 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgek-Relevance Vectors for Pattern Classification
Paper and Code
Sep 18, 2019
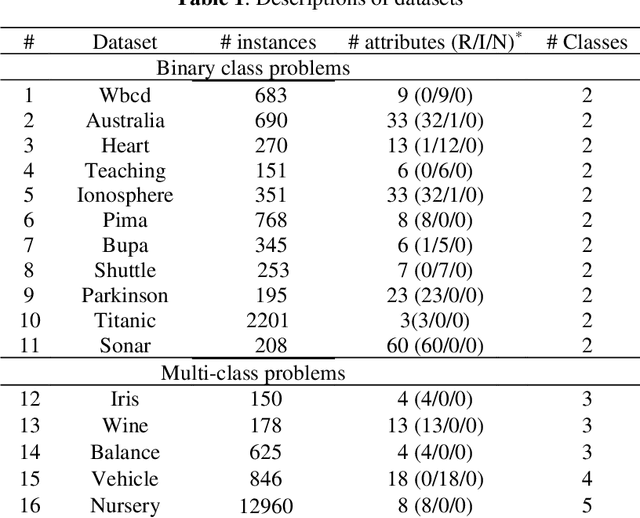

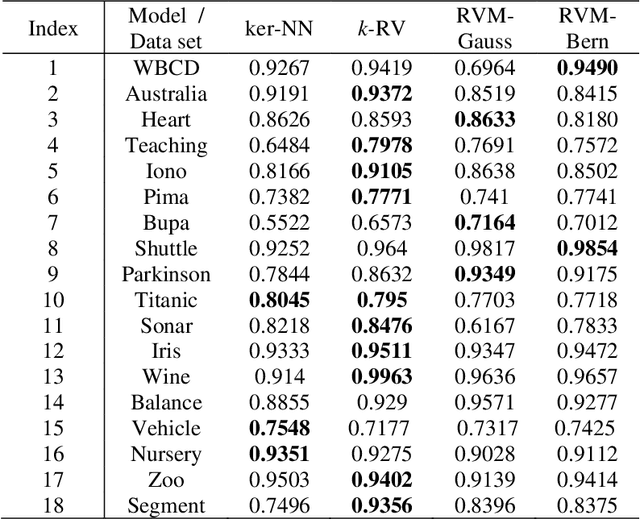
This study combines two different learning paradigms, k-nearest neighbor (k-NN) rule, as memory-based learning paradigm and relevance vector machines (RVM), as statistical learning paradigm. This combination is performed in kernel space and is called k-relevance vector (k-RV). The purpose is to improve the performance of k-NN rule. The proposed model significantly prunes irrelevant attributes. We also introduced a new parameter, responsible for early stopping of iterations in RVM. We show that the new parameter improves the classification accuracy of k-RV. Intensive experiments are conducted on several classification datasets from University of California Irvine (UCI) repository and two real datasets from computer vision domain. The performance of k-RV is highly competitive compared to a few state-of-the-arts in terms of classification accuracy.