Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Probabilistic Modeling for Video Generation
Paper and Code
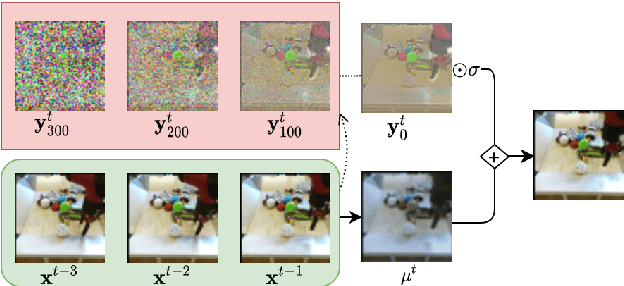
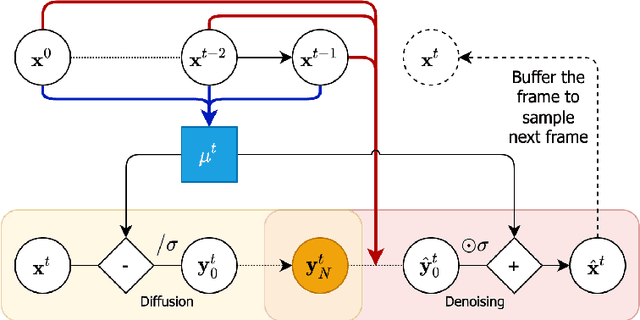

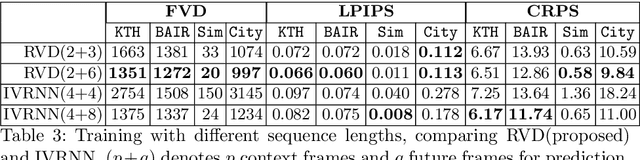
Denoising diffusion probabilistic models are a promising new class of generative models that are competitive with GANs on perceptual metrics. In this paper, we explore their potential for sequentially generating video. Inspired by recent advances in neural video compression, we use denoising diffusion models to stochastically generate a residual to a deterministic next-frame prediction. We compare this approach to two sequential VAE and two GAN baselines on four datasets, where we test the generated frames for perceptual quality and forecasting accuracy against ground truth frames. We find significant improvements in terms of perceptual quality on all data and improvements in terms of frame forecasting for complex high-resolution videos.
View paper on