 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Residual Dense U-Net for Resolution Enhancement in Accelerated MRI Acquisition
Jan 13, 2020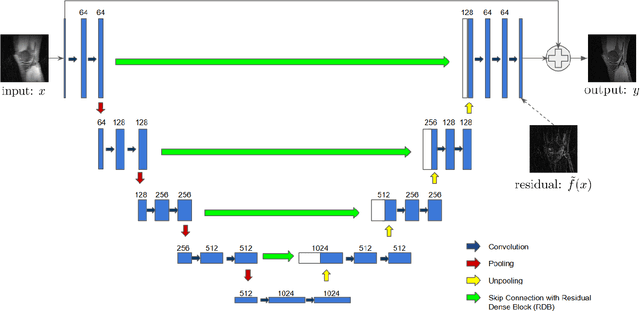

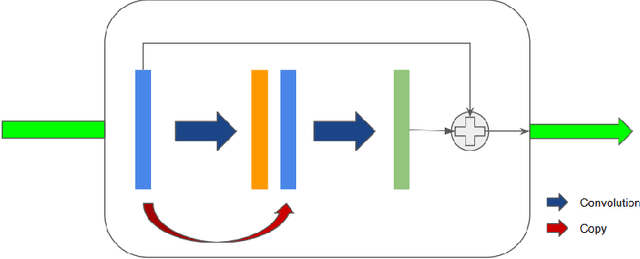
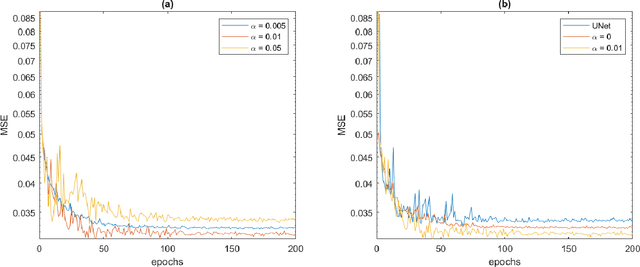
Typical Magnetic Resonance Imaging (MRI) scan may take 20 to 60 minutes. Reducing MRI scan time is beneficial for both patient experience and cost considerations. Accelerated MRI scan may be achieved by acquiring less amount of k-space data (down-sampling in the k-space). However, this leads to lower resolution and aliasing artifacts for the reconstructed images. There are many existing approaches for attempting to reconstruct high-quality images from down-sampled k-space data, with varying complexity and performance. In recent years, deep-learning approaches have been proposed for this task, and promising results have been reported. Still, the problem remains challenging especially because of the high fidelity requirement in most medical applications employing reconstructed MRI images. In this work, we propose a deep-learning approach, aiming at reconstructing high-quality images from accelerated MRI acquisition. Specifically, we use Convolutional Neural Network (CNN) to learn the differences between the aliased images and the original images, employing a U-Net-like architecture. Further, a micro-architecture termed Residual Dense Block (RDB) is introduced for learning a better feature representation than the plain U-Net. Considering the peculiarity of the down-sampled k-space data, we introduce a new term to the loss function in learning, which effectively employs the given k-space data during training to provide additional regularization on the update of the network weights. To evaluate the proposed approach, we compare it with other state-of-the-art methods. In both visual inspection and evaluation using standard metrics, the proposed approach is able to deliver improved performance, demonstrating its potential for providing an effective solution.
Mean Local Group Average Precision : A New Performance Metric for Hashing-based Retrieval
Nov 24, 2018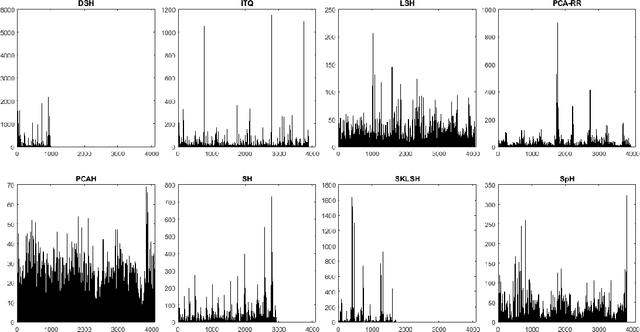

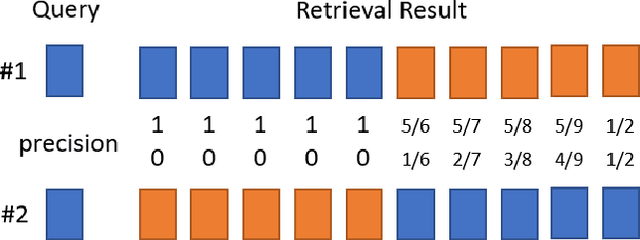
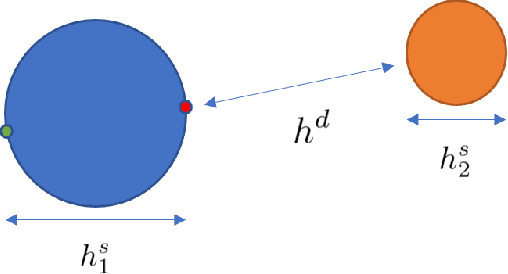
The research on hashing techniques for visual data is gaining increased attention in recent years due to the need for compact representations supporting efficient search/retrieval in large-scale databases such as online images. Among many possibilities, Mean Average Precision(mAP) has emerged as the dominant performance metric for hashing-based retrieval. One glaring shortcoming of mAP is its inability in balancing retrieval accuracy and utilization of hash codes: pushing a system to attain higher mAP will inevitably lead to poorer utilization of the hash codes. Poor utilization of the hash codes hinders good retrieval because of increased collision of samples in the hash space. This means that a model giving a higher mAP values does not necessarily do a better job in retrieval. In this paper, we introduce a new metric named Mean Local Group Average Precision (mLGAP) for better evaluation of the performance of hashing-based retrieval. The new metric provides a retrieval performance measure that also reconciles the utilization of hash codes, leading to a more practically meaningful performance metric than conventional ones like mAP. To this end, we start by mathematical analysis of the deficiencies of mAP for hashing-based retrieval. We then propose mLGAP and show why it is more appropriate for hashing-based retrieval. Experiments on image retrieval are used to demonstrate the effectiveness of the proposed metric.
Training Neural Networks by Using Power Linear Units (PoLUs)
Feb 01, 2018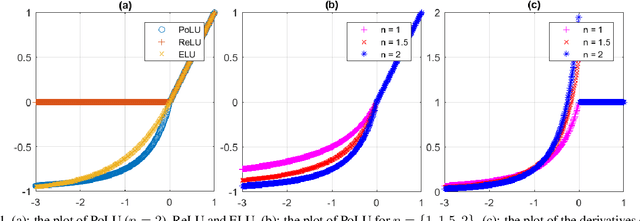


In this paper, we introduce "Power Linear Unit" (PoLU) which increases the nonlinearity capacity of a neural network and thus helps improving its performance. PoLU adopts several advantages of previously proposed activation functions. First, the output of PoLU for positive inputs is designed to be identity to avoid the gradient vanishing problem. Second, PoLU has a non-zero output for negative inputs such that the output mean of the units is close to zero, hence reducing the bias shift effect. Thirdly, there is a saturation on the negative part of PoLU, which makes it more noise-robust for negative inputs. Furthermore, we prove that PoLU is able to map more portions of every layer's input to the same space by using the power function and thus increases the number of response regions of the neural network. We use image classification for comparing our proposed activation function with others. In the experiments, MNIST, CIFAR-10, CIFAR-100, Street View House Numbers (SVHN) and ImageNet are used as benchmark datasets. The neural networks we implemented include widely-used ELU-Network, ResNet-50, and VGG16, plus a couple of shallow networks. Experimental results show that our proposed activation function outperforms other state-of-the-art models with most networks.