 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Points and Convergence Analysis of Generative Deep Linear Networks Trained with Bures-Wasserstein Loss
Mar 06, 2023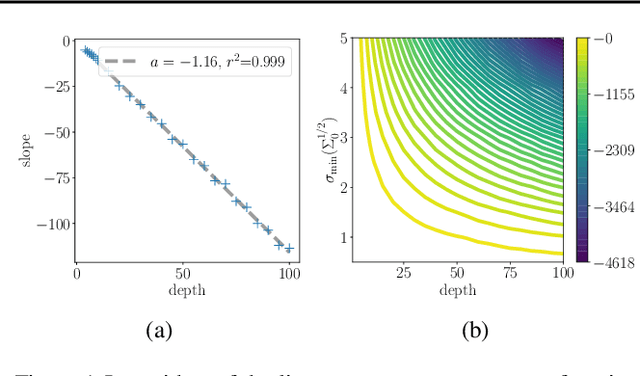



We consider a deep matrix factorization model of covariance matrices trained with the Bures-Wasserstein distance. While recent works have made important advances in the study of the optimization problem for overparametrized low-rank matrix approximation, much emphasis has been placed on discriminative settings and the square loss. In contrast, our model considers another interesting type of loss and connects with the generative setting. We characterize the critical points and minimizers of the Bures-Wasserstein distance over the space of rank-bounded matrices. For low-rank matrices the Hessian of this loss can theoretically blow up, which creates challenges to analyze convergence of optimizaton methods. We establish convergence results for gradient flow using a smooth perturbative version of the loss and convergence results for finite step size gradient descent under certain assumptions on the initial weights.
Informative GANs via Structured Regularization of Optimal Transport
Dec 04, 2019
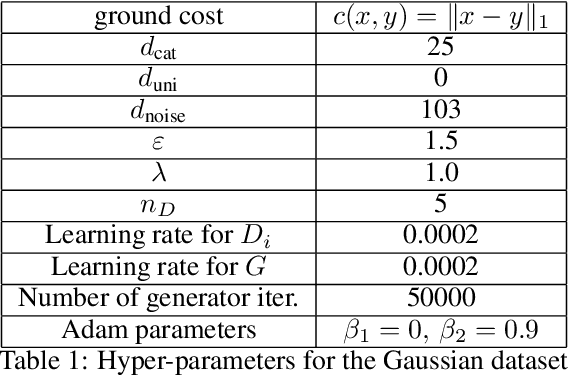


We tackle the challenge of disentangled representation learning in generative adversarial networks (GANs) from the perspective of regularized optimal transport (OT). Specifically, a smoothed OT loss gives rise to an implicit transportation plan between the latent space and the data space. Based on this theoretical observation, we exploit a structured regularization on the transportation plan to encourage a prescribed latent subspace to be informative. This yields the formulation of a novel informative OT-based GAN. By convex duality, we obtain the equivalent view that this leads to perturbed ground costs favoring sparsity in the informative latent dimensions. Practically, we devise a stable training algorithm for the proposed informative GAN. Our experiments support the hypothesis that such regularizations effectively yield the discovery of disentangled and interpretable latent representations. Our work showcases potential power of a regularized OT framework in the context of generative modeling through its access to the transport plan. Further challenges are addressed in this line.