 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PGM-index: a multicriteria, compressed and learned approach to data indexing
Paper and Code
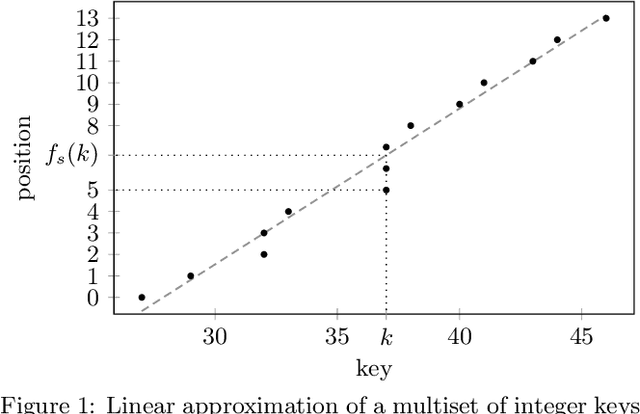

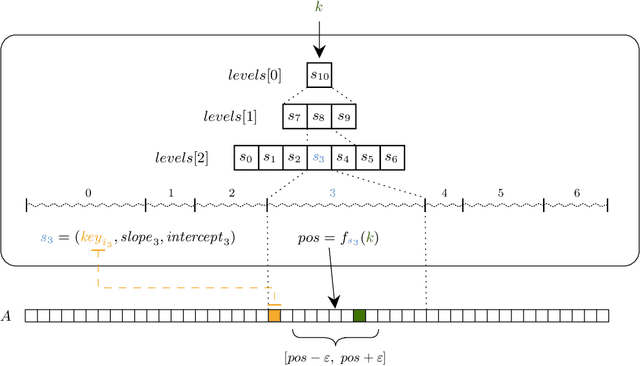
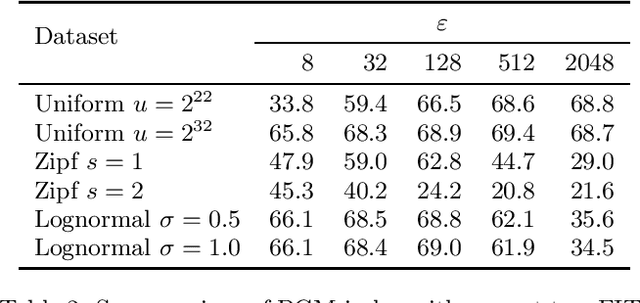
The recent introduction of learned indexes has shaken the foundations of the decades-old field of indexing data structures. Combining, or even replacing, classic design elements such as B-tree nodes with machine learning models has proven to give outstanding improvements in the space footprint and time efficiency of data systems. However, these novel approaches are based on heuristics, thus they lack any guarantees both in their time and space requirements. We propose the Piecewise Geometric Model index (shortly, PGM-index), which achieves guaranteed I/O-optimality in query operations, learns an optimal number of linear models, and its peculiar recursive construction makes it a purely learned data structure, rather than a hybrid of traditional and learned indexes (such as RMI and FITing-tree). We show that the PGM-index improves the space of the FITing-tree by 63.3% and of the B-tree by more than four orders of magnitude, while achieving their same or even better query time efficiency. We complement this result by proposing three variants of the PGM-index. First, we design a compressed PGM-index that further reduces its space footprint by exploiting the repetitiveness at the level of the learned linear models it is composed of. Second, we design a PGM-index that adapts itself to the distribution of the queries, thus resulting in the first known distribution-aware learned index to date. Finally, given its flexibility in the offered space-time trade-offs, we propose the multicriteria PGM-index that efficiently auto-tune itself in a few seconds over hundreds of millions of keys to the possibly evolving space-time constraints imposed by the application of use. We remark to the reader that this paper is an extended and improved version of our previous paper titled "Superseding traditional indexes by orchestrating learning and geometry" (arXiv:1903.00507).