 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Image Encoding in Automated Chest X-Ray Report Generation
Nov 24, 2022

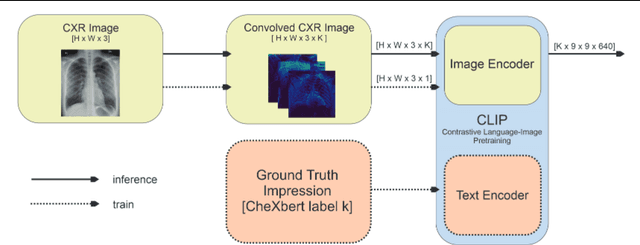

Chest X-ray is one of the most popular medical imaging modalities due to its accessibility and effectiveness. However, there is a chronic shortage of well-trained radiologists who can interpret these images and diagnose the patient's condition. Therefore, automated radiology report generation can be a very helpful tool in clinical practice. A typical report generation workflow consists of two main steps: (i) encoding the image into a latent space and (ii) generating the text of the report based on the latent image embedding. Many existing report generation techniques use a standard convolutional neural network (CNN) architecture for image encoding followed by a Transformer-based decoder for medical text generation. In most cases, CNN and the decoder are trained jointly in an end-to-end fashion. In this work, we primarily focus on understanding the relative importance of encoder and decoder components. Towards this end, we analyze four different image encoding approaches: direct, fine-grained, CLIP-based, and Cluster-CLIP-based encodings in conjunction with three different decoders on the large-scale MIMIC-CXR dataset. Among these encoders, the cluster CLIP visual encoder is a novel approach that aims to generate more discriminative and explainable representations. CLIP-based encoders produce comparable results to traditional CNN-based encoders in terms of NLP metrics, while fine-grained encoding outperforms all other encoders both in terms of NLP and clinical accuracy metrics, thereby validating the importance of image encoder to effectively extract semantic information. GitHub repository: https://github.com/mudabek/encoding-cxr-report-gen
AI for Porosity and Permeability Prediction from Geologic Core X-Ray Micro-Tomography
May 26, 2022
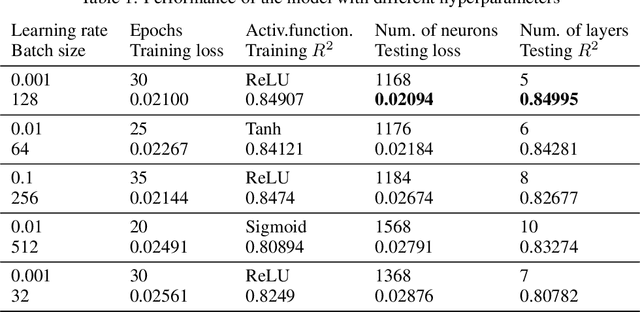
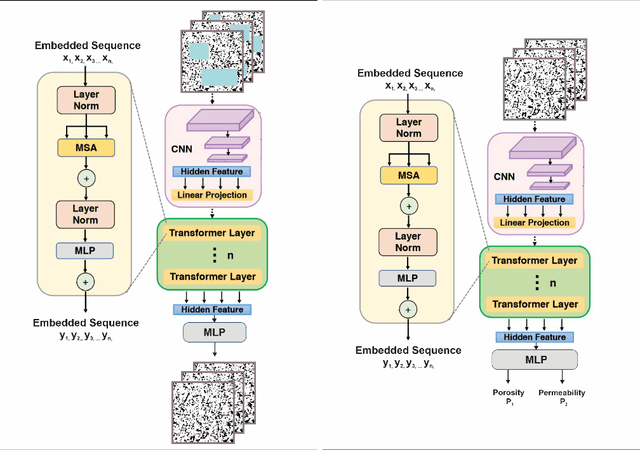

Geologic cores are rock samples that are extracted from deep under the ground during the well drilling process. They are used for petroleum reservoirs' performance characterization. Traditionally, physical studies of cores are carried out by the means of manual time-consuming experiments. With the development of deep learning, scientists actively started working on developing machine-learning-based approaches to identify physical properties without any manual experiments. Several previous works used machine learning to determine the porosity and permeability of the rocks, but either method was inaccurate or computationally expensive. We are proposing to use self-supervised pretraining of the very small CNN-transformer-based model to predict the physical properties of the rocks with high accuracy in a time-efficient manner. We show that this technique prevents overfitting even for extremely small datasets.
Automatic Segmentation of Head and Neck Tumor: How Powerful Transformers Are?
Jan 17, 2022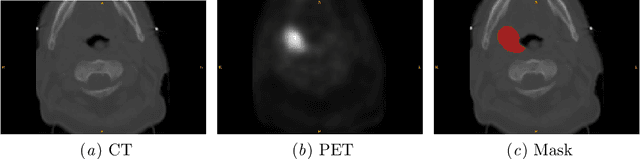

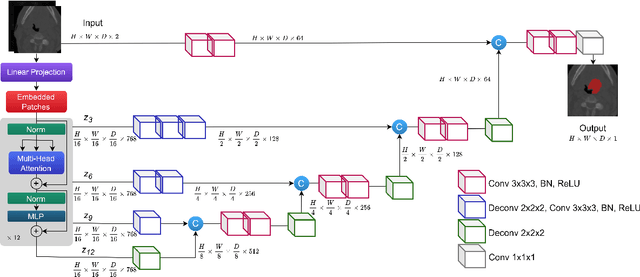
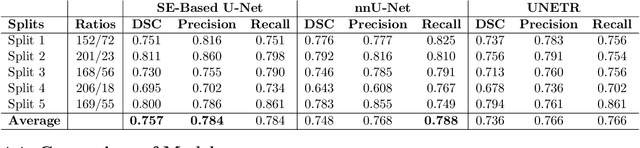
Cancer is one of the leading causes of death worldwide, and head and neck (H&N) cancer is amongst the most prevalent types. Positron emission tomography and computed tomography are used to detect and segment the tumor region. Clinically, tumor segmentation is extensively time-consuming and prone to error. Machine learning, and deep learning in particular, can assist to automate this process, yielding results as accurate as the results of a clinician. In this research study, we develop a vision transformers-based method to automatically delineate H&N tumor, and compare its results to leading convolutional neural network (CNN)-based models. We use multi-modal data of CT and PET scans to do this task. We show that the selected transformer-based model can achieve results on a par with CNN-based ones. With cross validation, the model achieves a mean dice similarity coefficient of 0.736, mean precision of 0.766 and mean recall of 0.766. This is only 0.021 less than the 2020 competition winning model in terms of the DSC score. This indicates that the exploration of transformer-based models is a promising research area.