 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Is More: Linear Layers on CLIP Features as Powerful VizWiz Model
Paper and Code
Jun 10, 2022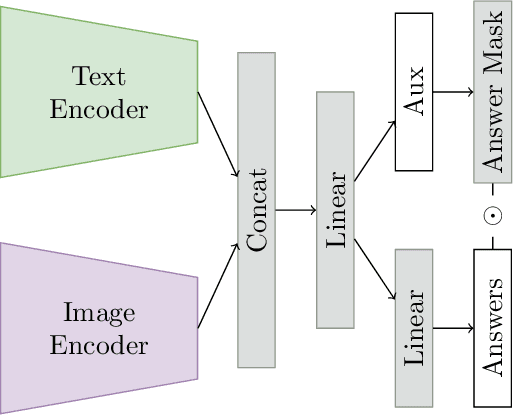
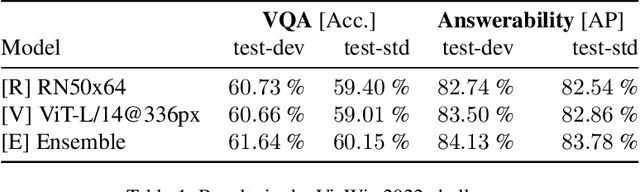
Current architectures for multi-modality tasks such as visual question answering suffer from their high complexity. As a result, these architectures are difficult to train and require high computational resources. To address these problems we present a CLIP-based architecture that does not require any fine-tuning of the feature extractors. A simple linear classifier is used on the concatenated features of the image and text encoder. During training an auxiliary loss is added which operates on the answer types. The resulting classification is then used as an attention gate on the answer class selection. On the VizWiz 2022 Visual Question Answering Challenge we achieve 60.15 % accuracy on Task 1: Predict Answer to a Visual Question and AP score of 83.78 % on Task 2: Predict Answerability of a Visual Question.