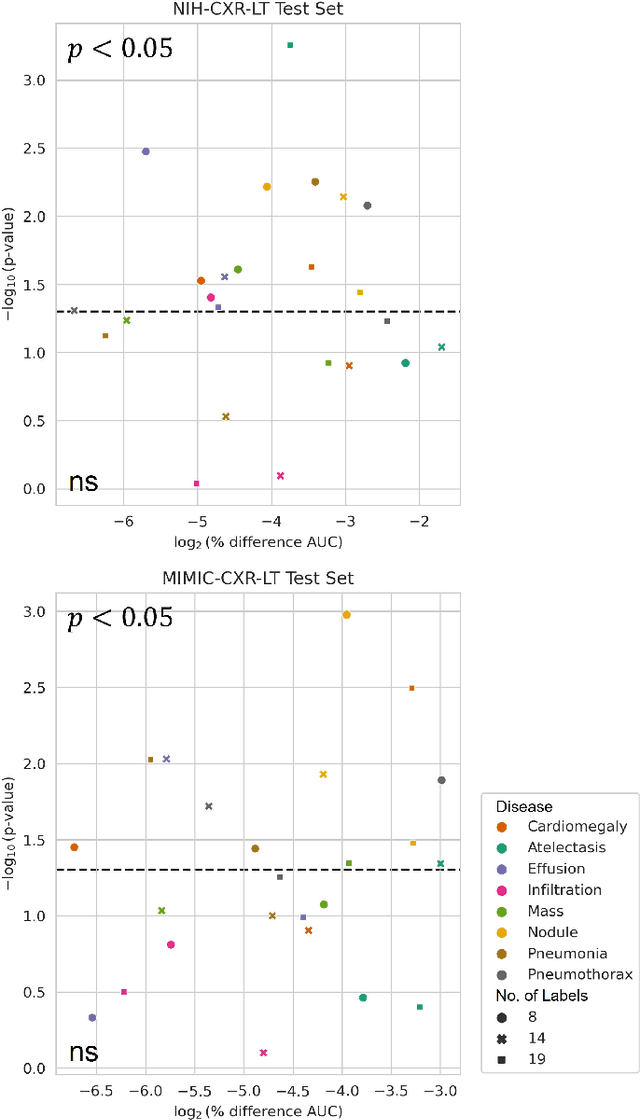
Quantum machine learning (QML) has the potential for improving the multi-label classification of rare, albeit critical, diseases in large-scale chest x-ray (CXR) datasets due to theoretical quantum advantages over classical machine learning (CML) in sample efficiency and generalizability. While prior literature has explored QML with CXRs, it has focused on binary classification tasks with small datasets due to limited access to quantum hardware and computationally expensive simulations. To that end, we implemented a Jax-based framework that enables the simulation of medium-sized qubit architectures with significant improvements in wall-clock time over current software offerings. We evaluated the performance of our Jax-based framework in terms of efficiency and performance for hybrid quantum transfer learning for long-tailed classification across 8, 14, and 19 disease labels using large-scale CXR datasets. The Jax-based framework resulted in up to a 58% and 95% speed-up compared to PyTorch and TensorFlow implementations, respectively. However, compared to CML, QML demonstrated slower convergence and an average AUROC of 0.70, 0.73, and 0.74 for the classification of 8, 14, and 19 CXR disease labels. In comparison, the CML models had an average AUROC of 0.77, 0.78, and 0.80 respectively. In conclusion, our work presents an accessible implementation of hybrid quantum transfer learning for long-tailed CXR classification with a computationally efficient Jax-based framework.
Improving Multi-Center Generalizability of GAN-Based Fat Suppression using Federated Learning
Apr 10, 2024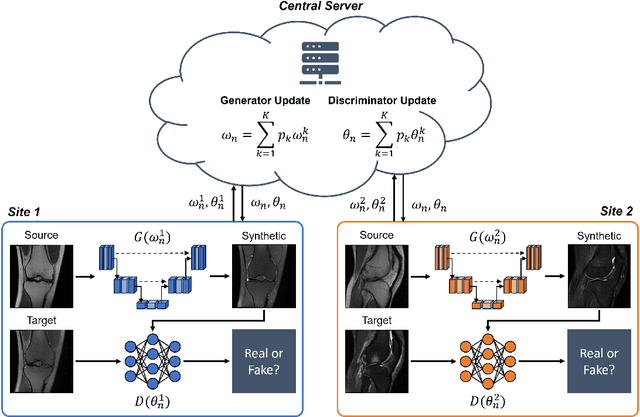
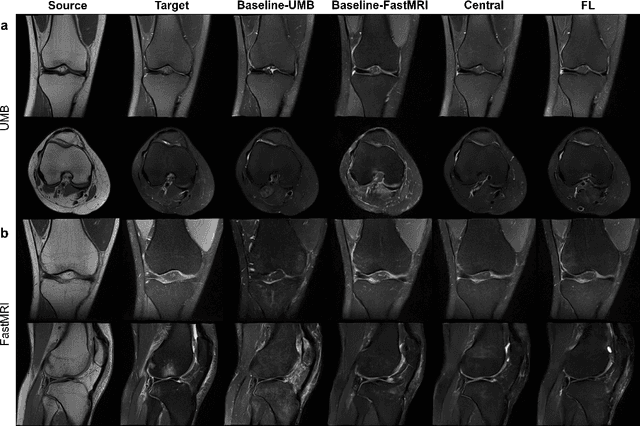
Generative Adversarial Network (GAN)-based synthesis of fat suppressed (FS) MRIs from non-FS proton density sequences has the potential to accelerate acquisition of knee MRIs. However, GANs trained on single-site data have poor generalizability to external data. We show that federated learning can improve multi-center generalizability of GANs for synthesizing FS MRIs, while facilitating privacy-preserving multi-institutional collaborations.
Anytime, Anywhere, Anyone: Investigating the Feasibility of Segment Anything Model for Crowd-Sourcing Medical Image Annotations
Mar 22, 2024Curating annotations for medical image segmentation is a labor-intensive and time-consuming task that requires domain expertise, resulting in "narrowly" focused deep learning (DL) models with limited translational utility. Recently, foundation models like the Segment Anything Model (SAM) have revolutionized semantic segmentation with exceptional zero-shot generalizability across various domains, including medical imaging, and hold a lot of promise for streamlining the annotation process. However, SAM has yet to be evaluated in a crowd-sourced setting to curate annotations for training 3D DL segmentation models. In this work, we explore the potential of SAM for crowd-sourcing "sparse" annotations from non-experts to generate "dense" segmentation masks for training 3D nnU-Net models, a state-of-the-art DL segmentation model. Our results indicate that while SAM-generated annotations exhibit high mean Dice scores compared to ground-truth annotations, nnU-Net models trained on SAM-generated annotations perform significantly worse than nnU-Net models trained on ground-truth annotations ($p<0.001$, all).
Hidden in Plain Sight: Undetectable Adversarial Bias Attacks on Vulnerable Patient Populations
Feb 08, 2024The proliferation of artificial intelligence (AI) in radiology has shed light on the risk of deep learning (DL) models exacerbating clinical biases towards vulnerable patient populations. While prior literature has focused on quantifying biases exhibited by trained DL models, demographically targeted adversarial bias attacks on DL models and its implication in the clinical environment remains an underexplored field of research in medical imaging. In this work, we demonstrate that demographically targeted label poisoning attacks can introduce adversarial underdiagnosis bias in DL models and degrade performance on underrepresented groups without impacting overall model performance. Moreover, our results across multiple performance metrics and demographic groups like sex, age, and their intersectional subgroups indicate that a group's vulnerability to undetectable adversarial bias attacks is directly correlated with its representation in the model's training data.
One Copy Is All You Need: Resource-Efficient Streaming of Medical Imaging Data at Scale
Jul 01, 2023Large-scale medical imaging datasets have accelerated development of artificial intelligence tools for clinical decision support. However, the large size of these datasets is a bottleneck for users with limited storage and bandwidth. Many users may not even require such large datasets as AI models are often trained on lower resolution images. If users could directly download at their desired resolution, storage and bandwidth requirements would significantly decrease. However, it is impossible to anticipate every users' requirements and impractical to store the data at multiple resolutions. What if we could store images at a single resolution but send them at different ones? We propose MIST, an open-source framework to operationalize progressive resolution for streaming medical images at multiple resolutions from a single high-resolution copy. We demonstrate that MIST can dramatically reduce imaging infrastructure inefficiencies for hosting and streaming medical images by >90%, while maintaining diagnostic quality for deep learning applications.
High-Throughput AI Inference for Medical Image Classification and Segmentation using Intelligent Streaming
May 24, 2023As the adoption of AI systems within the clinical setup grows, limitations in bandwidth could create communication bottlenecks when streaming imaging data, leading to delays in patient diagnosis and treatment. As such, healthcare providers and AI vendors will require greater computational infrastructure, therefore dramatically increasing costs. To that end, we developed intelligent streaming, a state-of-the-art framework to enable accelerated, cost-effective, bandwidth-optimized, and computationally efficient AI inference for clinical decision making at scale. For classification, intelligent streaming reduced the data transmission by 99.01% and decoding time by 98.58%, while increasing throughput by 27.43x. For segmentation, our framework reduced data transmission by 90.32%, decoding time by 90.26%, while increasing throughput by 4.20x. Our work demonstrates that intelligent streaming results in faster turnaround times, and reduced overall cost of data and transmission, without negatively impacting clinical decision making using AI systems.
Text2Cohort: Democratizing the NCI Imaging Data Commons with Natural Language Cohort Discovery
May 16, 2023The Imaging Data Commons (IDC) is a cloud-based database that provides researchers with open access to cancer imaging data, with the goal of facilitating collaboration in medical imaging research. However, querying the IDC database for cohort discovery and access to imaging data has a significant learning curve for researchers due to its complex nature. We developed Text2Cohort, a large language model (LLM) based toolkit to facilitate user-friendly and intuitive natural language cohort discovery in the IDC. Text2Cohorts translates user input into IDC database queries using prompt engineering and autocorrection and returns the query's response to the user. Autocorrection resolves errors in queries by passing the errors back to the model for interpretation and correction. We evaluate Text2Cohort on 50 natural language user inputs ranging from information extraction to cohort discovery. The resulting queries and outputs were verified by two computer scientists to measure Text2Cohort's accuracy and F1 score. Text2Cohort successfully generated queries and their responses with an 88% accuracy and F1 score of 0.94. However, it failed to generate queries for 6/50 (12%) user inputs due to syntax and semantic errors. Our results indicate that Text2Cohort succeeded at generating queries with correct responses, but occasionally failed due to a lack of understanding of the data schema. Despite these shortcomings, Text2Cohort demonstrates the utility of LLMs to enable researchers to discover and curate cohorts using data hosted on IDC with high levels of accuracy using natural language in a more intuitive and user-friendly way.
Optimizing Federated Learning for Medical Image Classification on Distributed Non-iid Datasets with Partial Labels
Mar 10, 2023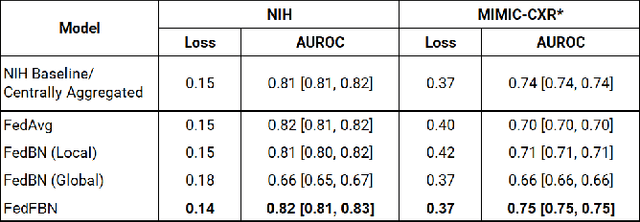
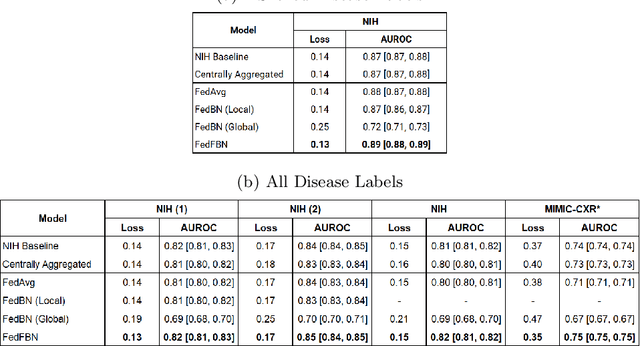
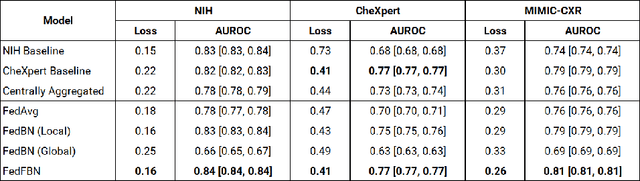
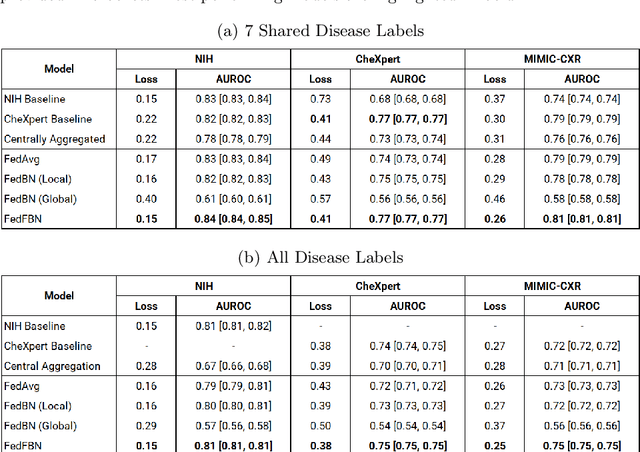
Numerous large-scale chest x-ray datasets have spearheaded expert-level detection of abnormalities using deep learning. However, these datasets focus on detecting a subset of disease labels that could be present, thus making them distributed and non-iid with partial labels. Recent literature has indicated the impact of batch normalization layers on the convergence of federated learning due to domain shift associated with non-iid data with partial labels. To that end, we propose FedFBN, a federated learning framework that draws inspiration from transfer learning by using pretrained networks as the model backend and freezing the batch normalization layers throughout the training process. We evaluate FedFBN with current FL strategies using synthetic iid toy datasets and large-scale non-iid datasets across scenarios with partial and complete labels. Our results demonstrate that FedFBN outperforms current aggregation strategies for training global models using distributed and non-iid data with partial labels.