 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex networks analysis of language complexity
Paper and Code
Feb 19, 2013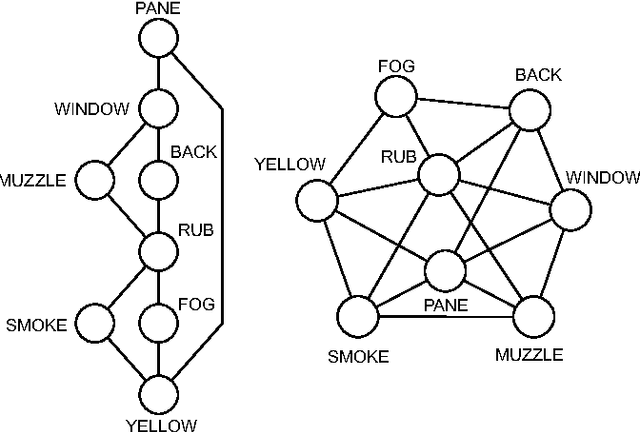
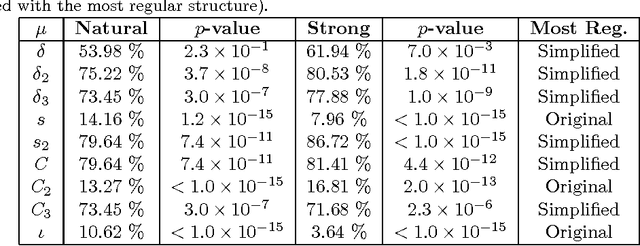
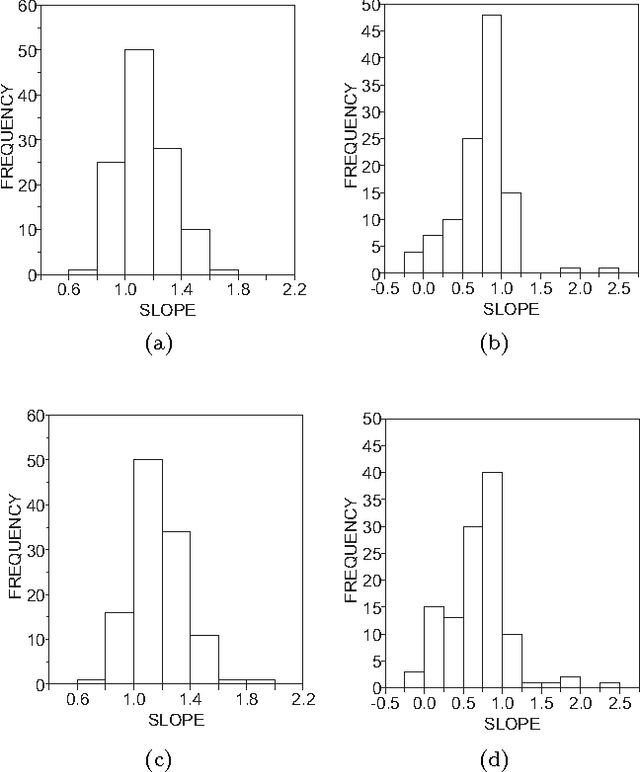
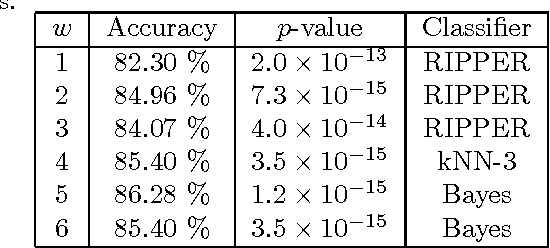
Methods from statistical physics, such as those involving complex networks, have been increasingly used in quantitative analysis of linguistic phenomena. In this paper, we represented pieces of text with different levels of simplification in co-occurrence networks and found that topological regularity correlated negatively with textual complexity. Furthermore, in less complex texts the distance between concepts, represented as nodes, tended to decrease. The complex networks metrics were treated with multivariate pattern recognition techniques, which allowed us to distinguish between original texts and their simplified versions. For each original text, two simplified versions were generated manually with increasing number of simplification operations. As expected, distinction was easier for the strongly simplified versions, where the most relevant metrics were node strength, shortest paths and diversity. Also, the discrimination of complex texts was improved with higher hierarchical network metrics, thus pointing to the usefulness of considering wider contexts around the concepts. Though the accuracy rate in the distinction was not as high as in methods using deep linguistic knowledge, the complex network approach is still useful for a rapid screening of texts whenever assessing complexity is essential to guarantee accessibility to readers with limited reading ability