 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproduction and Replication of an Adversarial Stylometry Experiment
Aug 15, 2022
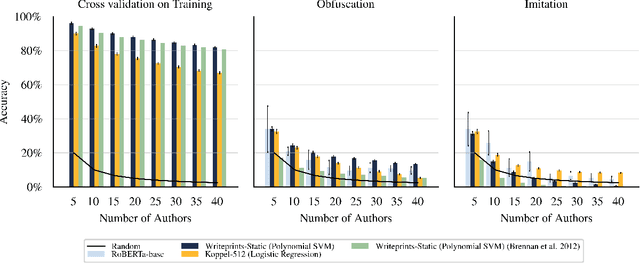
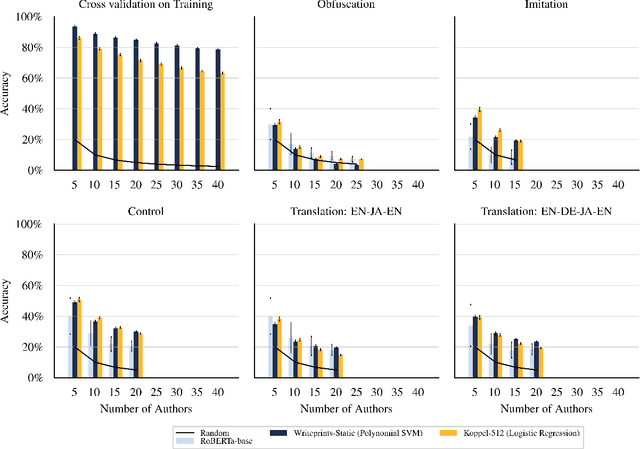
Maintaining anonymity while communicating using natural language remains a challenge. Standard authorship attribution techniques that analyze candidate authors' writing styles achieve uncomfortably high accuracy even when the number of candidate authors is high. Adversarial stylometry defends against authorship attribution with the goal of preventing unwanted deanonymization. This paper reproduces and replicates experiments in a seminal study of defenses against authorship attribution (Brennan et al., 2012). We are able to successfully reproduce and replicate the original results, although we conclude that the effectiveness of the defenses studied is overstated due to a lack of a control group in the original study. In our replication, we find new evidence suggesting that an entirely automatic method, round-trip translation, merits re-examination as it appears to reduce the effectiveness of established authorship attribution methods.
Isolated-Word Confusion Metrics and the PGPfone Alphabet
Aug 29, 1996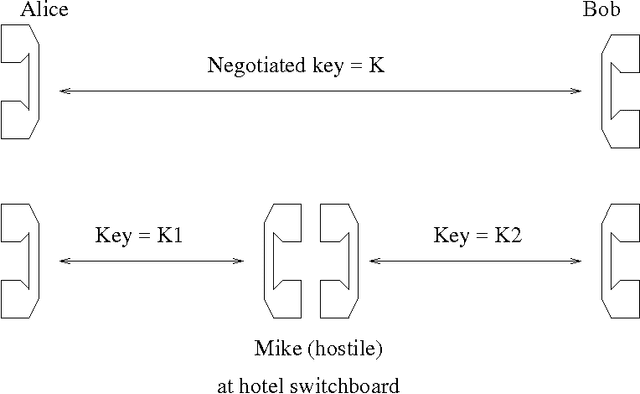
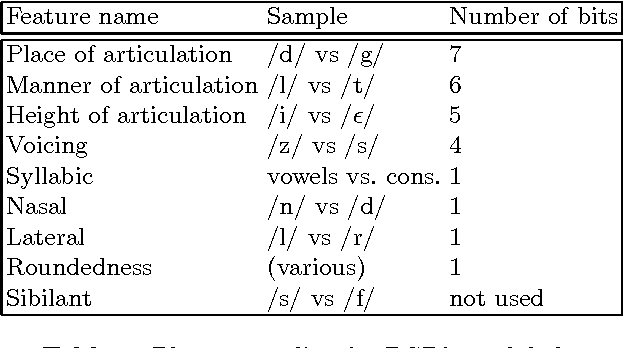
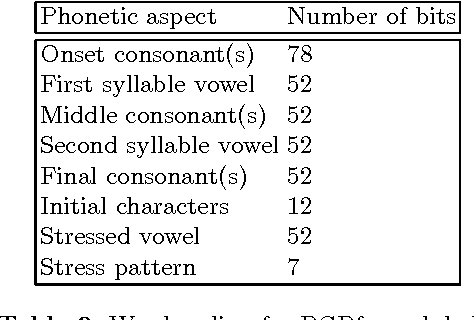

Although the confusion of individual phonemes and features have been studied and analyzed since (Miller and Nicely, 1955), there has been little work done on extending this to a predictive theory of word-level confusions. The PGPfone alphabet is a good touchstone problem for developing such word-level confusion metrics. This paper presents some difficulties incurred, along with their proposed solutions, in the extension of phonetic confusion results to a theoretical whole-word phonetic distance metric. The proposed solutions have been used, in conjunction with a set of selection filters, in a genetic algorithm to automatically generate appropriate word lists for a radio alphabet. This work illustrates some principles and pitfalls that should be addressed in any numeric theory of isolated word perception.
* 12 pages, includes minipage.tex and nemlapfig.eps, uses nemlap.sty
Phonetic Ambiguity : Approaches, Touchstones, Pitfalls and New Approaches
Aug 29, 1996
Phonetic ambiguity and confusibility are bugbears for any form of bottom-up or data-driven approach to language processing. The question of when an input is ``close enough'' to a target word pervades the entire problem spaces of speech recognition, synthesis, language acquisition, speech compression, and language representation, but the variety of representations that have been applied are demonstrably inadequate to at least some aspects of the problem. This paper reviews this inadequacy by examining several touchstone models in phonetic ambiguity and relating them to the problems they were designed to solve. An good solution would be, among other things, efficient, accurate, precise, and universally applicable to representation of words, ideally usable as a ``phonetic distance'' metric for direct measurement of the ``distance'' between word or utterance pairs. None of the proposed models can provide a complete solution to the problem; in general, there is no algorithmic theory of phonetic distance. It is unclear whether this is a weakness of our representational technology or a more fundamental difficulty with the problem statement.
* LaTex, 6 pages, self-contained
Self-Organizing Machine Translation: Example-Driven Induction of Transfer Functions
Jun 03, 1994With the advent of faster computers, the notion of doing machine translation from a huge stored database of translation examples is no longer unreasonable. This paper describes an attempt to merge the Example-Based Machine Translation (EBMT) approach with psycholinguistic principles. A new formalism for context- free grammars, called *marker-normal form*, is demonstrated and used to describe language data in a way compatible with psycholinguistic theories. By embedding this formalism in a standard multivariate optimization framework, a system can be built that infers correct transfer functions for a set of bilingual sentence pairs and then uses those functions to translate novel sentences. The validity of this line of reasoning has been tested in the development of a system called METLA-1. This system has been used to infer English->French and English->Urdu transfer functions from small corpora. The results of those experiments are examined, both in engineering terms as well as in more linguistic terms. In general, the results of these experiments were psycho- logically and linguistically well-grounded while still achieving a respectable level of success when compared against a similar prototype using Hidden Markov Models.