 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMMaps -- A Visual Metaphor for Stratified Evaluation of Large Language Models
Apr 02, 2023



Large Language Models (LLMs) have revolutionized natural language processing and demonstrated impressive capabilities in various tasks. Unfortunately, they are prone to hallucinations, where the model exposes incorrect or false information in its responses, which renders diligent evaluation approaches mandatory. While LLM performance in specific knowledge fields is often evaluated based on question and answer (Q&A) datasets, such evaluations usually report only a single accuracy number for the entire field, a procedure which is problematic with respect to transparency and model improvement. A stratified evaluation could instead reveal subfields, where hallucinations are more likely to occur and thus help to better assess LLMs' risks and guide their further development. To support such stratified evaluations, we propose LLMMaps as a novel visualization technique that enables users to evaluate LLMs' performance with respect to Q&A datasets. LLMMaps provide detailed insights into LLMs' knowledge capabilities in different subfields, by transforming Q&A datasets as well as LLM responses into our internal knowledge structure. An extension for comparative visualization furthermore, allows for the detailed comparison of multiple LLMs. To assess LLMMaps we use them to conduct a comparative analysis of several state-of-the-art LLMs, such as BLOOM, GPT-2, GPT-3, ChatGPT and LLaMa-13B, as well as two qualitative user evaluations. All necessary source code and data for generating LLMMaps to be used in scientific publications and elsewhere will be available on GitHub.
Human Pose Estimation from Sparse Inertial Measurements through Recurrent Graph Convolution
Jul 23, 2021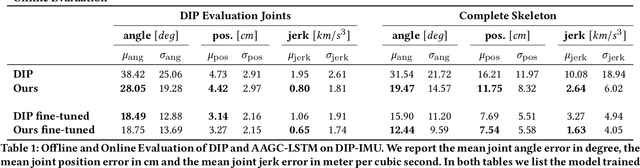
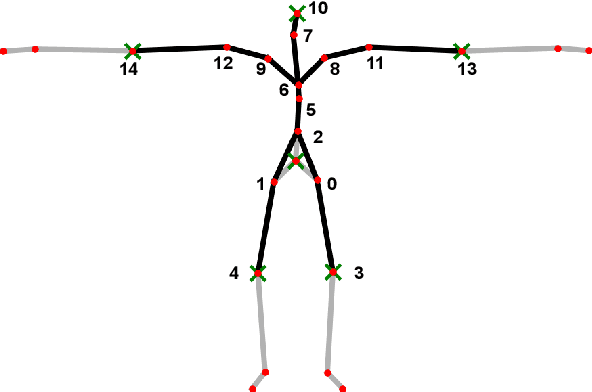
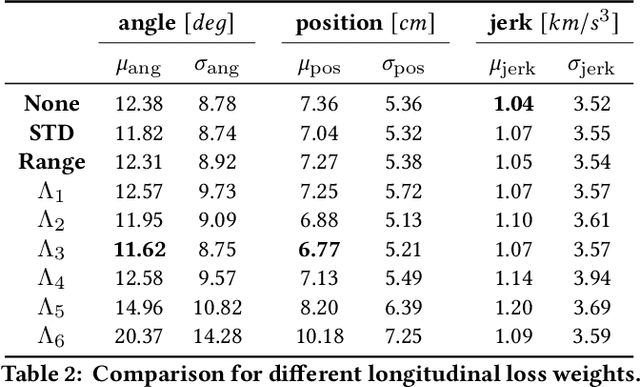
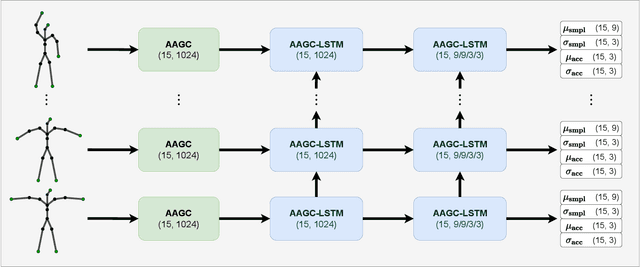
We propose the adjacency adaptive graph convolutional long-short term memory network (AAGC-LSTM) for human pose estimation from sparse inertial measurements, obtained from only 6 measurement units. The AAGC-LSTM combines both spatial and temporal dependency in a single network operation. This is made possible by equipping graph convolutions with adjacency adaptivity, which also allows for learning unknown dependencies of the human body joints. To further boost accuracy, we propose longitudinal loss weighting to consider natural movement patterns, as well as body-aware contralateral data augmentation. By combining these contributions, we are able to utilize the inherent graph nature of the human body, and can thus outperform the state of the art for human pose estimation from sparse inertial measurements.
Data-driven deep density estimation
Jul 23, 2021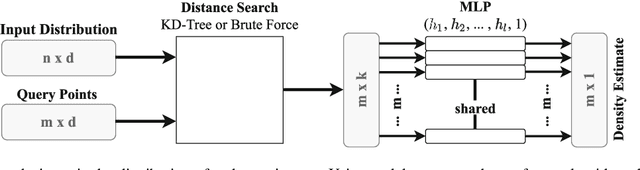
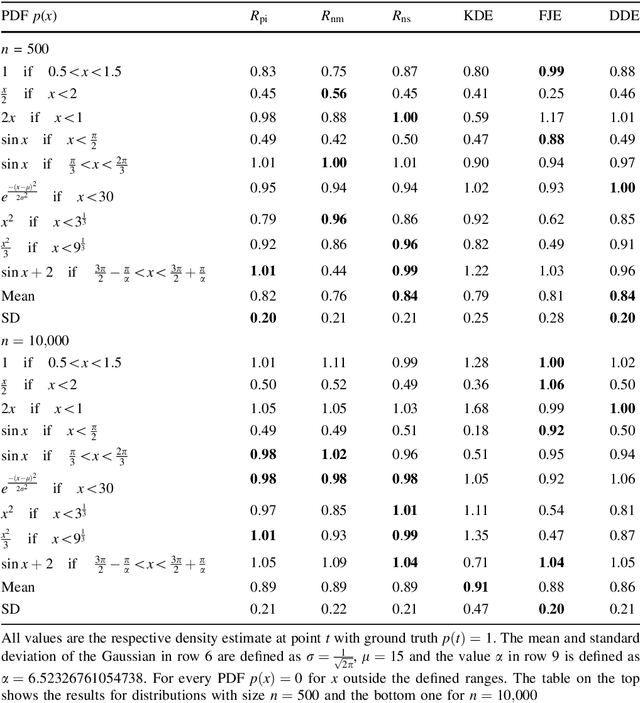
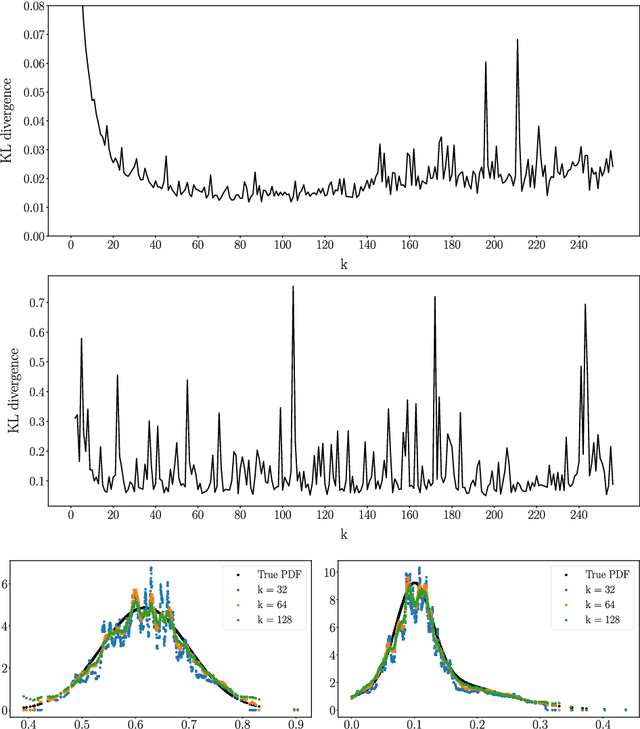

Density estimation plays a crucial role in many data analysis tasks, as it infers a continuous probability density function (PDF) from discrete samples. Thus, it is used in tasks as diverse as analyzing population data, spatial locations in 2D sensor readings, or reconstructing scenes from 3D scans. In this paper, we introduce a learned, data-driven deep density estimation (DDE) to infer PDFs in an accurate and efficient manner, while being independent of domain dimensionality or sample size. Furthermore, we do not require access to the original PDF during estimation, neither in parametric form, nor as priors, or in the form of many samples. This is enabled by training an unstructured convolutional neural network on an infinite stream of synthetic PDFs, as unbound amounts of synthetic training data generalize better across a deck of natural PDFs than any natural finite training data will do. Thus, we hope that our publicly available DDE method will be beneficial in many areas of data analysis, where continuous models are to be estimated from discrete observations.