 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsolated-Word Confusion Metrics and the PGPfone Alphabet
Paper and Code
Aug 29, 1996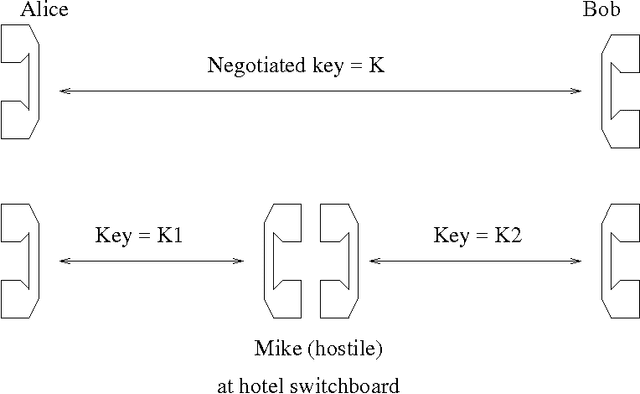
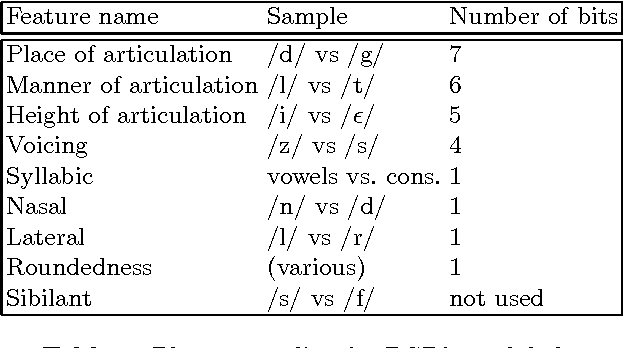
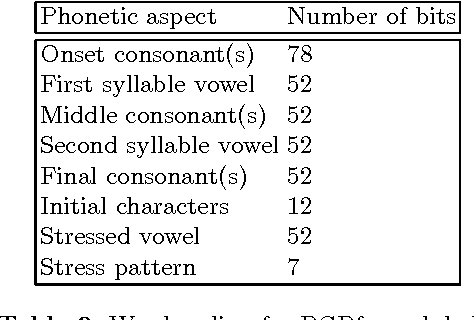

Although the confusion of individual phonemes and features have been studied and analyzed since (Miller and Nicely, 1955), there has been little work done on extending this to a predictive theory of word-level confusions. The PGPfone alphabet is a good touchstone problem for developing such word-level confusion metrics. This paper presents some difficulties incurred, along with their proposed solutions, in the extension of phonetic confusion results to a theoretical whole-word phonetic distance metric. The proposed solutions have been used, in conjunction with a set of selection filters, in a genetic algorithm to automatically generate appropriate word lists for a radio alphabet. This work illustrates some principles and pitfalls that should be addressed in any numeric theory of isolated word perception.