 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP or DP? Why Not Both: A Case Study in the Partial Shop Scheduling Problem
May 22, 2026Dynamic Programming (DP) and Constraint Programming (CP) are well-established paradigms for solving combinatorial optimization problems. Usually, these two approaches are used separately. This paper aims to show that the two can be combined effectively and elegantly, with DP serving as the primary search framework and CP used as a subroutine to leverage global constraint propagation. This paper presents such an approach for the Partial Shop Scheduling Problem (PSSP), for which a pure DP method has previously been proposed, and efficient CP filtering algorithms are available. The PSSP is a general scheduling problem where each job consists of a set of operations with arbitrary precedence constraints. The approach is flexible enough to accommodate anytime DP strategies, such as anytime column search, whereas the original DP algorithm operated in a strictly layer-wise manner. Moreover, the flexibility of the CP modeling makes it straightforward to incorporate arbitrary precedence constraints. As a result, the model naturally handles any precedence graph and even enables the design of a Large Neighborhood Search (LNS) scheme, in which the DP model is reused, and partial-order schedules are imposed across restarts to improve the incumbent solution. While not competitive with state-of-the-art pure CP solvers for this specific problem, our primary contribution is demonstrating the viability of this hybrid integration.
Solving the Aircraft Disassembly Scheduling Problem
May 22, 2026Dismantling aircrafts reaching their end of life is a complex endeavour that is necessary in terms of sustainability but yields small income margins for air transport companies. An efficient scheduling of the disassembly procedure is thus crucial to ensure the profitability of the process and incentivize practice. This is a large scheduling problem that involves thousands of tasks and many different constraints: Extracting parts that are destined to be reused requires technicians with specific certifications and equipment. Extraction operations might be subject to precedence relations. Furthermore, the aircraft must be kept balanced during the whole process. Finally, some of the locations of the aircraft have a limited space that caps the number of technicians able to work there concurrently. This article presents the problem in details and proposes two approaches to solve the problem: a Constraint Programming model and a MIP model. The models are tested on instances of varying sizes involving up to 1450 tasks, which are based on real operational data provided by an industrial partner.
Anytime Optimal Decision Tree Learning with Continuous Features
Jan 21, 2026In recent years, significant progress has been made on algorithms for learning optimal decision trees, primarily in the context of binary features. Extending these methods to continuous features remains substantially more challenging due to the large number of potential splits for each feature. Recently, an elegant exact algorithm was proposed for learning optimal decision trees with continuous features; however, the rapidly increasing computational time limits its practical applicability to shallow depths (typically 3 or 4). It relies on a depth-first search optimization strategy that fully optimizes the left subtree of each split before exploring the corresponding right subtree. While effective in finding optimal solutions given sufficient time, this strategy can lead to poor anytime behavior: when interrupted early, the best-found tree is often highly unbalanced and suboptimal. In such cases, purely greedy methods such as C4.5 may, paradoxically, yield better solutions. To address this limitation, we propose an anytime, yet complete approach leveraging limited discrepancy search, distributing the computational effort more evenly across the entire tree structure, and thus ensuring that a high-quality decision tree is available at any interruption point. Experimental results show that our approach outperforms the existing one in terms of anytime performance.
Towards Bound Consistency for the No-Overlap Constraint Using MDDs
Jan 21, 2026Achieving bound consistency for the no-overlap constraint is known to be NP-complete. Therefore, several polynomial-time tightening techniques, such as edge finding, not-first-not-last reasoning, and energetic reasoning, have been introduced for this constraint. In this work, we derive the first bound-consistent algorithm for the no-overlap constraint. By building on the no-overlap MDD defined by Ciré and van Hoeve, we extract bounds of the time window of the jobs, allowing us to tighten start and end times in time polynomial in the number of nodes of the MDD. Similarly, to bound the size and time-complexity, we limit the width of the MDD to a threshold, creating a relaxed MDD that can also be used to relax the bound-consistent filtering. Through experiments on a sequencing problem with time windows and a just-in-time objective ($1 \mid r_j, d_j, \bar{d}_j \mid \sum E_j + \sum T_j$), we observe that the proposed filtering, even with a threshold on the width, achieves a stronger reduction in the number of nodes visited in the search tree compared to the previously proposed precedence-detection algorithm of Ciré and van Hoeve. The new filtering also appears to be complementary to classical propagation methods for the no-overlap constraint, allowing a substantial reduction in both the number of nodes and the solving time on several instances.
Sequence Variables: A Constraint Programming Computational Domain for Routing and Sequencing
Oct 10, 2025Constraint Programming (CP) offers an intuitive, declarative framework for modeling Vehicle Routing Problems (VRP), yet classical CP models based on successor variables cannot always deal with optional visits or insertion based heuristics. To address these limitations, this paper formalizes sequence variables within CP. Unlike the classical successor models, this computational domain handle optional visits and support insertion heuristics, including insertion-based Large Neighborhood Search. We provide a clear definition of their domain, update operations, and introduce consistency levels for constraints on this domain. An implementation is described with the underlying data structures required for integrating sequence variables into existing trail-based CP solvers. Furthermore, global constraints specifically designed for sequence variables and vehicle routing are introduced. Finally, the effectiveness of sequence variables is demonstrated by simplifying problem modeling and achieving competitive computational performance on the Dial-a-Ride Problem.
CP-Model-Zoo: A Natural Language Query System for Constraint Programming Models
Sep 09, 2025Constraint Programming and its high-level modeling languages have long been recognized for their potential to achieve the holy grail of problem-solving. However, the complexity of modeling languages, the large number of global constraints, and the art of creating good models have often hindered non-experts from choosing CP to solve their combinatorial problems. While generating an expert-level model from a natural-language description of a problem would be the dream, we are not yet there. We propose a tutoring system called CP-Model-Zoo, exploiting expert-written models accumulated through the years. CP-Model-Zoo retrieves the closest source code model from a database based on a user's natural language description of a combinatorial problem. It ensures that expert-validated models are presented to the user while eliminating the need for human data labeling. Our experiments show excellent accuracy in retrieving the correct model based on a user-input description of a problem simulated with different levels of expertise.
A Generic Complete Anytime Beam Search for Optimal Decision Tree
Aug 08, 2025Finding an optimal decision tree that minimizes classification error is known to be NP-hard. While exact algorithms based on MILP, CP, SAT, or dynamic programming guarantee optimality, they often suffer from poor anytime behavior -- meaning they struggle to find high-quality decision trees quickly when the search is stopped before completion -- due to unbalanced search space exploration. To address this, several anytime extensions of exact methods have been proposed, such as LDS-DL8.5, Top-k-DL8.5, and Blossom, but they have not been systematically compared, making it difficult to assess their relative effectiveness. In this paper, we propose CA-DL8.5, a generic, complete, and anytime beam search algorithm that extends the DL8.5 framework and unifies some existing anytime strategies. In particular, CA-DL8.5 generalizes previous approaches LDS-DL8.5 and Top-k-DL8.5, by allowing the integration of various heuristics and relaxation mechanisms through a modular design. The algorithm reuses DL8.5's efficient branch-and-bound pruning and trie-based caching, combined with a restart-based beam search that gradually relaxes pruning criteria to improve solution quality over time. Our contributions are twofold: (1) We introduce this new generic framework for exact and anytime decision tree learning, enabling the incorporation of diverse heuristics and search strategies; (2) We conduct a rigorous empirical comparison of several instantiations of CA-DL8.5 -- based on Purity, Gain, Discrepancy, and Top-k heuristics -- using an anytime evaluation metric called the primal gap integral. Experimental results on standard classification benchmarks show that CA-DL8.5 using LDS (limited discrepancy) consistently provides the best anytime performance, outperforming both other CA-DL8.5 variants and the Blossom algorithm while maintaining completeness and optimality guarantees.
Branch-and-Bound with Barrier: Dominance and Suboptimality Detection for DD-Based Branch-and-Bound
Nov 22, 2022



The branch-and-bound algorithm based on decision diagrams introduced by Bergman et al. in 2016 is a framework for solving discrete optimization problems with a dynamic programming formulation. It works by compiling a series of bounded-width decision diagrams that can provide lower and upper bounds for any given subproblem. Eventually, every part of the search space will be either explored or pruned by the algorithm, thus proving optimality. This paper presents new ingredients to speed up the search by exploiting the structure of dynamic programming models. The key idea is to prevent the repeated exploration of nodes corresponding to the same dynamic programming states by storing and querying thresholds in a data structure called the Barrier. These thresholds are based on dominance relations between partial solutions previously found. They can be further strengthened by integrating the filtering techniques introduced by Gillard et al. in 2021. Computational experiments show that the pruning brought by the Barrier allows to significantly reduce the number of nodes expanded by the algorithm. This results in more benchmark instances of difficult optimization problems being solved in less time while using narrower decision diagrams.
Improving the filtering of Branch-And-Bound MDD solver
Apr 24, 2021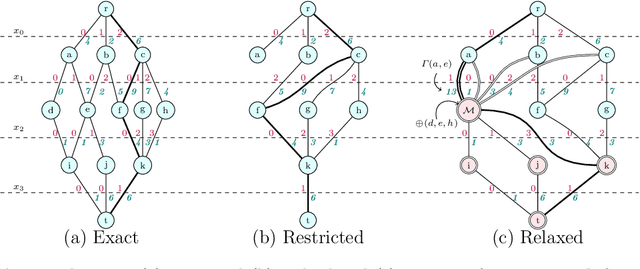
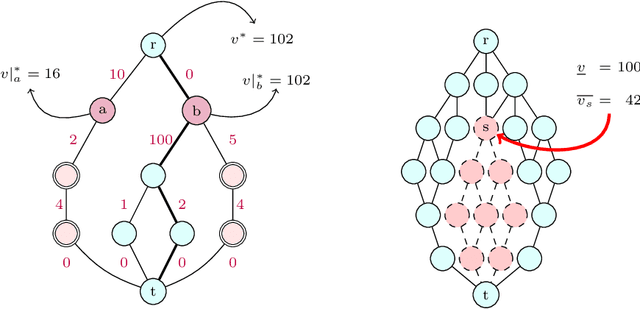
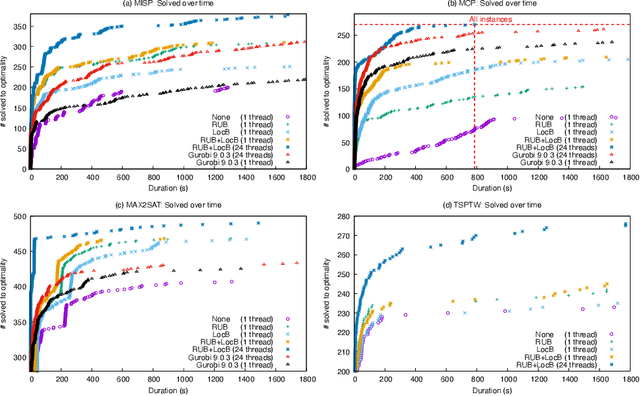
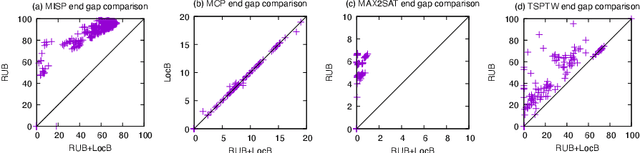
This paper presents and evaluates two pruning techniques to reinforce the efficiency of constraint optimization solvers based on multi-valued decision-diagrams (MDD). It adopts the branch-and-bound framework proposed by Bergman et al. in 2016 to solve dynamic programs to optimality. In particular, our paper presents and evaluates the effectiveness of the local-bound (LocB) and rough upper-bound pruning (RUB). LocB is a new and effective rule that leverages the approximate MDD structure to avoid the exploration of non-interesting nodes. RUB is a rule to reduce the search space during the development of bounded-width-MDDs. The experimental study we conducted on the Maximum Independent Set Problem (MISP), Maximum Cut Problem (MCP), Maximum 2 Satisfiability (MAX2SAT) and the Traveling Salesman Problem with Time Windows (TSPTW) shows evidence indicating that rough-upper-bound and local-bound pruning have a high impact on optimization solvers based on branch-and-bound with MDDs. In particular, it shows that RUB delivers excellent results but requires some effort when defining the model. Also, it shows that LocB provides a significant improvement automatically; without necessitating any user-supplied information. Finally, it also shows that rough-upper-bound and local-bound pruning are not mutually exclusive, and their combined benefit supersedes the individual benefit of using each technique.
Impact of weather factors on migration intention using machine learning algorithms
Dec 04, 2020
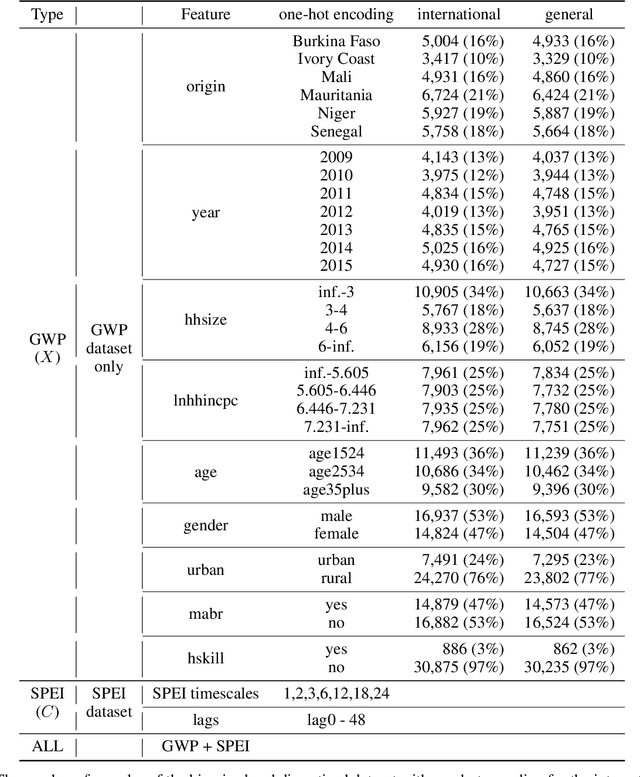
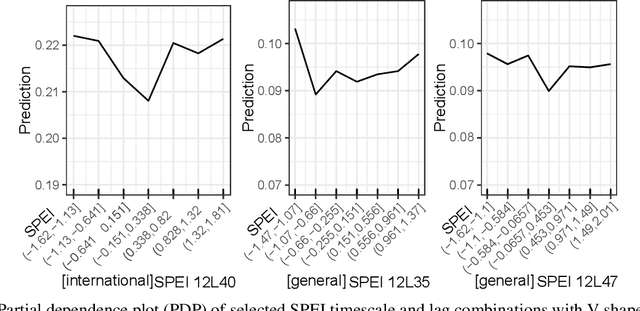

A growing attention in the empirical literature has been paid to the incidence of climate shocks and change in migration decisions. Previous literature leads to different results and uses a multitude of traditional empirical approaches. This paper proposes a tree-based Machine Learning (ML) approach to analyze the role of the weather shocks towards an individual's intention to migrate in the six agriculture-dependent-economy countries such as Burkina Faso, Ivory Coast, Mali, Mauritania, Niger, and Senegal. We perform several tree-based algorithms (e.g., XGB, Random Forest) using the train-validation-test workflow to build robust and noise-resistant approaches. Then we determine the important features showing in which direction they are influencing the migration intention. This ML-based estimation accounts for features such as weather shocks captured by the Standardized Precipitation-Evapotranspiration Index (SPEI) for different timescales and various socioeconomic features/covariates. We find that (i) weather features improve the prediction performance although socioeconomic characteristics have more influence on migration intentions, (ii) country-specific model is necessary, and (iii) international move is influenced more by the longer timescales of SPEIs while general move (which includes internal move) by that of shorter timescales.