 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Learning of Fast Matrix Multiplication Algorithms: A StrassenNet Approach
Feb 25, 2026Fast matrix multiplication can be described as searching for low-rank decompositions of the matrix--multiplication tensor. We design a neural architecture, \textsc{StrassenNet}, which reproduces the Strassen algorithm for $2\times 2$ multiplication. Across many independent runs the network always converges to a rank-$7$ tensor, thus numerically recovering Strassen's optimal algorithm. We then train the same architecture on $3\times 3$ multiplication with rank $r\in\{19,\dots,23\}$. Our experiments reveal a clear numerical threshold: models with $r=23$ attain significantly lower validation error than those with $r\le 22$, suggesting that $r=23$ could actually be the smallest effective rank of the matrix multiplication tensor $3\times 3$. We also sketch an extension of the method to border-rank decompositions via an $\varepsilon$--parametrisation and report preliminary results consistent with the known bounds for the border rank of the $3\times 3$ matrix--multiplication tensor.
Who Made This? Fake Detection and Source Attribution with Diffusion Features
Oct 31, 2025



The rapid progress of generative diffusion models has enabled the creation of synthetic images that are increasingly difficult to distinguish from real ones, raising concerns about authenticity, copyright, and misinformation. Existing supervised detectors often struggle to generalize across unseen generators, requiring extensive labeled data and frequent retraining. We introduce FRIDA (Fake-image Recognition and source Identification via Diffusion-features Analysis), a lightweight framework that leverages internal activations from a pre-trained diffusion model for deepfake detection and source generator attribution. A k-nearest-neighbor classifier applied to diffusion features achieves state-of-the-art cross-generator performance without fine-tuning, while a compact neural model enables accurate source attribution. These results show that diffusion representations inherently encode generator-specific patterns, providing a simple and interpretable foundation for synthetic image forensics.
A multi-stage GAN for multi-organ chest X-ray image generation and segmentation
Jun 09, 2021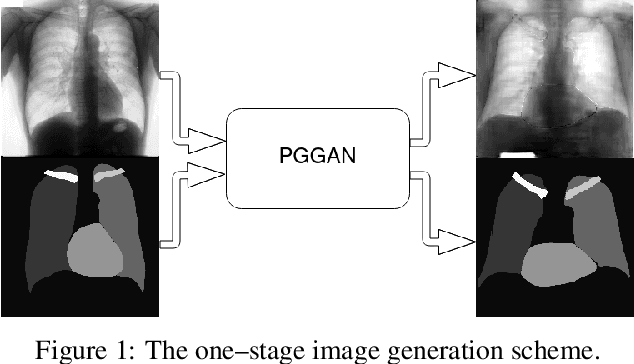
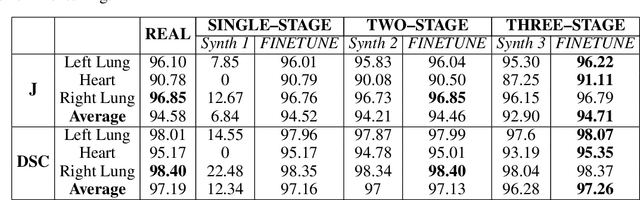
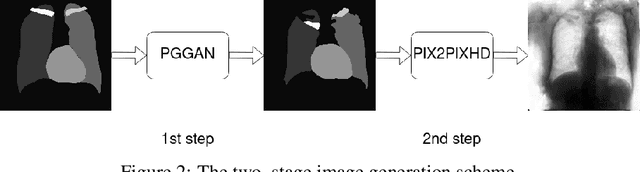
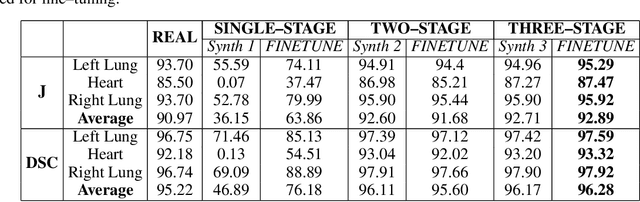
Multi-organ segmentation of X-ray images is of fundamental importance for computer aided diagnosis systems. However, the most advanced semantic segmentation methods rely on deep learning and require a huge amount of labeled images, which are rarely available due to both the high cost of human resources and the time required for labeling. In this paper, we present a novel multi-stage generation algorithm based on Generative Adversarial Networks (GANs) that can produce synthetic images along with their semantic labels and can be used for data augmentation. The main feature of the method is that, unlike other approaches, generation occurs in several stages, which simplifies the procedure and allows it to be used on very small datasets. The method has been evaluated on the segmentation of chest radiographic images, showing promising results. The multistage approach achieves state-of-the-art and, when very few images are used to train the GANs, outperforms the corresponding single-stage approach.
Deep Dynamic Factor Models
Jul 23, 2020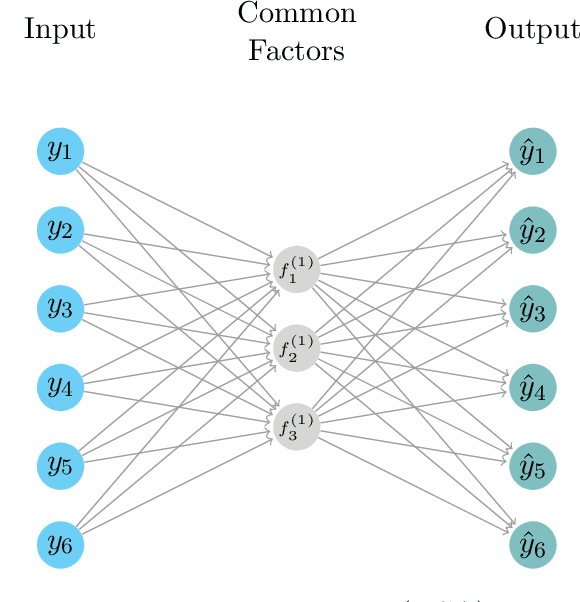

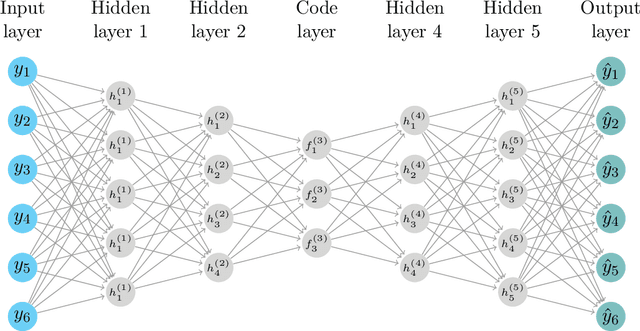
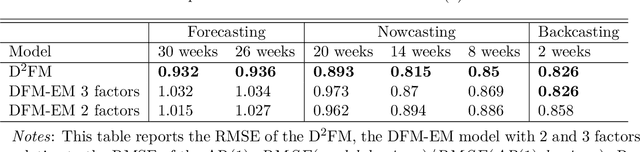
We propose a novel deep neural net framework - that we refer to as Deep Dynamic Factor Model (D2FM) -, to encode the information available, from hundreds of macroeconomic and financial time-series into a handful of unobserved latent states. While similar in spirit to traditional dynamic factor models (DFMs), differently from those, this new class of models allows for nonlinearities between factors and observables due to the deep neural net structure. However, by design, the latent states of the model can still be interpreted as in a standard factor model. In an empirical application to the forecast and nowcast of economic conditions in the US, we show the potential of this framework in dealing with high dimensional, mixed frequencies and asynchronously published time series data. In a fully real-time out-of-sample exercise with US data, the D2FM improves over the performances of a state-of-the-art DFM.
Weak Supervision for Generating Pixel-Level Annotations in Scene Text Segmentation
Nov 19, 2019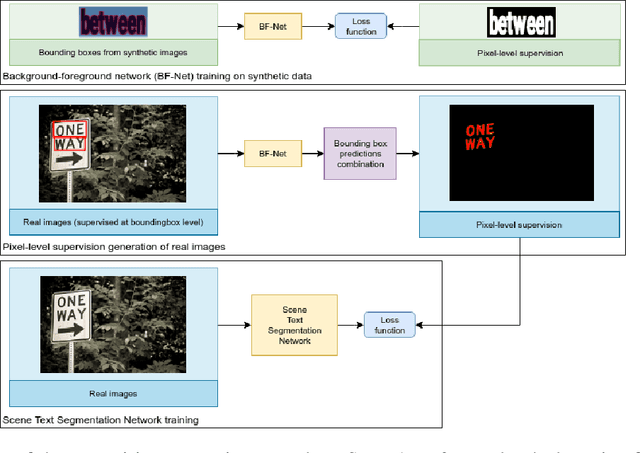


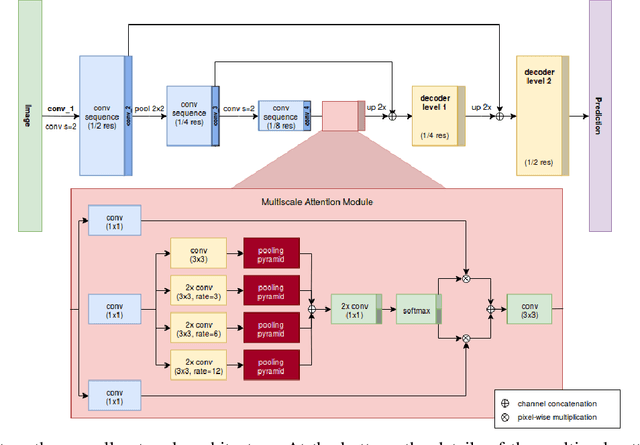
Providing pixel-level supervisions for scene text segmentation is inherently difficult and costly, so that only few small datasets are available for this task. To face the scarcity of training data, previous approaches based on Convolutional Neural Networks (CNNs) rely on the use of a synthetic dataset for pre-training. However, synthetic data cannot reproduce the complexity and variability of natural images. In this work, we propose to use a weakly supervised learning approach to reduce the domain-shift between synthetic and real data. Leveraging the bounding-box supervision of the COCO-Text and the MLT datasets, we generate weak pixel-level supervisions of real images. In particular, the COCO-Text-Segmentation (COCO_TS) and the MLT-Segmentation (MLT_S) datasets are created and released. These two datasets are used to train a CNN, the Segmentation Multiscale Attention Network (SMANet), which is specifically designed to face some peculiarities of the scene text segmentation task. The SMANet is trained end-to-end on the proposed datasets, and the experiments show that COCO_TS and MLT_S are a valid alternative to synthetic images, allowing to use only a fraction of the training samples and improving significantly the performances.
A Two Stage GAN for High Resolution Retinal Image Generation and Segmentation
Jul 29, 2019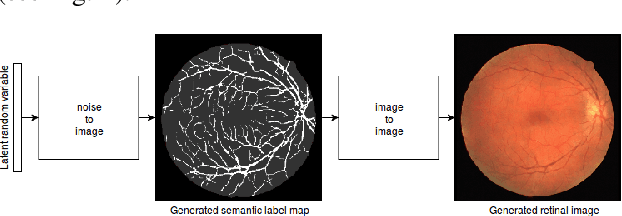
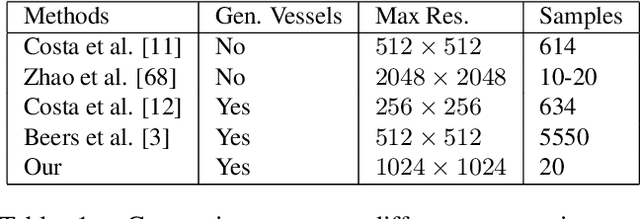
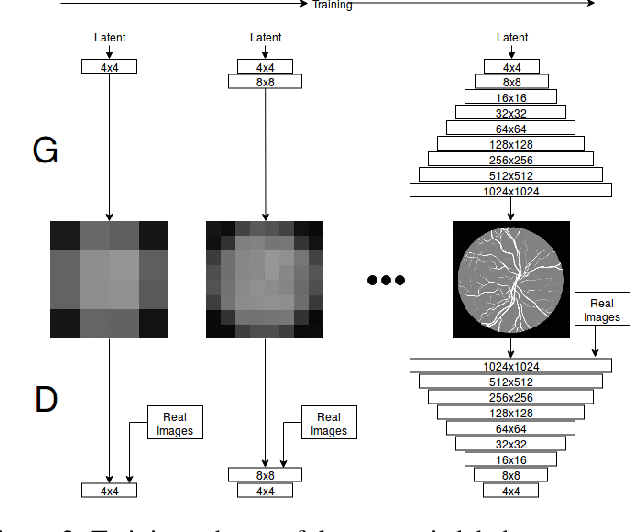
In recent years, the use of deep learning is becoming increasingly popular in computer vision. However, the effective training of deep architectures usually relies on huge sets of annotated data. This is critical in the medical field where it is difficult and expensive to obtain annotated images. In this paper, we use Generative Adversarial Networks (GANs) for synthesizing high quality retinal images, along with the corresponding semantic label-maps, to be used instead of real images during the training process. Differently from other previous proposals, we suggest a two step approach: first, a progressively growing GAN is trained to generate the semantic label-maps, which describe the blood vessel structure (i.e. vasculature); second, an image-to-image translation approach is used to obtain realistic retinal images from the generated vasculature. By using only a handful of training samples, our approach generates realistic high resolution images, that can be effectively used to enlarge small available datasets. Comparable results have been obtained employing the generated images in place of real data during training. The practical viability of the proposed approach has been demonstrated by applying it on two well established benchmark sets for retinal vessel segmentation, both containing a very small number of training samples. Our method obtained better performances with respect to state-of-the-art techniques.
COCO_TS Dataset: Pixel-level Annotations Based on Weak Supervision for Scene Text Segmentation
Apr 02, 2019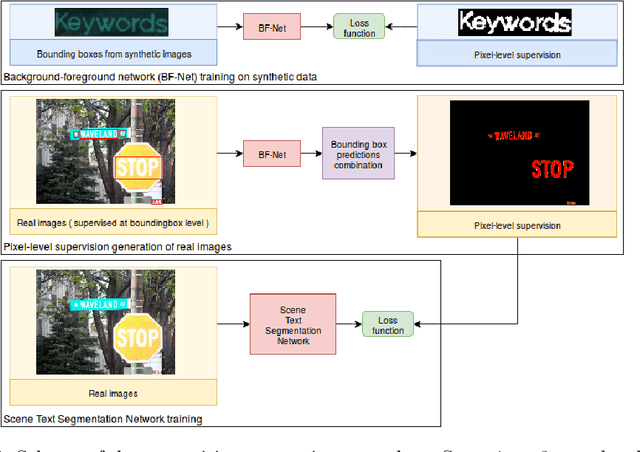


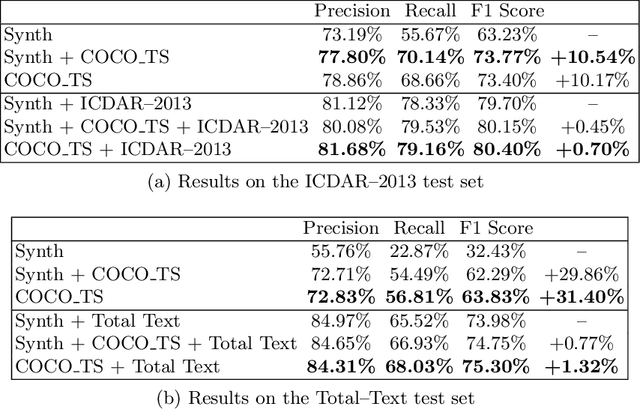
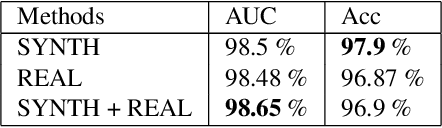
The absence of large scale datasets with pixel-level supervisions is a significant obstacle for the training of deep convolutional networks for scene text segmentation. For this reason, synthetic data generation is normally employed to enlarge the training dataset. Nonetheless, synthetic data cannot reproduce the complexity and variability of natural images. In this paper, a weakly supervised learning approach is used to reduce the shift between training on real and synthetic data. Pixel-level supervisions for a text detection dataset (i.e. where only bounding-box annotations are available) are generated. In particular, the COCO-Text-Segmentation (COCO_TS) dataset, which provides pixel-level supervisions for the COCO-Text dataset, is created and released. The generated annotations are used to train a deep convolutional neural network for semantic segmentation. Experiments show that the proposed dataset can be used instead of synthetic data, allowing us to use only a fraction of the training samples and significantly improving the performances.