 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Conceptual Understanding in Multimodal Contrastive Learning through Hard Negative Samples
Mar 05, 2024Current multimodal models leveraging contrastive learning often face limitations in developing fine-grained conceptual understanding. This is due to random negative samples during pretraining, causing almost exclusively very dissimilar concepts to be compared in the loss function. Consequently, the models struggle with fine-grained semantic differences. To address this problem, we introduce a novel pretraining method incorporating synthetic hard negative text examples. The hard negatives permute terms corresponding to visual concepts, leading to a more fine-grained visual and textual concept alignment. Further, we introduce InpaintCOCO, a new challenging dataset for assessing the fine-grained alignment of colors, objects, and sizes in vision-language models. We created the dataset using generative inpainting from COCO images by changing the visual concepts so that the images no longer match their original captions. Our results show significant improvements in fine-grained concept understanding across a wide range of vision-language datasets, including our InpaintCOCO dataset.
dacl1k: Real-World Bridge Damage Dataset Putting Open-Source Data to the Test
Sep 07, 2023Recognising reinforced concrete defects (RCDs) is a crucial element for determining the structural integrity, traffic safety and durability of bridges. However, most of the existing datasets in the RCD domain are derived from a small number of bridges acquired in specific camera poses, lighting conditions and with fixed hardware. These limitations question the usability of models trained on such open-source data in real-world scenarios. We address this problem by testing such models on our "dacl1k" dataset, a highly diverse RCD dataset for multi-label classification based on building inspections including 1,474 images. Thereby, we trained the models on different combinations of open-source data (meta datasets) which were subsequently evaluated both extrinsically and intrinsically. During extrinsic evaluation, we report metrics on dacl1k and the meta datasets. The performance analysis on dacl1k shows practical usability of the meta data, where the best model shows an Exact Match Ratio of 32%. Additionally, we conduct an intrinsic evaluation by clustering the bottleneck features of the best model derived from the extrinsic evaluation in order to find out, if the model has learned distinguishing datasets or the classes (RCDs) which is the aspired goal. The dacl1k dataset and our trained models will be made publicly available, enabling researchers and practitioners to put their models to the real-world test.
dacl10k: Benchmark for Semantic Bridge Damage Segmentation
Sep 01, 2023
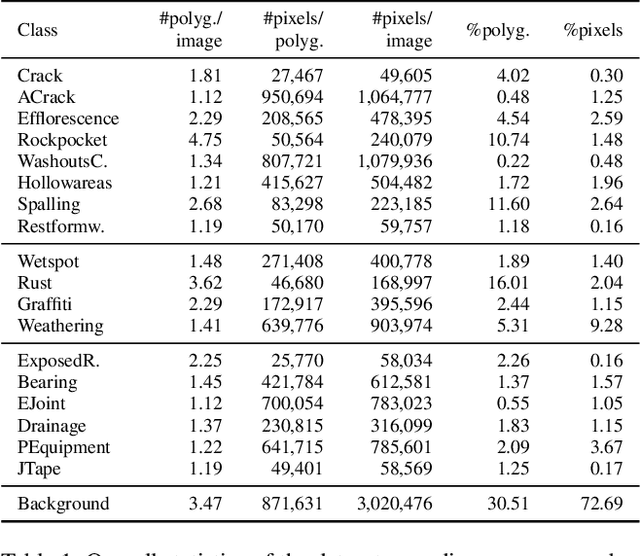
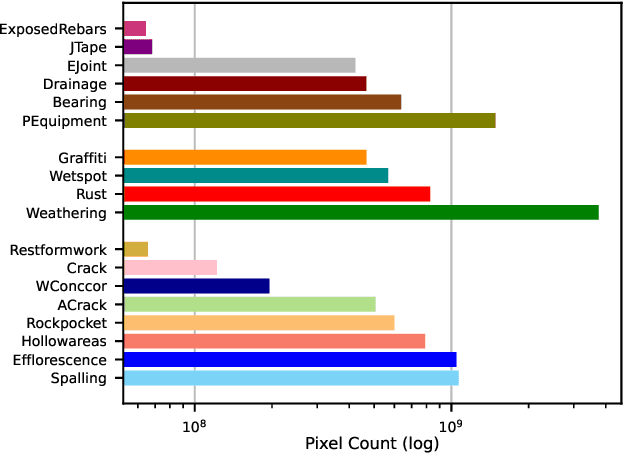
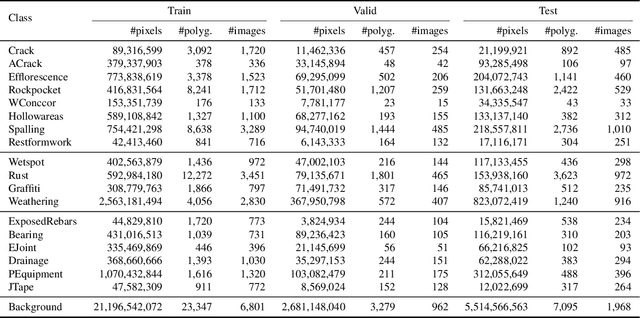
Reliably identifying reinforced concrete defects (RCDs)plays a crucial role in assessing the structural integrity, traffic safety, and long-term durability of concrete bridges, which represent the most common bridge type worldwide. Nevertheless, available datasets for the recognition of RCDs are small in terms of size and class variety, which questions their usability in real-world scenarios and their role as a benchmark. Our contribution to this problem is "dacl10k", an exceptionally diverse RCD dataset for multi-label semantic segmentation comprising 9,920 images deriving from real-world bridge inspections. dacl10k distinguishes 12 damage classes as well as 6 bridge components that play a key role in the building assessment and recommending actions, such as restoration works, traffic load limitations or bridge closures. In addition, we examine baseline models for dacl10k which are subsequently evaluated. The best model achieves a mean intersection-over-union of 0.42 on the test set. dacl10k, along with our baselines, will be openly accessible to researchers and practitioners, representing the currently biggest dataset regarding number of images and class diversity for semantic segmentation in the bridge inspection domain.
Probing the Role of Positional Information in Vision-Language Models
May 17, 2023In most Vision-Language models (VL), the understanding of the image structure is enabled by injecting the position information (PI) about objects in the image. In our case study of LXMERT, a state-of-the-art VL model, we probe the use of the PI in the representation and study its effect on Visual Question Answering. We show that the model is not capable of leveraging the PI for the image-text matching task on a challenge set where only position differs. Yet, our experiments with probing confirm that the PI is indeed present in the representation. We introduce two strategies to tackle this: (i) Positional Information Pre-training and (ii) Contrastive Learning on PI using Cross-Modality Matching. Doing so, the model can correctly classify if images with detailed PI statements match. Additionally to the 2D information from bounding boxes, we introduce the object's depth as new feature for a better object localization in the space. Even though we were able to improve the model properties as defined by our probes, it only has a negligible effect on the downstream performance. Our results thus highlight an important issue of multimodal modeling: the mere presence of information detectable by a probing classifier is not a guarantee that the information is available in a cross-modal setup.
Less Is More: Linear Layers on CLIP Features as Powerful VizWiz Model
Jun 10, 2022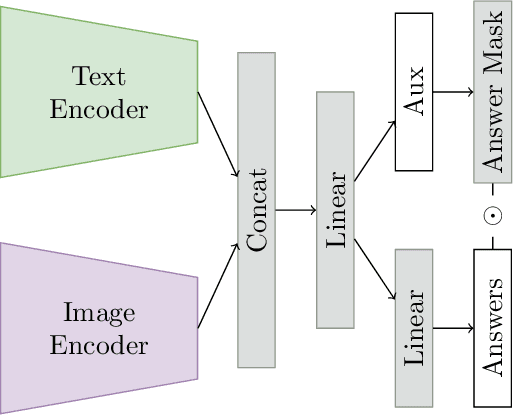
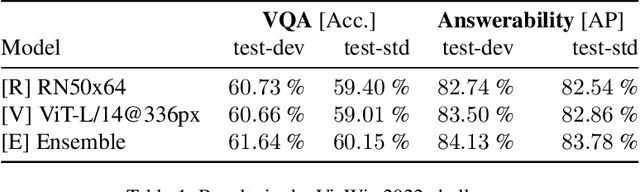
Current architectures for multi-modality tasks such as visual question answering suffer from their high complexity. As a result, these architectures are difficult to train and require high computational resources. To address these problems we present a CLIP-based architecture that does not require any fine-tuning of the feature extractors. A simple linear classifier is used on the concatenated features of the image and text encoder. During training an auxiliary loss is added which operates on the answer types. The resulting classification is then used as an attention gate on the answer class selection. On the VizWiz 2022 Visual Question Answering Challenge we achieve 60.15 % accuracy on Task 1: Predict Answer to a Visual Question and AP score of 83.78 % on Task 2: Predict Answerability of a Visual Question.
Building Inspection Toolkit: Unified Evaluation and Strong Baselines for Damage Recognition
Feb 14, 2022In recent years, several companies and researchers have started to tackle the problem of damage recognition within the scope of automated inspection of built structures. While companies are neither willing to publish associated data nor models, researchers are facing the problem of data shortage on one hand and inconsistent dataset splitting with the absence of consistent metrics on the other hand. This leads to incomparable results. Therefore, we introduce the building inspection toolkit -- bikit -- which acts as a simple to use data hub containing relevant open-source datasets in the field of damage recognition. The datasets are enriched with evaluation splits and predefined metrics, suiting the specific task and their data distribution. For the sake of compatibility and to motivate researchers in this domain, we also provide a leaderboard and the possibility to share model weights with the community. As starting point we provide strong baselines for multi-target classification tasks utilizing extensive hyperparameter search using three transfer learning approaches for state-of-the-art algorithms. The toolkit and the leaderboard are available online.