 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Compression of Nonlinear Time Series With Random Access
Dec 20, 2024Time series play a crucial role in many fields, including finance, healthcare, industry, and environmental monitoring. The storage and retrieval of time series can be challenging due to their unstoppable growth. In fact, these applications often sacrifice precious historical data to make room for new data. General-purpose compressors can mitigate this problem with their good compression ratios, but they lack efficient random access on compressed data, thus preventing real-time analyses. Ad-hoc streaming solutions, instead, typically optimise only for compression and decompression speed, while giving up compression effectiveness and random access functionality. Furthermore, all these methods lack awareness of certain special regularities of time series, whose trends over time can often be described by some linear and nonlinear functions. To address these issues, we introduce NeaTS, a randomly-accessible compression scheme that approximates the time series with a sequence of nonlinear functions of different kinds and shapes, carefully selected and placed by a partitioning algorithm to minimise the space. The approximation residuals are bounded, which allows storing them in little space and thus recovering the original data losslessly, or simply discarding them to obtain a lossy time series representation with maximum error guarantees. Our experiments show that NeaTS improves the compression ratio of the state-of-the-art lossy compressors that use linear or nonlinear functions (or both) by up to 14%. Compared to lossless compressors, NeaTS emerges as the only approach to date providing, simultaneously, compression ratios close to or better than the best existing compressors, a much faster decompression speed, and orders of magnitude more efficient random access, thus enabling the storage and real-time analysis of massive and ever-growing amounts of (historical) time series data.
An interactive dashboard for searching and comparing soccer performance scores
May 11, 2021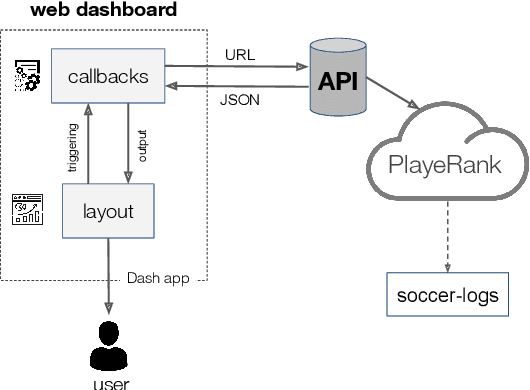
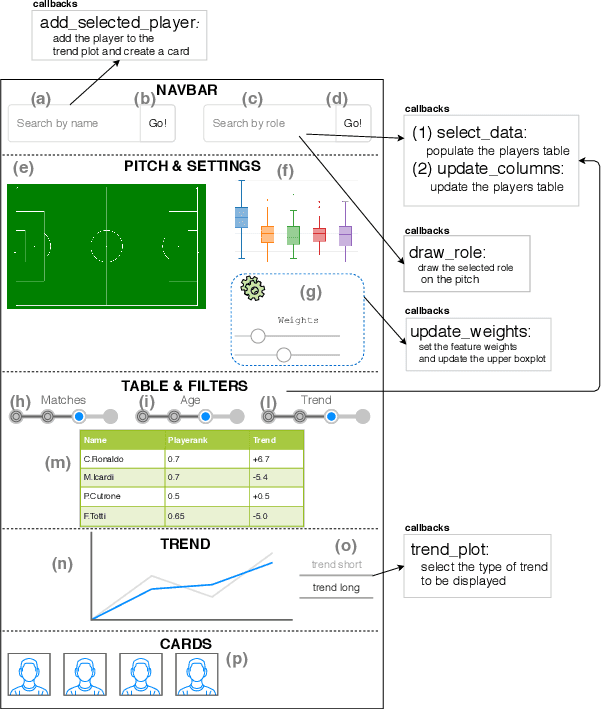
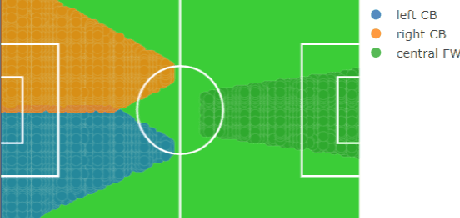
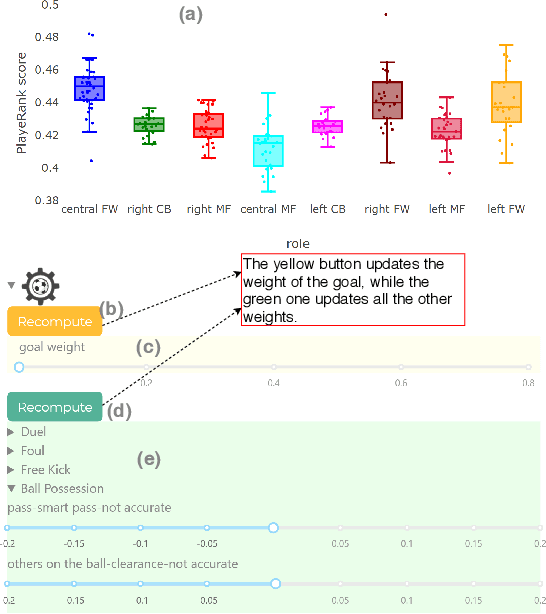
The performance of soccer players is one of most discussed aspects by many actors in the soccer industry: from supporters to journalists, from coaches to talent scouts. Unfortunately, the dashboards available online provide no effective way to compare the evolution of the performance of players or to find players behaving similarly on the field. This paper describes the design of a web dashboard that interacts via APIs with a performance evaluation algorithm and provides graphical tools that allow the user to perform many tasks, such as to search or compare players by age, role or trend of growth in their performance, find similar players based on their pitching behavior, change the algorithm's parameters to obtain customized performance scores. We also describe an example of how a talent scout can interact with the dashboard to find young, promising talents.
The PGM-index: a multicriteria, compressed and learned approach to data indexing
Oct 14, 2019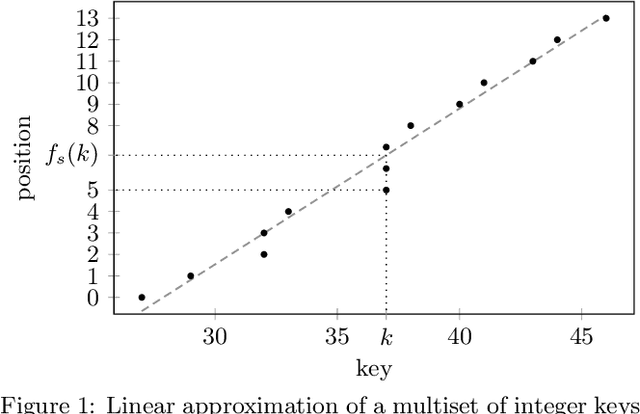

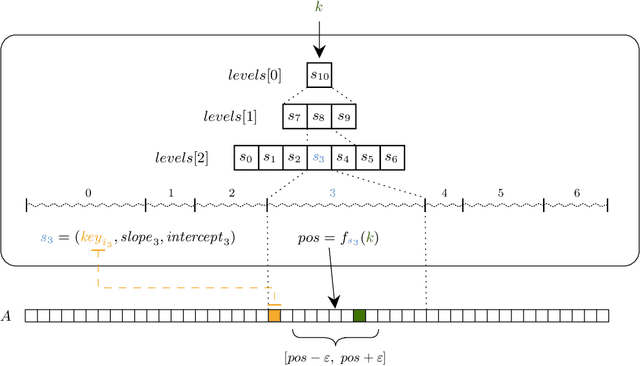
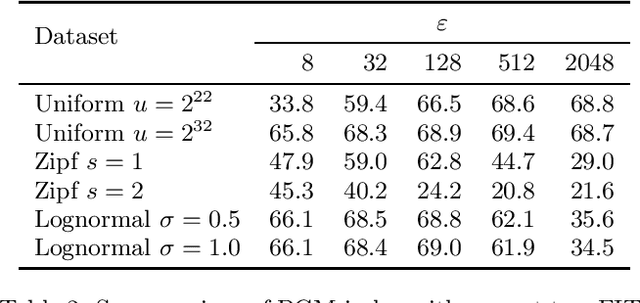
The recent introduction of learned indexes has shaken the foundations of the decades-old field of indexing data structures. Combining, or even replacing, classic design elements such as B-tree nodes with machine learning models has proven to give outstanding improvements in the space footprint and time efficiency of data systems. However, these novel approaches are based on heuristics, thus they lack any guarantees both in their time and space requirements. We propose the Piecewise Geometric Model index (shortly, PGM-index), which achieves guaranteed I/O-optimality in query operations, learns an optimal number of linear models, and its peculiar recursive construction makes it a purely learned data structure, rather than a hybrid of traditional and learned indexes (such as RMI and FITing-tree). We show that the PGM-index improves the space of the FITing-tree by 63.3% and of the B-tree by more than four orders of magnitude, while achieving their same or even better query time efficiency. We complement this result by proposing three variants of the PGM-index. First, we design a compressed PGM-index that further reduces its space footprint by exploiting the repetitiveness at the level of the learned linear models it is composed of. Second, we design a PGM-index that adapts itself to the distribution of the queries, thus resulting in the first known distribution-aware learned index to date. Finally, given its flexibility in the offered space-time trade-offs, we propose the multicriteria PGM-index that efficiently auto-tune itself in a few seconds over hundreds of millions of keys to the possibly evolving space-time constraints imposed by the application of use. We remark to the reader that this paper is an extended and improved version of our previous paper titled "Superseding traditional indexes by orchestrating learning and geometry" (arXiv:1903.00507).
PlayeRank: Multi-dimensional and role-aware rating of soccer player performance
Feb 16, 2018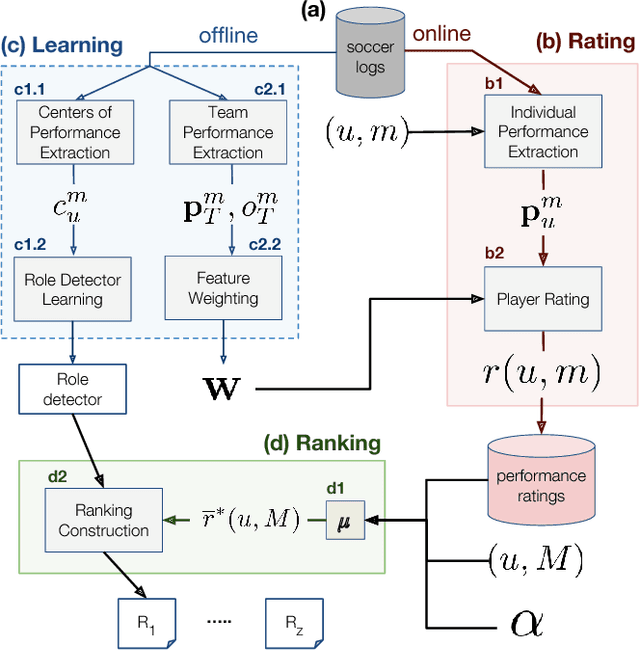
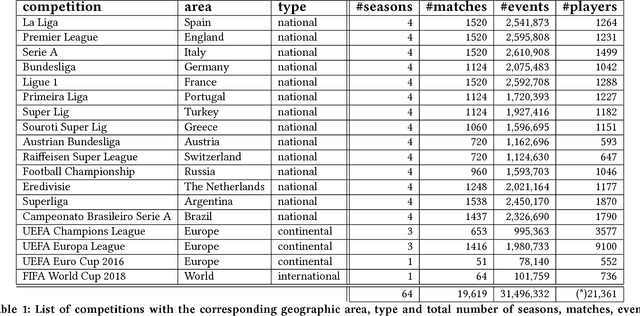
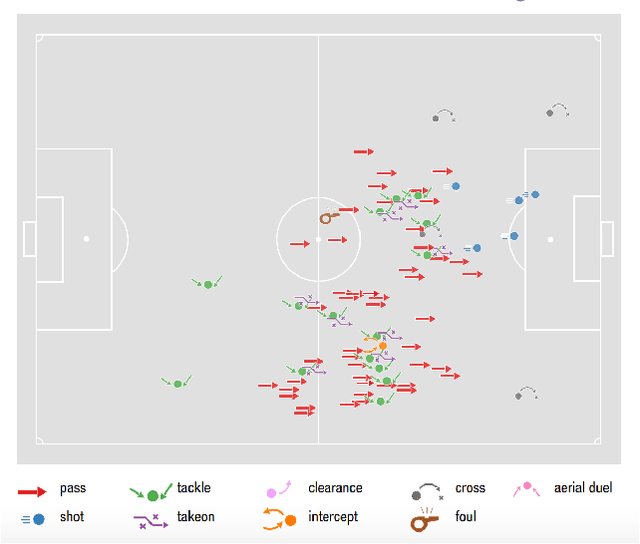

The problem of rating the performance of soccer players is attracting the interest of many companies, websites, and the scientific community, thanks to the availability of massive data capturing all the events generated during a game (e.g., tackles, passes, shots, etc.). Existing approaches fail to fully exploit the richness of the available data and lack of a proper validation. In this paper, we design and implement PlayeRank, a data-driven framework that offers a principled multi-dimensional and role-aware evaluation of the performance of soccer players. We validate the framework through an experimental analysis advised by soccer experts, based on a massive dataset of millions of events pertaining four seasons of the five prominent European leagues. Experiments show that PlayeRank is robust in agreeing with the experts' evaluation of players, significantly improving the state of the art. We also explore an application of PlayeRank --- i.e. searching players --- by introducing a special form of spatial query on the soccer field. This shows its flexibility and efficiency, which makes it worth to be used in the design of a scalable platform for soccer analytics.