 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR4Dyn: Exploring Radar for Self-Supervised Monocular Depth Estimation of Dynamic Scenes
Aug 10, 2021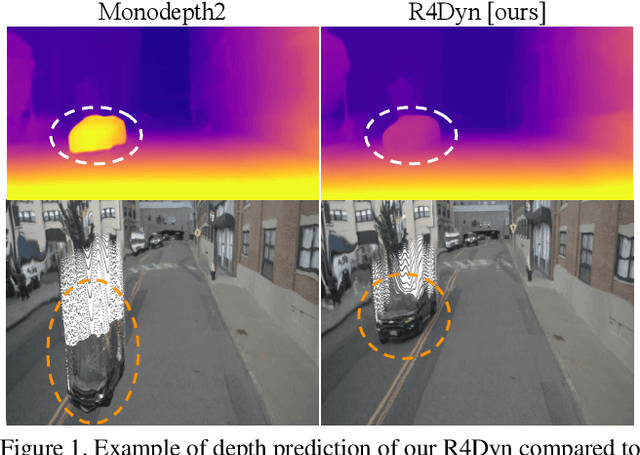
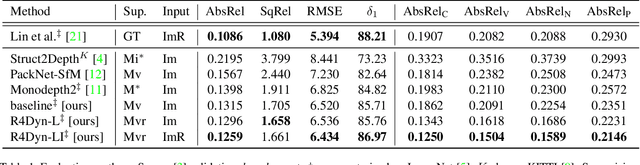
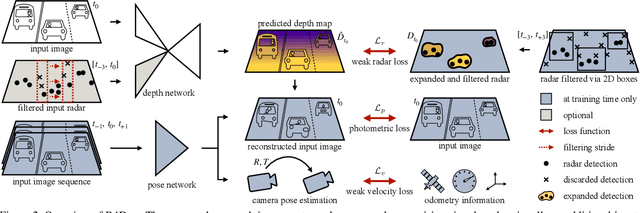
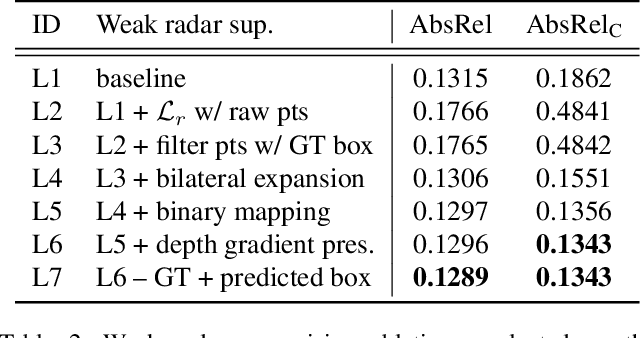
While self-supervised monocular depth estimation in driving scenarios has achieved comparable performance to supervised approaches, violations of the static world assumption can still lead to erroneous depth predictions of traffic participants, posing a potential safety issue. In this paper, we present R4Dyn, a novel set of techniques to use cost-efficient radar data on top of a self-supervised depth estimation framework. In particular, we show how radar can be used during training as weak supervision signal, as well as an extra input to enhance the estimation robustness at inference time. Since automotive radars are readily available, this allows to collect training data from a variety of existing vehicles. Moreover, by filtering and expanding the signal to make it compatible with learning-based approaches, we address radar inherent issues, such as noise and sparsity. With R4Dyn we are able to overcome a major limitation of self-supervised depth estimation, i.e. the prediction of traffic participants. We substantially improve the estimation on dynamic objects, such as cars by 37% on the challenging nuScenes dataset, hence demonstrating that radar is a valuable additional sensor for monocular depth estimation in autonomous vehicles. Additionally, we plan on making the code publicly available.
Constrained Multi-Objective Optimization for Automated Machine Learning
Aug 14, 2019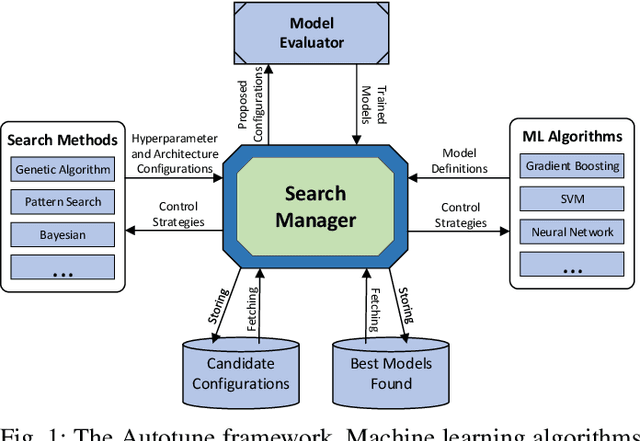
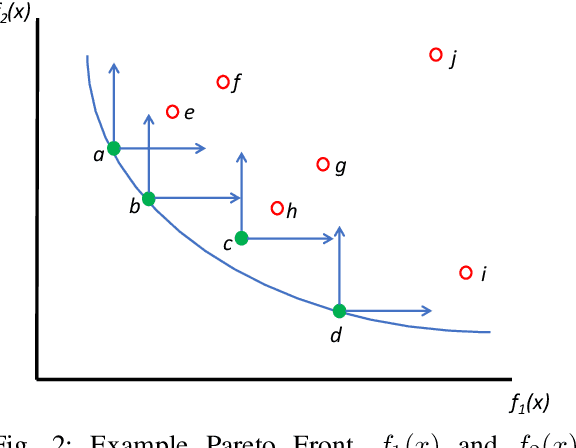
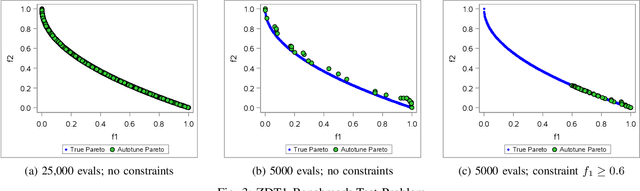
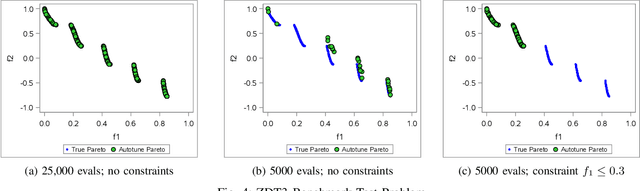
Automated machine learning has gained a lot of attention recently. Building and selecting the right machine learning models is often a multi-objective optimization problem. General purpose machine learning software that simultaneously supports multiple objectives and constraints is scant, though the potential benefits are great. In this work, we present a framework called Autotune that effectively handles multiple objectives and constraints that arise in machine learning problems. Autotune is built on a suite of derivative-free optimization methods, and utilizes multi-level parallelism in a distributed computing environment for automatically training, scoring, and selecting good models. Incorporation of multiple objectives and constraints in the model exploration and selection process provides the flexibility needed to satisfy trade-offs necessary in practical machine learning applications. Experimental results from standard multi-objective optimization benchmark problems show that Autotune is very efficient in capturing Pareto fronts. These benchmark results also show how adding constraints can guide the search to more promising regions of the solution space, ultimately producing more desirable Pareto fronts. Results from two real-world case studies demonstrate the effectiveness of the constrained multi-objective optimization capability offered by Autotune.
Autotune: A Derivative-free Optimization Framework for Hyperparameter Tuning
Aug 02, 2018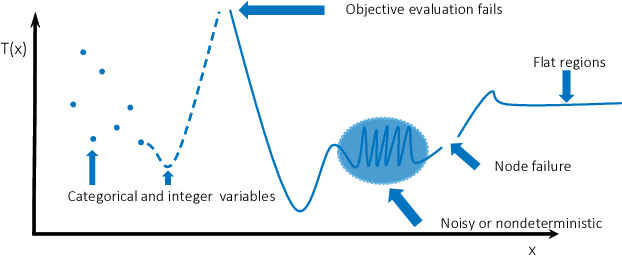
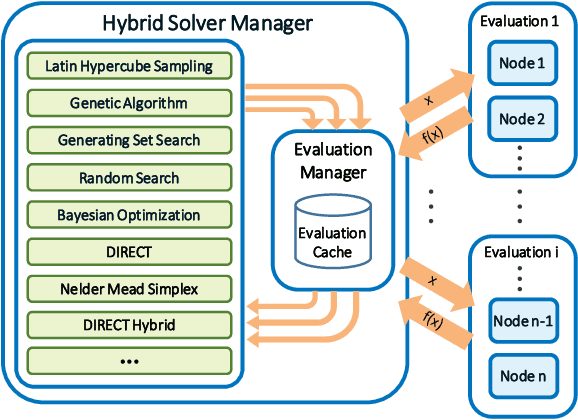
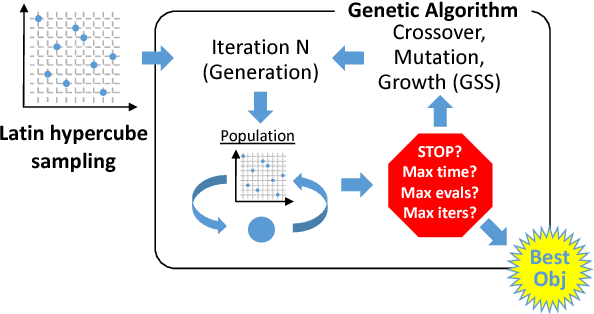
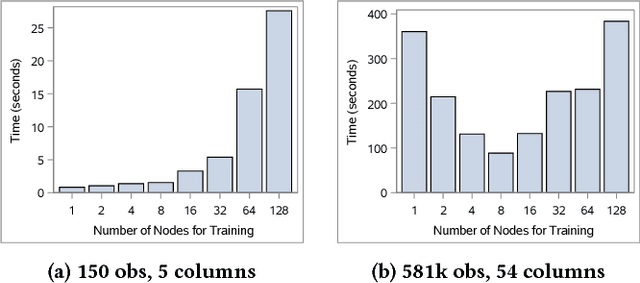
Machine learning applications often require hyperparameter tuning. The hyperparameters usually drive both the efficiency of the model training process and the resulting model quality. For hyperparameter tuning, machine learning algorithms are complex black-boxes. This creates a class of challenging optimization problems, whose objective functions tend to be nonsmooth, discontinuous, unpredictably varying in computational expense, and include continuous, categorical, and/or integer variables. Further, function evaluations can fail for a variety of reasons including numerical difficulties or hardware failures. Additionally, not all hyperparameter value combinations are compatible, which creates so called hidden constraints. Robust and efficient optimization algorithms are needed for hyperparameter tuning. In this paper we present an automated parallel derivative-free optimization framework called \textbf{Autotune}, which combines a number of specialized sampling and search methods that are very effective in tuning machine learning models despite these challenges. Autotune provides significantly improved models over using default hyperparameter settings with minimal user interaction on real-world applications. Given the inherent expense of training numerous candidate models, we demonstrate the effectiveness of Autotune's search methods and the efficient distributed and parallel paradigms for training and tuning models, and also discuss the resource trade-offs associated with the ability to both distribute the training process and parallelize the tuning process.
How slow is slow? SFA detects signals that are slower than the driving force
Nov 23, 2009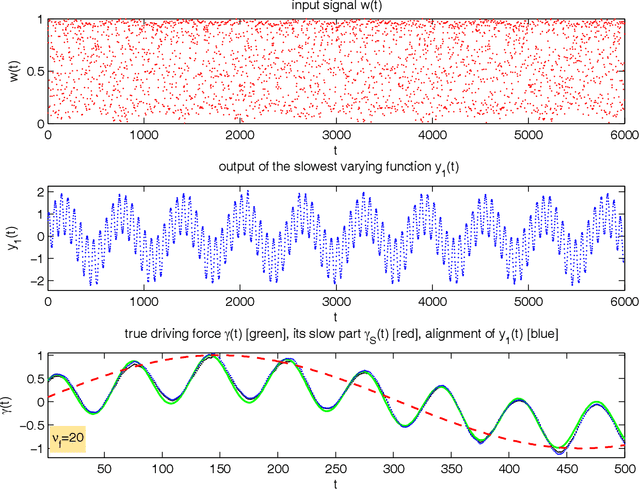
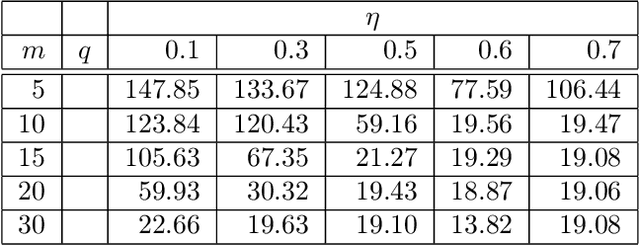
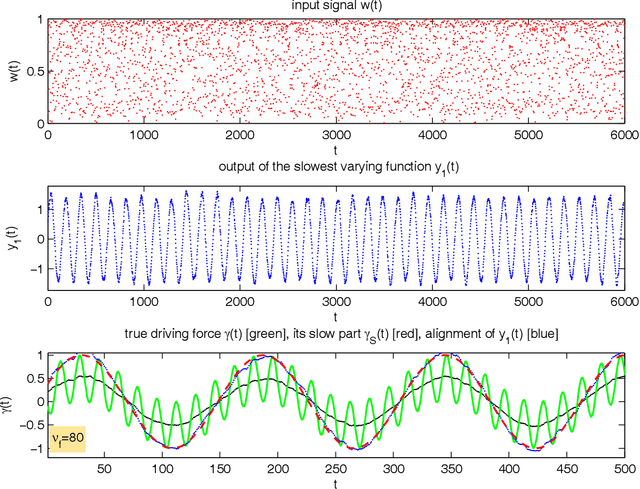
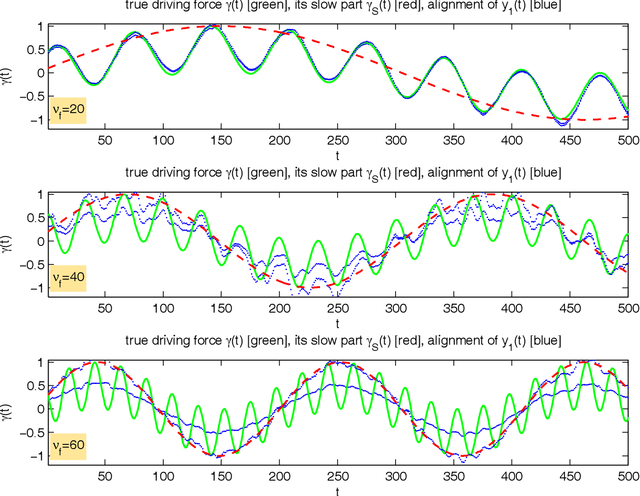
Slow feature analysis (SFA) is a method for extracting slowly varying driving forces from quickly varying nonstationary time series. We show here that it is possible for SFA to detect a component which is even slower than the driving force itself (e.g. the envelope of a modulated sine wave). It is shown that it depends on circumstances like the embedding dimension, the time series predictability, or the base frequency, whether the driving force itself or a slower subcomponent is detected. We observe a phase transition from one regime to the other and it is the purpose of this work to quantify the influence of various parameters on this phase transition. We conclude that what is percieved as slow by SFA varies and that a more or less fast switching from one regime to the other occurs, perhaps showing some similarity to human perception.