 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproduction and Replication of an Adversarial Stylometry Experiment
Aug 15, 2022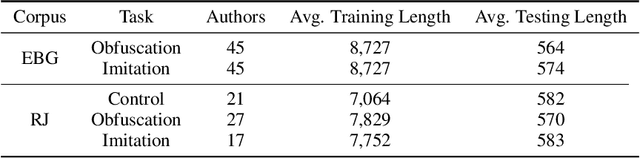
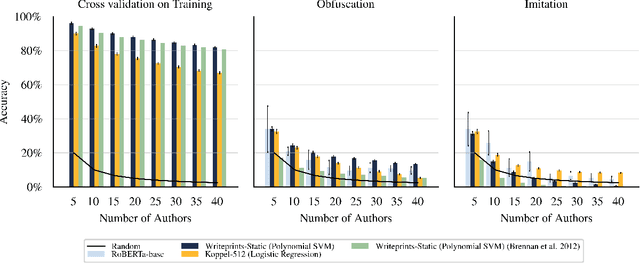
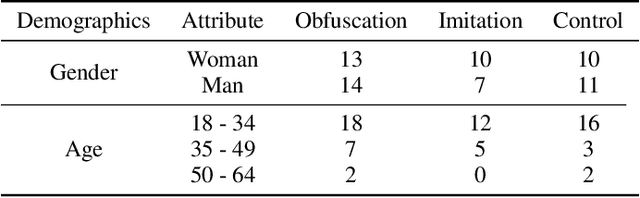
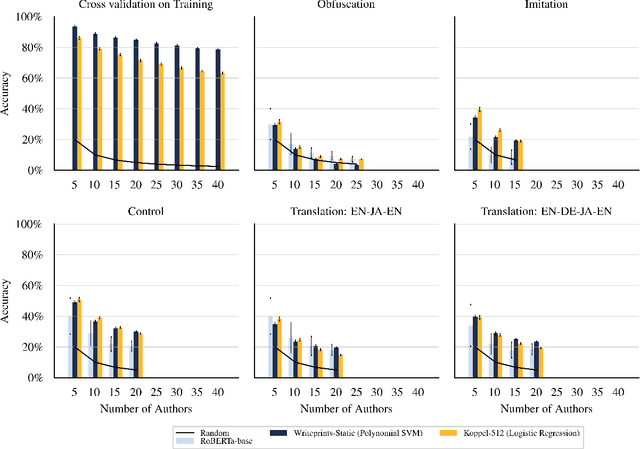
Maintaining anonymity while communicating using natural language remains a challenge. Standard authorship attribution techniques that analyze candidate authors' writing styles achieve uncomfortably high accuracy even when the number of candidate authors is high. Adversarial stylometry defends against authorship attribution with the goal of preventing unwanted deanonymization. This paper reproduces and replicates experiments in a seminal study of defenses against authorship attribution (Brennan et al., 2012). We are able to successfully reproduce and replicate the original results, although we conclude that the effectiveness of the defenses studied is overstated due to a lack of a control group in the original study. In our replication, we find new evidence suggesting that an entirely automatic method, round-trip translation, merits re-examination as it appears to reduce the effectiveness of established authorship attribution methods.
Zero-Shot Style Transfer in Text Using Recurrent Neural Networks
Nov 13, 2017
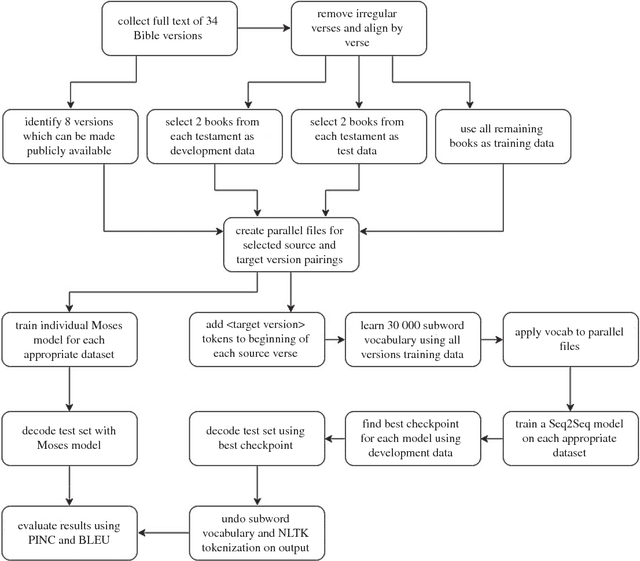
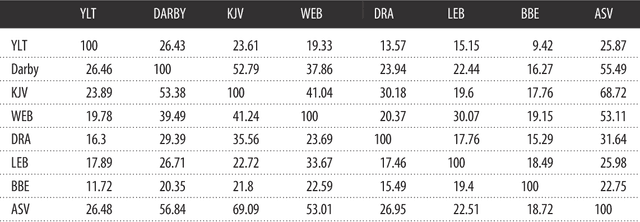

Zero-shot translation is the task of translating between a language pair where no aligned data for the pair is provided during training. In this work we employ a model that creates paraphrases which are written in the style of another existing text. Since we provide the model with no paired examples from the source style to the target style during training, we call this task zero-shot style transfer. Herein, we identify a high-quality source of aligned, stylistically distinct text in Bible versions and use this data to train an encoder/decoder recurrent neural model. We also train a statistical machine translation system, Moses, for comparison. We find that the neural network outperforms Moses on the established BLEU and PINC metrics for evaluating paraphrase quality. This technique can be widely applied due to the broad definition of style which is used. For example, tasks like text simplification can easily be viewed as style transfer. The corpus itself is highly parallel with 33 distinct Bible Versions used, and human-aligned due to the presence of chapter and verse numbers within the text. This makes the data a rich source of study for other natural language tasks.