 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two Stage GAN for High Resolution Retinal Image Generation and Segmentation
Jul 29, 2019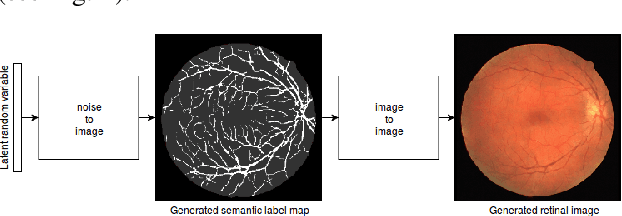
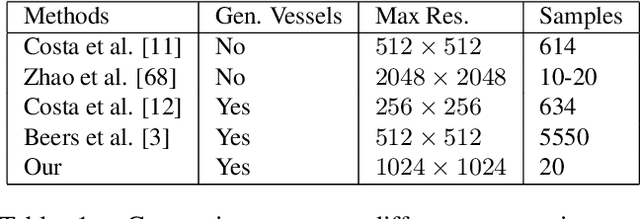
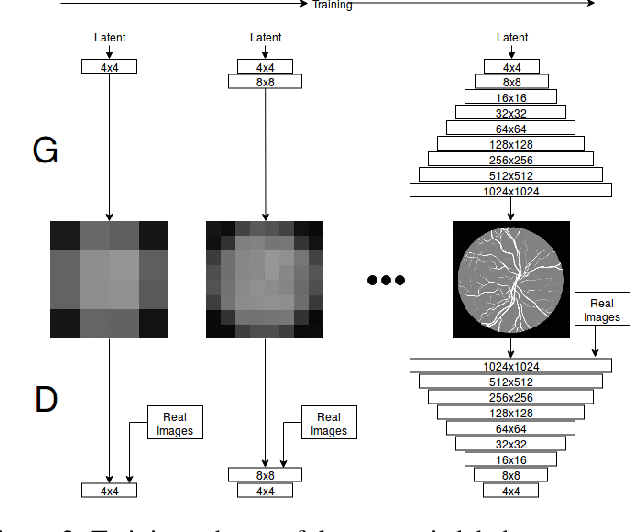
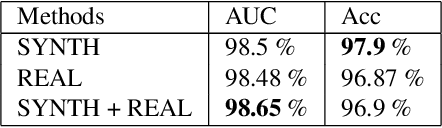
In recent years, the use of deep learning is becoming increasingly popular in computer vision. However, the effective training of deep architectures usually relies on huge sets of annotated data. This is critical in the medical field where it is difficult and expensive to obtain annotated images. In this paper, we use Generative Adversarial Networks (GANs) for synthesizing high quality retinal images, along with the corresponding semantic label-maps, to be used instead of real images during the training process. Differently from other previous proposals, we suggest a two step approach: first, a progressively growing GAN is trained to generate the semantic label-maps, which describe the blood vessel structure (i.e. vasculature); second, an image-to-image translation approach is used to obtain realistic retinal images from the generated vasculature. By using only a handful of training samples, our approach generates realistic high resolution images, that can be effectively used to enlarge small available datasets. Comparable results have been obtained employing the generated images in place of real data during training. The practical viability of the proposed approach has been demonstrated by applying it on two well established benchmark sets for retinal vessel segmentation, both containing a very small number of training samples. Our method obtained better performances with respect to state-of-the-art techniques.