 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-VLA: Vision-Language-Action Model-Based System for Bimanual Robotic Dexterous Manipulations
May 09, 2024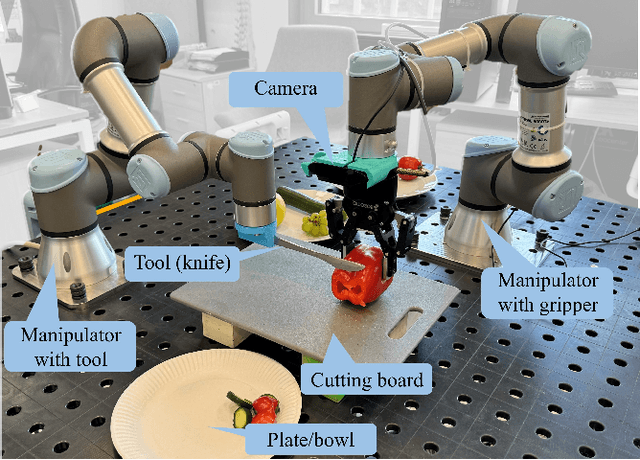

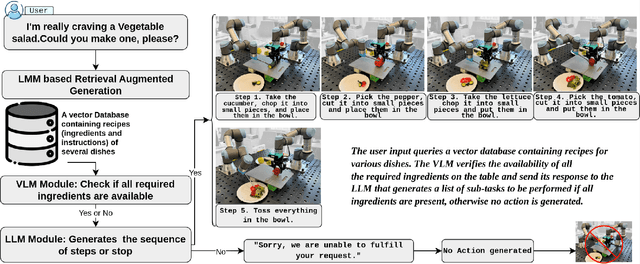

This research introduces the Bi-VLA (Vision-Language-Action) model, a novel system designed for bimanual robotic dexterous manipulations that seamlessly integrate vision, language understanding, and physical action. The system's functionality was evaluated through a set of household tasks, including the preparation of a desired salad upon human request. Bi-VLA demonstrates the ability to interpret complex human instructions, perceive and understand the visual context of ingredients, and execute precise bimanual actions to assemble the requested salad. Through a series of experiments, we evaluate the system's performance in terms of accuracy, efficiency, and adaptability to various salad recipes and human preferences. Our results indicate a high success rate of 100% in generating the correct executable code by the Language module from the user-requested tasks. The Vision Module achieved a success rate of 96.06% in detecting specific ingredients and an 83.4% success rate in detecting a list of multiple ingredients.