 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Image Encoding in Automated Chest X-Ray Report Generation
Paper and Code


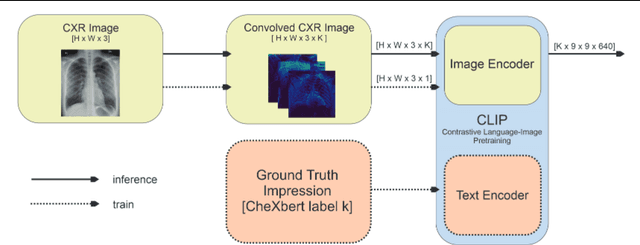

Chest X-ray is one of the most popular medical imaging modalities due to its accessibility and effectiveness. However, there is a chronic shortage of well-trained radiologists who can interpret these images and diagnose the patient's condition. Therefore, automated radiology report generation can be a very helpful tool in clinical practice. A typical report generation workflow consists of two main steps: (i) encoding the image into a latent space and (ii) generating the text of the report based on the latent image embedding. Many existing report generation techniques use a standard convolutional neural network (CNN) architecture for image encoding followed by a Transformer-based decoder for medical text generation. In most cases, CNN and the decoder are trained jointly in an end-to-end fashion. In this work, we primarily focus on understanding the relative importance of encoder and decoder components. Towards this end, we analyze four different image encoding approaches: direct, fine-grained, CLIP-based, and Cluster-CLIP-based encodings in conjunction with three different decoders on the large-scale MIMIC-CXR dataset. Among these encoders, the cluster CLIP visual encoder is a novel approach that aims to generate more discriminative and explainable representations. CLIP-based encoders produce comparable results to traditional CNN-based encoders in terms of NLP metrics, while fine-grained encoding outperforms all other encoders both in terms of NLP and clinical accuracy metrics, thereby validating the importance of image encoder to effectively extract semantic information. GitHub repository: https://github.com/mudabek/encoding-cxr-report-gen