 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Polyp Segmentation Using Convolutional Neural Networks
Apr 22, 2020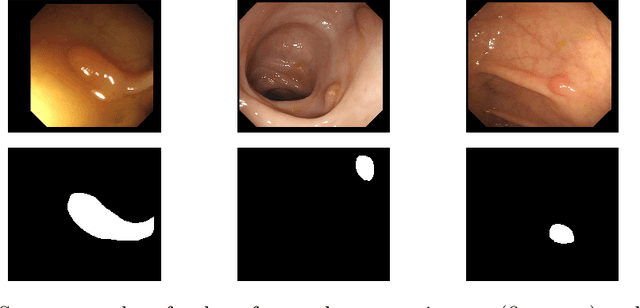



Colorectal cancer is the third most common cancer-related death after lung cancer and breast cancer worldwide. The risk of developing colorectal cancer could be reduced by early diagnosis of polyps during a colonoscopy. Computer-aided diagnosis systems have the potential to be applied for polyp screening and reduce the number of missing polyps. In this paper, we compare the performance of different deep learning architectures as feature extractors, i.e. ResNet, DenseNet, InceptionV3, InceptionResNetV2 and SE-ResNeXt in the encoder part of a U-Net architecture. We validated the performance of presented ensemble models on the CVC-Clinic (GIANA 2018) dataset. The DenseNet169 feature extractor combined with U-Net architecture outperformed the other counterparts and achieved an accuracy of 99.15\%, Dice similarity coefficient of 90.87%, and Jaccard index of 83.82%.
Causality based Feature Fusion for Brain Neuro-Developmental Analysis
Jan 22, 2020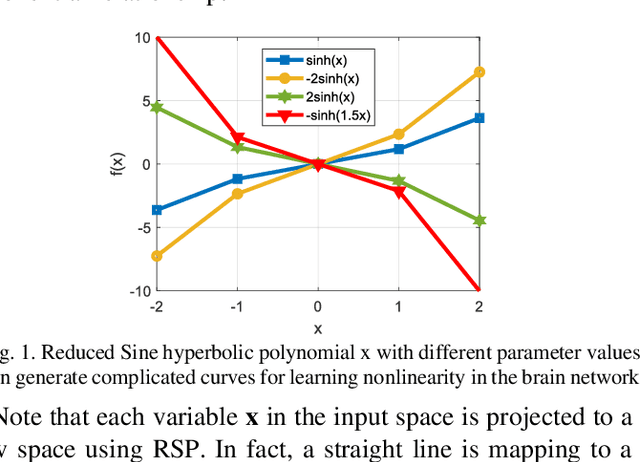
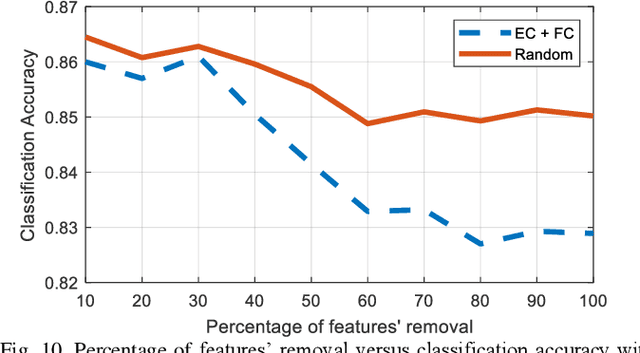
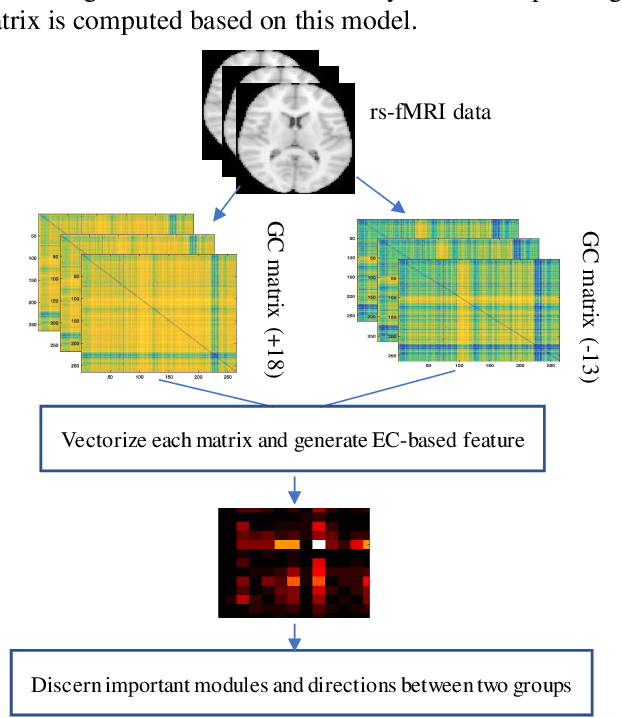
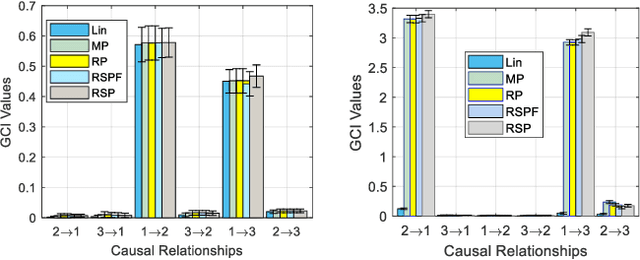
Human brain development is a complex and dynamic process that is affected by several factors such as genetics, sex hormones, and environmental changes. A number of recent studies on brain development have examined functional connectivity (FC) defined by the temporal correlation between time series of different brain regions. We propose to add the directional flow of information during brain maturation. To do so, we extract effective connectivity (EC) through Granger causality (GC) for two different groups of subjects, i.e., children and young adults. The motivation is that the inclusion of causal interaction may further discriminate brain connections between two age groups and help to discover new connections between brain regions. The contributions of this study are threefold. First, there has been a lack of attention to EC-based feature extraction in the context of brain development. To this end, we propose a new kernel-based GC (KGC) method to learn nonlinearity of complex brain network, where a reduced Sine hyperbolic polynomial (RSP) neural network was used as our proposed learner. Second, we used causality values as the weight for the directional connectivity between brain regions. Our findings indicated that the strength of connections was significantly higher in young adults relative to children. In addition, our new EC-based feature outperformed FC-based analysis from Philadelphia neurocohort (PNC) study with better discrimination of the different age groups. Moreover, the fusion of these two sets of features (FC + EC) improved brain age prediction accuracy by more than 4%, indicating that they should be used together for brain development studies.
Classification of Histopathological Biopsy Images Using Ensemble of Deep Learning Networks
Sep 26, 2019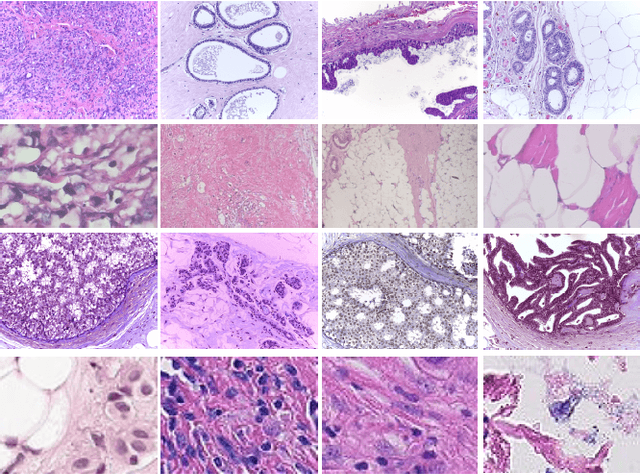


Breast cancer is one of the leading causes of death across the world in women. Early diagnosis of this type of cancer is critical for treatment and patient care. Computer-aided detection (CAD) systems using convolutional neural networks (CNN) could assist in the classification of abnormalities. In this study, we proposed an ensemble deep learning-based approach for automatic binary classification of breast histology images. The proposed ensemble model adapts three pre-trained CNNs, namely VGG19, MobileNet, and DenseNet. The ensemble model is used for the feature representation and extraction steps. The extracted features are then fed into a multi-layer perceptron classifier to carry out the classification task. Various pre-processing and CNN tuning techniques such as stain-normalization, data augmentation, hyperparameter tuning, and fine-tuning are used to train the model. The proposed method is validated on four publicly available benchmark datasets, i.e., ICIAR, BreakHis, PatchCamelyon, and Bioimaging. The proposed multi-model ensemble method obtains better predictions than single classifiers and machine learning algorithms with accuracies of 98.13%, 95.00%, 94.64% and 83.10% for BreakHis, ICIAR, PatchCamelyon and Bioimaging datasets, respectively.
Breast Cancer Diagnosis with Transfer Learning and Global Pooling
Sep 26, 2019
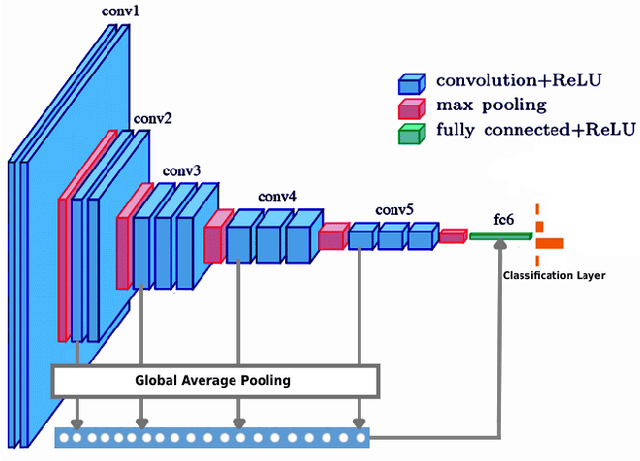
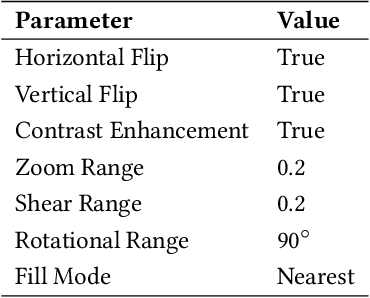
Breast cancer is one of the most common causes of cancer-related death in women worldwide. Early and accurate diagnosis of breast cancer may significantly increase the survival rate of patients. In this study, we aim to develop a fully automatic, deep learning-based, method using descriptor features extracted by Deep Convolutional Neural Network (DCNN) models and pooling operation for the classification of hematoxylin and eosin stain (H&E) histological breast cancer images provided as a part of the International Conference on Image Analysis and Recognition (ICIAR) 2018 Grand Challenge on BreAst Cancer Histology (BACH) Images. Different data augmentation methods are applied to optimize the DCNN performance. We also investigated the efficacy of different stain normalization methods as a pre-processing step. The proposed network architecture using a pre-trained Xception model yields 92.50% average classification accuracy.
k-Relevance Vectors for Pattern Classification
Sep 18, 2019

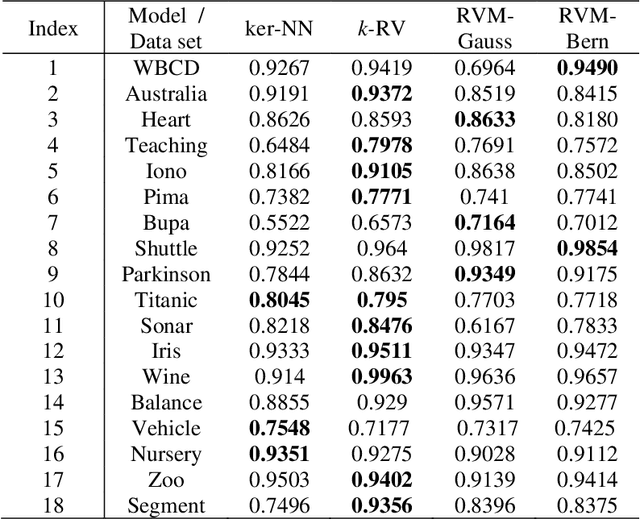
This study combines two different learning paradigms, k-nearest neighbor (k-NN) rule, as memory-based learning paradigm and relevance vector machines (RVM), as statistical learning paradigm. This combination is performed in kernel space and is called k-relevance vector (k-RV). The purpose is to improve the performance of k-NN rule. The proposed model significantly prunes irrelevant attributes. We also introduced a new parameter, responsible for early stopping of iterations in RVM. We show that the new parameter improves the classification accuracy of k-RV. Intensive experiments are conducted on several classification datasets from University of California Irvine (UCI) repository and two real datasets from computer vision domain. The performance of k-RV is highly competitive compared to a few state-of-the-arts in terms of classification accuracy.
Multimodal Sparse Classifier for Adolescent Brain Age Prediction
Apr 01, 2019
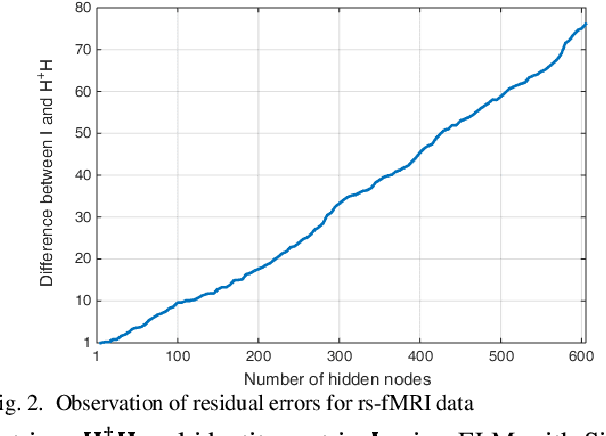
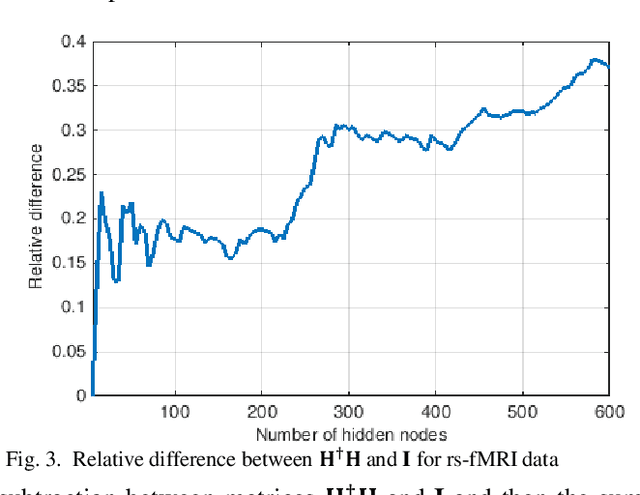
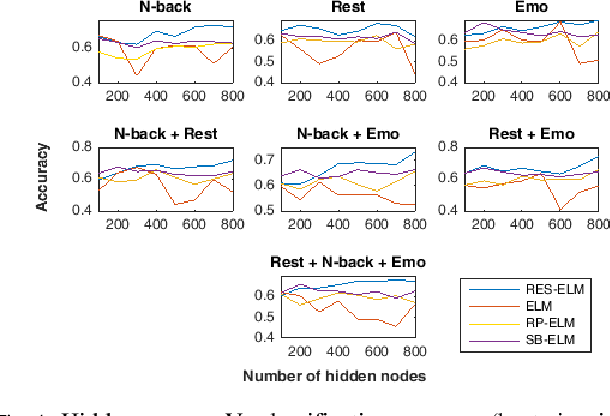
The study of healthy brain development helps to better understand the brain transformation and brain connectivity patterns which happen during childhood to adulthood. This study presents a sparse machine learning solution across whole-brain functional connectivity (FC) measures of three sets of data, derived from resting state functional magnetic resonance imaging (rs-fMRI) and task fMRI data, including a working memory n-back task (nb-fMRI) and an emotion identification task (em-fMRI). These multi-modal image data are collected on a sample of adolescents from the Philadelphia Neurodevelopmental Cohort (PNC) for the prediction of brain ages. Due to extremely large variable-to-instance ratio of PNC data, a high dimensional matrix with several irrelevant and highly correlated features is generated and hence a pattern learning approach is necessary to extract significant features. We propose a sparse learner based on the residual errors along the estimation of an inverse problem for the extreme learning machine (ELM) neural network. The purpose of the approach is to overcome the overlearning problem through pruning of several redundant features and their corresponding output weights. The proposed multimodal sparse ELM classifier based on residual errors (RES-ELM) is highly competitive in terms of the classification accuracy compared to its counterparts such as conventional ELM, and sparse Bayesian learning ELM.
Introducing a hybrid model of DEA and data mining in evaluating efficiency. Case study: Bank Branches
Oct 10, 2018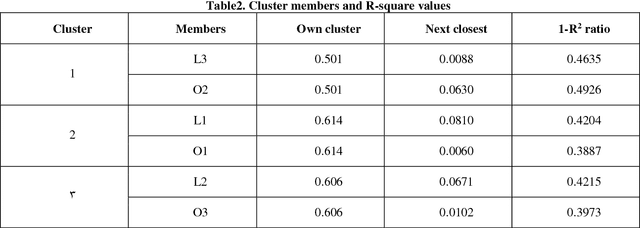
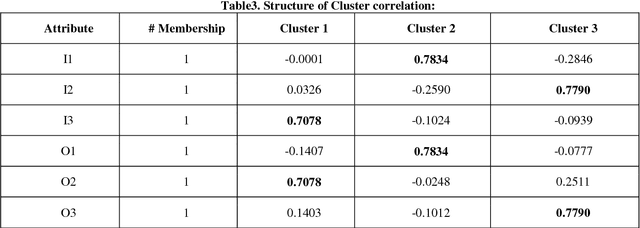
The banking industry is very important for an economic cycle of each country and provides some quality of services for us. With the advancement in technology and rapidly increasing of the complexity of the business environment, it has become more competitive than the past so that efficiency analysis in the banking industry attracts much attention in recent years. From many aspects, such analyses at the branch level are more desirable. Evaluating the branch performance with the purpose of eliminating deficiency can be a crucial issue for branch managers to measure branch efficiency. This work not only can lead to a better understanding of bank branch performance but also give further information to enhance managerial decisions to recognize problematic areas. To achieve this purpose, this study presents an integrated approach based on Data Envelopment Analysis (DEA), Clustering algorithms and Polynomial Pattern Classifier for constructing a classifier to identify a class of bank branches. First, the efficiency estimates of individual branches are evaluated by using the DEA approach. Next, when the range and number of classes were identified by experts, the number of clusters is identified by an agglomerative hierarchical clustering algorithm based on some statistical methods. Next, we divide our raw data into k clusters By means of self-organizing map (SOM) neural networks. Finally, all clusters are fed into the reduced multivariate polynomial model to predict the classes of data.