 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutotelic Reinforcement Learning: Exploring Intrinsic Motivations for Skill Acquisition in Open-Ended Environments
Feb 06, 2025This paper presents a comprehensive overview of autotelic Reinforcement Learning (RL), emphasizing the role of intrinsic motivations in the open-ended formation of skill repertoires. We delineate the distinctions between knowledge-based and competence-based intrinsic motivations, illustrating how these concepts inform the development of autonomous agents capable of generating and pursuing self-defined goals. The typology of Intrinsically Motivated Goal Exploration Processes (IMGEPs) is explored, with a focus on the implications for multi-goal RL and developmental robotics. The autotelic learning problem is framed within a reward-free Markov Decision Process (MDP), WHERE agents must autonomously represent, generate, and master their own goals. We address the unique challenges in evaluating such agents, proposing various metrics for measuring exploration, generalization, and robustness in complex environments. This work aims to advance the understanding of autotelic RL agents and their potential for enhancing skill acquisition in a diverse and dynamic setting.
* 12 pages, 12 figures
Probabilistic Precipitation Downscaling with Optical Flow-Guided Diffusion
Dec 11, 2023In climate science and meteorology, local precipitation predictions are limited by the immense computational costs induced by the high spatial resolution that simulation methods require. A common workaround is statistical downscaling (aka superresolution), where a low-resolution prediction is super-resolved using statistical approaches. While traditional computer vision tasks mainly focus on human perception or mean squared error, applications in weather and climate require capturing the conditional distribution of high-resolution patterns given low-resolution patterns so that reliable ensemble averages can be taken. Our approach relies on extending recent video diffusion models to precipitation superresolution: an optical flow on the high-resolution output induces temporally coherent predictions, whereas a temporally-conditioned diffusion model generates residuals that capture the correct noise characteristics and high-frequency patterns. We test our approach on X-SHiELD, an established large-scale climate simulation dataset, and compare against two state-of-the-art baselines, focusing on CRPS, MSE, precipitation distributions, as well as an illustrative case -- the complex terrain of California. Our approach sets a new standard for data-driven precipitation downscaling.
Diffusion Probabilistic Modeling for Video Generation
Mar 31, 2022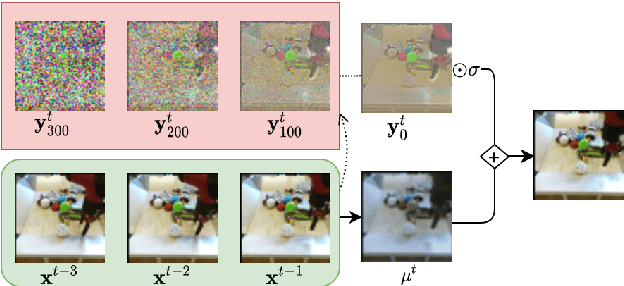
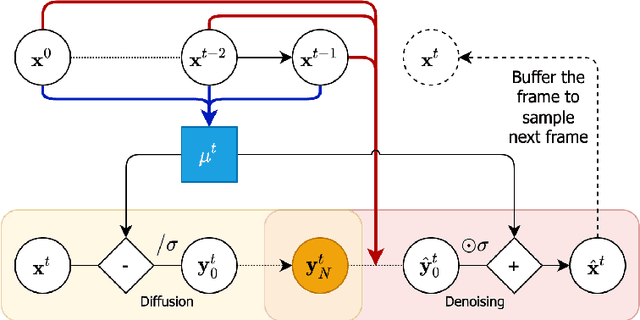

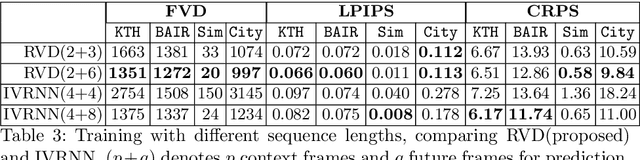
Denoising diffusion probabilistic models are a promising new class of generative models that are competitive with GANs on perceptual metrics. In this paper, we explore their potential for sequentially generating video. Inspired by recent advances in neural video compression, we use denoising diffusion models to stochastically generate a residual to a deterministic next-frame prediction. We compare this approach to two sequential VAE and two GAN baselines on four datasets, where we test the generated frames for perceptual quality and forecasting accuracy against ground truth frames. We find significant improvements in terms of perceptual quality on all data and improvements in terms of frame forecasting for complex high-resolution videos.