 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-semantics interplay in complex networks and its effects on the predictability of similarity in texts
Mar 02, 2013



There are different ways to define similarity for grouping similar texts into clusters, as the concept of similarity may depend on the purpose of the task. For instance, in topic extraction similar texts mean those within the same semantic field, whereas in author recognition stylistic features should be considered. In this study, we introduce ways to classify texts employing concepts of complex networks, which may be able to capture syntactic, semantic and even pragmatic features. The interplay between the various metrics of the complex networks is analyzed with three applications, namely identification of machine translation (MT) systems, evaluation of quality of machine translated texts and authorship recognition. We shall show that topological features of the networks representing texts can enhance the ability to identify MT systems in particular cases. For evaluating the quality of MT texts, on the other hand, high correlation was obtained with methods capable of capturing the semantics. This was expected because the golden standards used are themselves based on word co-occurrence. Notwithstanding, the Katz similarity, which involves semantic and structure in the comparison of texts, achieved the highest correlation with the NIST measurement, indicating that in some cases the combination of both approaches can improve the ability to quantify quality in MT. In authorship recognition, again the topological features were relevant in some contexts, though for the books and authors analyzed good results were obtained with semantic features as well. Because hybrid approaches encompassing semantic and topological features have not been extensively used, we believe that the methodology proposed here may be useful to enhance text classification considerably, as it combines well-established strategies.
Probing the statistical properties of unknown texts: application to the Voynich Manuscript
Mar 02, 2013
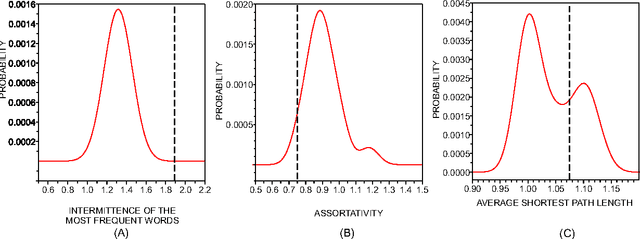
While the use of statistical physics methods to analyze large corpora has been useful to unveil many patterns in texts, no comprehensive investigation has been performed investigating the properties of statistical measurements across different languages and texts. In this study we propose a framework that aims at determining if a text is compatible with a natural language and which languages are closest to it, without any knowledge of the meaning of the words. The approach is based on three types of statistical measurements, i.e. obtained from first-order statistics of word properties in a text, from the topology of complex networks representing text, and from intermittency concepts where text is treated as a time series. Comparative experiments were performed with the New Testament in 15 different languages and with distinct books in English and Portuguese in order to quantify the dependency of the different measurements on the language and on the story being told in the book. The metrics found to be informative in distinguishing real texts from their shuffled versions include assortativity, degree and selectivity of words. As an illustration, we analyze an undeciphered medieval manuscript known as the Voynich Manuscript. We show that it is mostly compatible with natural languages and incompatible with random texts. We also obtain candidates for key-words of the Voynich Manuscript which could be helpful in the effort of deciphering it. Because we were able to identify statistical measurements that are more dependent on the syntax than on the semantics, the framework may also serve for text analysis in language-dependent applications.
Complex networks analysis of language complexity
Feb 19, 2013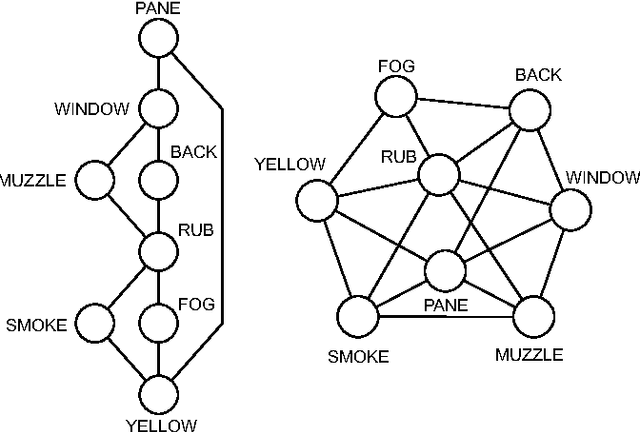
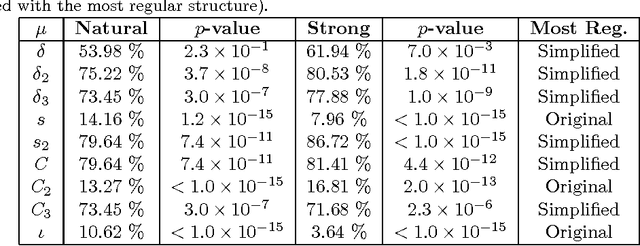
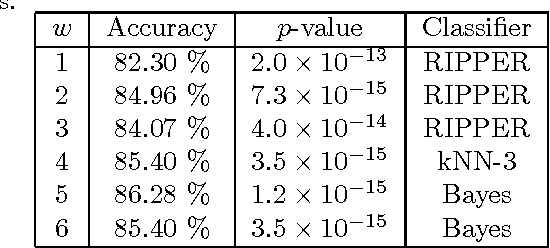
Methods from statistical physics, such as those involving complex networks, have been increasingly used in quantitative analysis of linguistic phenomena. In this paper, we represented pieces of text with different levels of simplification in co-occurrence networks and found that topological regularity correlated negatively with textual complexity. Furthermore, in less complex texts the distance between concepts, represented as nodes, tended to decrease. The complex networks metrics were treated with multivariate pattern recognition techniques, which allowed us to distinguish between original texts and their simplified versions. For each original text, two simplified versions were generated manually with increasing number of simplification operations. As expected, distinction was easier for the strongly simplified versions, where the most relevant metrics were node strength, shortest paths and diversity. Also, the discrimination of complex texts was improved with higher hierarchical network metrics, thus pointing to the usefulness of considering wider contexts around the concepts. Though the accuracy rate in the distinction was not as high as in methods using deep linguistic knowledge, the complex network approach is still useful for a rapid screening of texts whenever assessing complexity is essential to guarantee accessibility to readers with limited reading ability
* The Supplementary Information (SI) is available from https://dl.dropbox.com/u/2740286/supplementary.pdf
Unveiling the relationship between complex networks metrics and word senses
Feb 18, 2013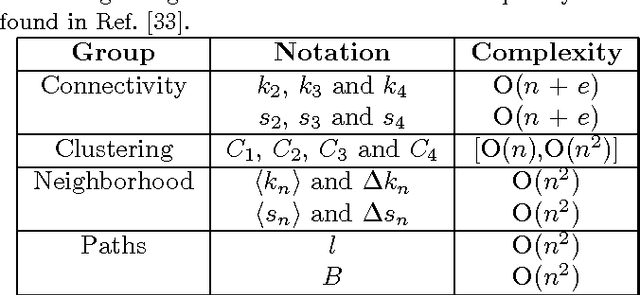
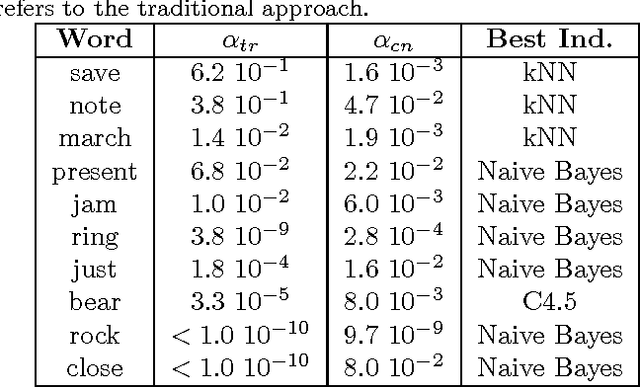
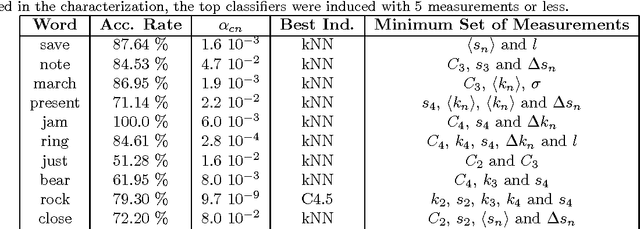

The automatic disambiguation of word senses (i.e., the identification of which of the meanings is used in a given context for a word that has multiple meanings) is essential for such applications as machine translation and information retrieval, and represents a key step for developing the so-called Semantic Web. Humans disambiguate words in a straightforward fashion, but this does not apply to computers. In this paper we address the problem of Word Sense Disambiguation (WSD) by treating texts as complex networks, and show that word senses can be distinguished upon characterizing the local structure around ambiguous words. Our goal was not to obtain the best possible disambiguation system, but we nevertheless found that in half of the cases our approach outperforms traditional shallow methods. We show that the hierarchical connectivity and clustering of words are usually the most relevant features for WSD. The results reported here shine light on the relationship between semantic and structural parameters of complex networks. They also indicate that when combined with traditional techniques the complex network approach may be useful to enhance the discrimination of senses in large texts
* The Supplementary Information (SI) is available from http://dl.dropbox.com/u/2740286/epl_SI.pdf
Comparing intermittency and network measurements of words and their dependency on authorship
Dec 28, 2011



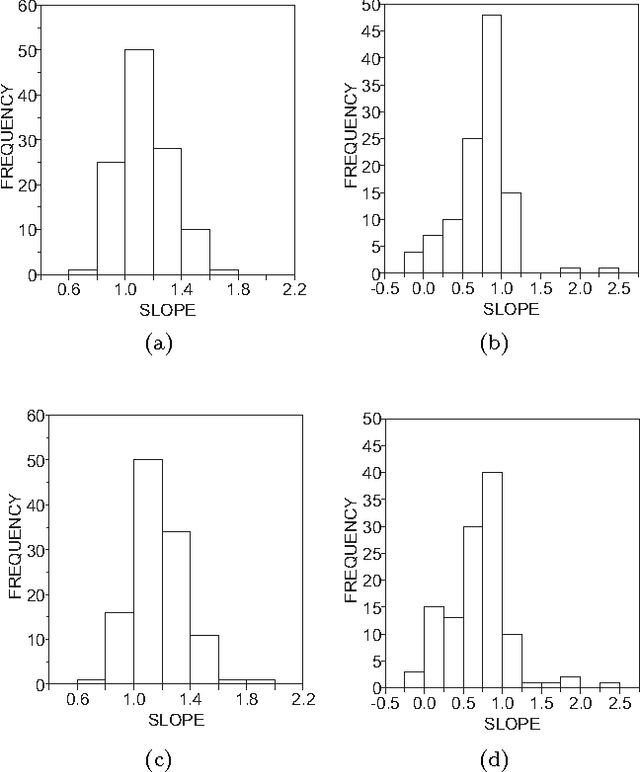
Many features from texts and languages can now be inferred from statistical analyses using concepts from complex networks and dynamical systems. In this paper we quantify how topological properties of word co-occurrence networks and intermittency (or burstiness) in word distribution depend on the style of authors. Our database contains 40 books from 8 authors who lived in the 19th and 20th centuries, for which the following network measurements were obtained: clustering coefficient, average shortest path lengths, and betweenness. We found that the two factors with stronger dependency on the authors were the skewness in the distribution of word intermittency and the average shortest paths. Other factors such as the betweeness and the Zipf's law exponent show only weak dependency on authorship. Also assessed was the contribution from each measurement to authorship recognition using three machine learning methods. The best performance was a ca. 65 % accuracy upon combining complex network and intermittency features with the nearest neighbor algorithm. From a detailed analysis of the interdependence of the various metrics it is concluded that the methods used here are complementary for providing short- and long-scale perspectives of texts, which are useful for applications such as identification of topical words and information retrieval.