 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Contextually Aggregate Multi-Source Supervision for Sequence Labeling
Oct 09, 2019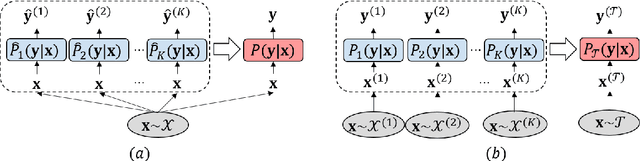
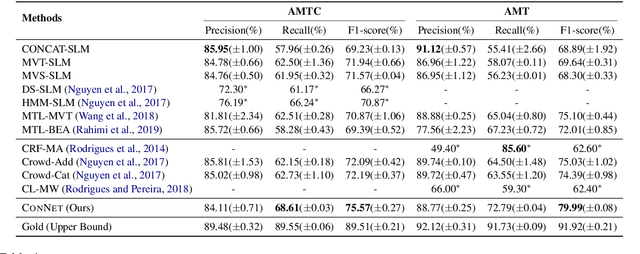
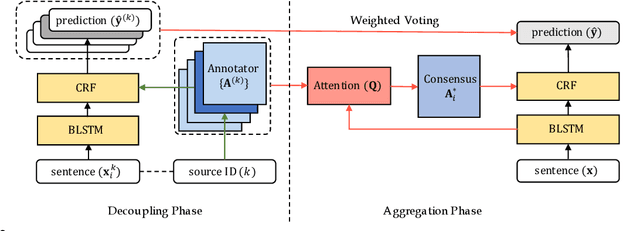
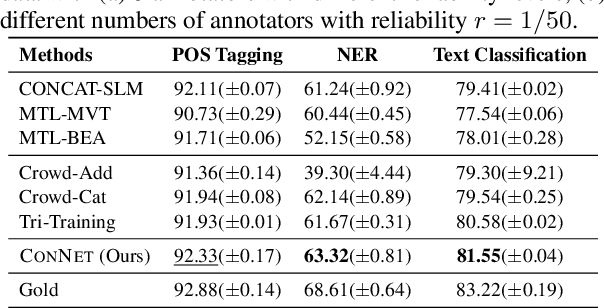
Sequence labeling is a fundamental framework for various natural language processing problems. Its performance is largely influenced by the annotation quality and quantity in supervised learning scenarios. In many cases, ground truth labels are costly and time-consuming to collect or even non-existent, while imperfect ones could be easily accessed or transferred from different domains. In this paper, we propose a novel framework named consensus Network (ConNet) to conduct training with imperfect annotations from multiple sources. It learns the representation for every weak supervision source and dynamically aggregates them by a context-aware attention mechanism. Finally, it leads to a model reflecting the consensus among multiple sources. We evaluate the proposed framework in two practical settings of multisource learning: learning with crowd annotations and unsupervised cross-domain model adaptation. Extensive experimental results show that our model achieves significant improvements over existing methods in both settings.