 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver the Edge of Chaos? Excess Complexity as a Roadblock to Artificial General Intelligence
Jul 04, 2024In this study, we explored the progression trajectories of artificial intelligence (AI) systems through the lens of complexity theory. We challenged the conventional linear and exponential projections of AI advancement toward Artificial General Intelligence (AGI) underpinned by transformer-based architectures, and posited the existence of critical points, akin to phase transitions in complex systems, where AI performance might plateau or regress into instability upon exceeding a critical complexity threshold. We employed agent-based modelling (ABM) to simulate hypothetical scenarios of AI systems' evolution under specific assumptions, using benchmark performance as a proxy for capability and complexity. Our simulations demonstrated how increasing the complexity of the AI system could exceed an upper criticality threshold, leading to unpredictable performance behaviours. Additionally, we developed a practical methodology for detecting these critical thresholds using simulation data and stochastic gradient descent to fine-tune detection thresholds. This research offers a novel perspective on AI advancement that has a particular relevance to Large Language Models (LLMs), emphasising the need for a tempered approach to extrapolating AI's growth potential and underscoring the importance of developing more robust and comprehensive AI performance benchmarks.
From COBIT to ISO 42001: Evaluating Cybersecurity Frameworks for Opportunities, Risks, and Regulatory Compliance in Commercializing Large Language Models
Feb 24, 2024This study investigated the integration readiness of four predominant cybersecurity Governance, Risk and Compliance (GRC) frameworks - NIST CSF 2.0, COBIT 2019, ISO 27001:2022, and the latest ISO 42001:2023 - for the opportunities, risks, and regulatory compliance when adopting Large Language Models (LLMs), using qualitative content analysis and expert validation. Our analysis, with both LLMs and human experts in the loop, uncovered potential for LLM integration together with inadequacies in LLM risk oversight of those frameworks. Comparative gap analysis has highlighted that the new ISO 42001:2023, specifically designed for Artificial Intelligence (AI) management systems, provided most comprehensive facilitation for LLM opportunities, whereas COBIT 2019 aligned most closely with the impending European Union AI Act. Nonetheless, our findings suggested that all evaluated frameworks would benefit from enhancements to more effectively and more comprehensively address the multifaceted risks associated with LLMs, indicating a critical and time-sensitive need for their continuous evolution. We propose integrating human-expert-in-the-loop validation processes as crucial for enhancing cybersecurity frameworks to support secure and compliant LLM integration, and discuss implications for the continuous evolution of cybersecurity GRC frameworks to support the secure integration of LLMs.
Inadequacies of Large Language Model Benchmarks in the Era of Generative Artificial Intelligence
Feb 15, 2024The rapid rise in popularity of Large Language Models (LLMs) with emerging capabilities has spurred public curiosity to evaluate and compare different LLMs, leading many researchers to propose their LLM benchmarks. Noticing preliminary inadequacies in those benchmarks, we embarked on a study to critically assess 23 state-of-the-art LLM benchmarks, using our novel unified evaluation framework through the lenses of people, process, and technology, under the pillars of functionality and security. Our research uncovered significant limitations, including biases, difficulties in measuring genuine reasoning, adaptability, implementation inconsistencies, prompt engineering complexity, evaluator diversity, and the overlooking of cultural and ideological norms in one comprehensive assessment. Our discussions emphasized the urgent need for standardized methodologies, regulatory certainties, and ethical guidelines in light of Artificial Intelligence (AI) advancements, including advocating for an evolution from static benchmarks to dynamic behavioral profiling to accurately capture LLMs' complex behaviors and potential risks. Our study highlighted the necessity for a paradigm shift in LLM evaluation methodologies, underlining the importance of collaborative efforts for the development of universally accepted benchmarks and the enhancement of AI systems' integration into society.
From Google Gemini to OpenAI Q* : A Survey of Reshaping the Generative Artificial Intelligence Research Landscape
Dec 18, 2023This comprehensive survey explored the evolving landscape of generative Artificial Intelligence (AI), with a specific focus on the transformative impacts of Mixture of Experts (MoE), multimodal learning, and the speculated advancements towards Artificial General Intelligence (AGI). It critically examined the current state and future trajectory of generative Artificial Intelligence (AI), exploring how innovations like Google's Gemini and the anticipated OpenAI Q* project are reshaping research priorities and applications across various domains, including an impact analysis on the generative AI research taxonomy. It assessed the computational challenges, scalability, and real-world implications of these technologies while highlighting their potential in driving significant progress in fields like healthcare, finance, and education. It also addressed the emerging academic challenges posed by the proliferation of both AI-themed and AI-generated preprints, examining their impact on the peer-review process and scholarly communication. The study highlighted the importance of incorporating ethical and human-centric methods in AI development, ensuring alignment with societal norms and welfare, and outlined a strategy for future AI research that focuses on a balanced and conscientious use of MoE, multimodality, and AGI in generative AI.
CalBehav: A Machine Learning based Personalized Calendar Behavioral Model using Time-Series Smartphone Data
Sep 02, 2019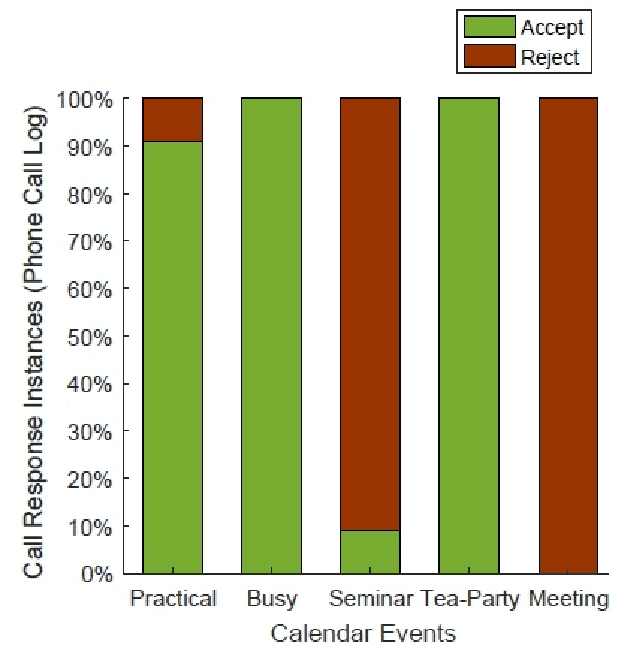
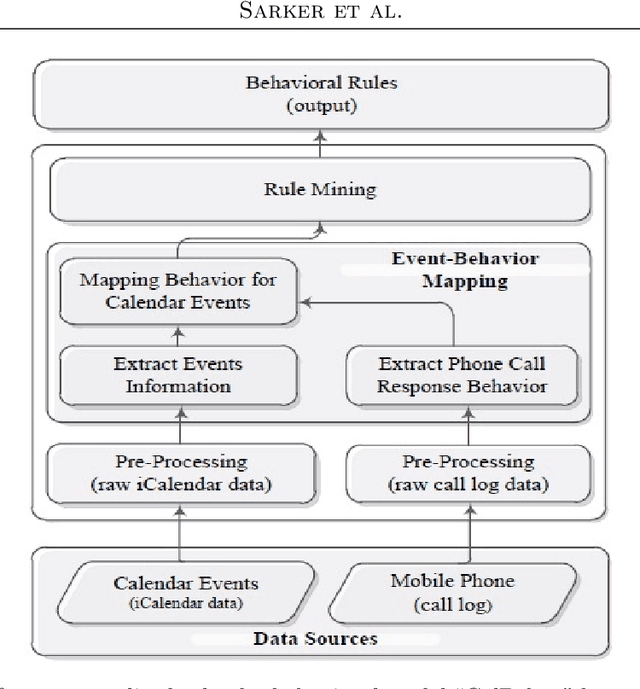
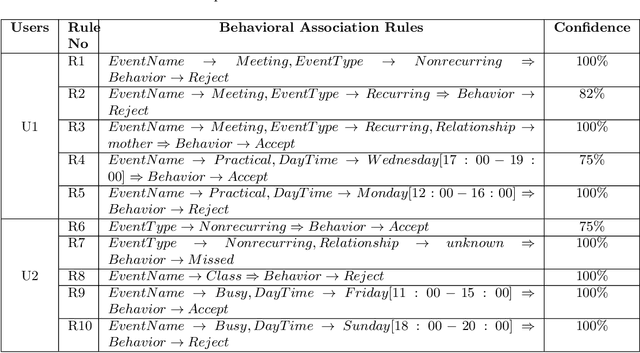
The electronic calendar is a valuable resource nowadays for managing our daily life appointments or schedules, also known as events, ranging from professional to highly personal. Researchers have studied various types of calendar events to predict smartphone user behavior for incoming mobile communications. However, these studies typically do not take into account behavioral variations between individuals. In the real world, smartphone users can differ widely from each other in how they respond to incoming communications during their scheduled events. Moreover, an individual user may respond the incoming communications differently in different contexts subject to what type of event is scheduled in her personal calendar. Thus, a static calendar-based behavioral model for individual smartphone users does not necessarily reflect their behavior to the incoming communications. In this paper, we present a machine learning based context-aware model that is personalized and dynamically identifies individual's dominant behavior for their scheduled events using logged time-series smartphone data, and shortly name as ``CalBehav''. The experimental results based on real datasets from calendar and phone logs, show that this data-driven personalized model is more effective for intelligently managing the incoming mobile communications compared to existing calendar-based approaches.
* 16 pages, double column