 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Supervision for Generating Pixel-Level Annotations in Scene Text Segmentation
Paper and Code
Nov 19, 2019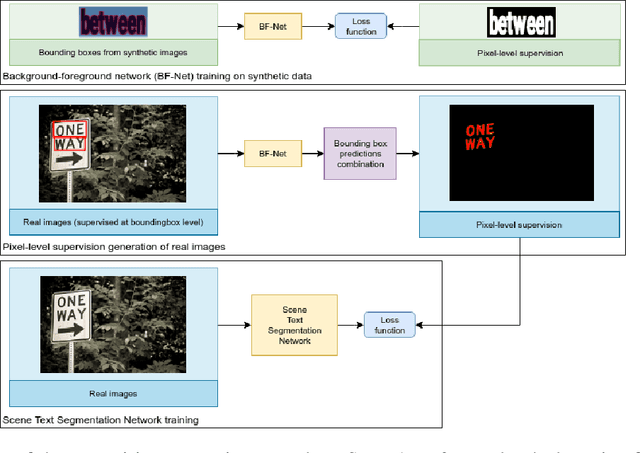


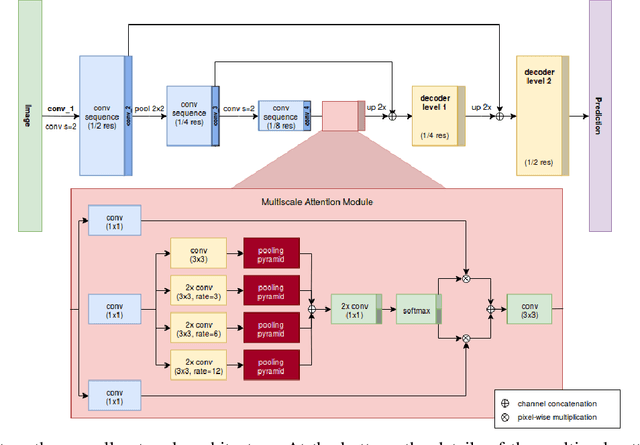
Providing pixel-level supervisions for scene text segmentation is inherently difficult and costly, so that only few small datasets are available for this task. To face the scarcity of training data, previous approaches based on Convolutional Neural Networks (CNNs) rely on the use of a synthetic dataset for pre-training. However, synthetic data cannot reproduce the complexity and variability of natural images. In this work, we propose to use a weakly supervised learning approach to reduce the domain-shift between synthetic and real data. Leveraging the bounding-box supervision of the COCO-Text and the MLT datasets, we generate weak pixel-level supervisions of real images. In particular, the COCO-Text-Segmentation (COCO_TS) and the MLT-Segmentation (MLT_S) datasets are created and released. These two datasets are used to train a CNN, the Segmentation Multiscale Attention Network (SMANet), which is specifically designed to face some peculiarities of the scene text segmentation task. The SMANet is trained end-to-end on the proposed datasets, and the experiments show that COCO_TS and MLT_S are a valid alternative to synthetic images, allowing to use only a fraction of the training samples and improving significantly the performances.