 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupScene: Learning Overlap-Aware Global Descriptor for Unconstrained SfM
Jan 17, 2026Image retrieval is a critical step for alleviating the quadratic complexity of image matching in unconstrained Structure-from-Motion (SfM). However, in this context, image retrieval typically focuses more on the image pairs of geometric matchability than on those of semantic similarity, a nuance that most existing deep learning-based methods guided by batched binaries (overlapping vs. non-overlapping pairs) fail to capture. In this paper, we introduce SupScene, a novel solution that learns global descriptors tailored for finding overlapping image pairs of similar geometric nature for SfM. First, to better underline co-visible regions, we employ a subgraph-based training strategy that moves beyond equally important isolated pairs, leveraging ground-truth geometric overlapping relationships with various weights to provide fine-grained supervision via a soft supervised contrastive loss. Second, we introduce DiVLAD, a DINO-inspired VLAD aggregator that leverages the inherent multi-head attention maps from the last block of ViT. And then, a learnable gating mechanism is designed to adaptively utilize these semantically salient cues with visual features, enabling a more discriminative global descriptor. Extensive experiments on the GL3D dataset demonstrate that our method achieves state-of-the-art performance, significantly outperforming NetVLAD while introducing a negligible number of additional trainable parameters. Furthermore, we show that the proposed training strategy brings consistent gains across different aggregation techniques. Code and models are available at https://anonymous.4open.science/r/SupScene-5B73.
Learning geometry-image representation for 3D point cloud generation
Nov 29, 2020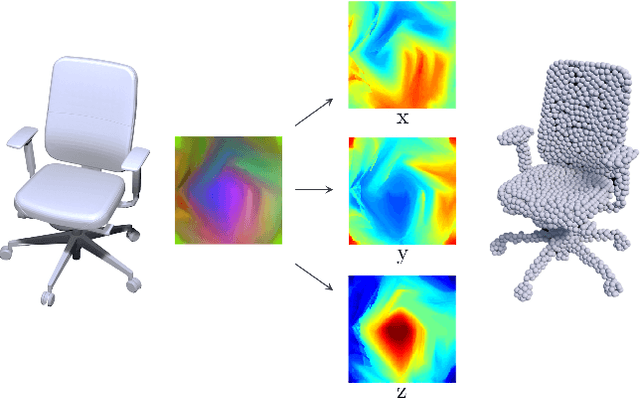
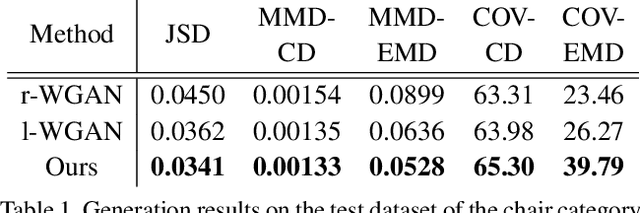
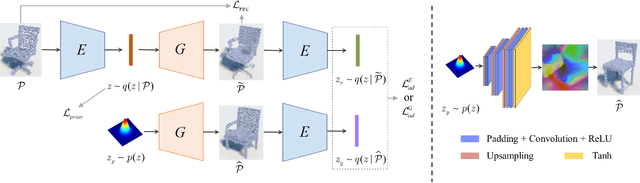

We study the problem of generating point clouds of 3D objects. Instead of discretizing the object into 3D voxels with huge computational cost and resolution limitations, we propose a novel geometry image based generator (GIG) to convert the 3D point cloud generation problem to a 2D geometry image generation problem. Since the geometry image is a completely regular 2D array that contains the surface points of the 3D object, it leverages both the regularity of the 2D array and the geodesic neighborhood of the 3D surface. Thus, one significant benefit of our GIG is that it allows us to directly generate the 3D point clouds using efficient 2D image generation networks. Experiments on both rigid and non-rigid 3D object datasets have demonstrated the promising performance of our method to not only create plausible and novel 3D objects, but also learn a probabilistic latent space that well supports the shape editing like interpolation and arithmetic.