 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMatch: Retrieval Enhanced Schema Matching with LLMs
Mar 03, 2024Schema matching is a crucial task in data integration, involving the alignment of a source database schema with a target schema to establish correspondence between their elements. This task is challenging due to textual and semantic heterogeneity, as well as differences in schema sizes. Although machine-learning-based solutions have been explored in numerous studies, they often suffer from low accuracy, require manual mapping of the schemas for model training, or need access to source schema data which might be unavailable due to privacy concerns. In this paper we present a novel method, named ReMatch, for matching schemas using retrieval-enhanced Large Language Models (LLMs). Our method avoids the need for predefined mapping, any model training, or access to data in the source database. In the ReMatch method the tables of the target schema and the attributes of the source schema are first represented as structured passage-based documents. For each source attribute document, we retrieve $J$ documents, representing target schema tables, according to their semantic relevance. Subsequently, we create a prompt for every source table, comprising all its attributes and their descriptions, alongside all attributes from the set of top $J$ target tables retrieved previously. We employ LLMs using this prompt for the matching task, yielding a ranked list of $K$ potential matches for each source attribute. Our experimental results on large real-world schemas demonstrate that ReMatch significantly improves matching capabilities and outperforms other machine learning approaches. By eliminating the requirement for training data, ReMatch becomes a viable solution for real-world scenarios.
Evaluation Methodology for Large Language Models for Multilingual Document Question and Answer
Feb 01, 2024With the widespread adoption of Large Language Models (LLMs), in this paper we investigate the multilingual capability of these models. Our preliminary results show that, translating the native language context, question and answer into a high resource language produced the best results.
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
Dec 10, 2023Large language models (LLMs) encapsulate a vast amount of factual information within their pre-trained weights, as evidenced by their ability to answer diverse questions across different domains. However, this knowledge is inherently limited, relying heavily on the characteristics of the training data. Consequently, using external datasets to incorporate new information or refine the capabilities of LLMs on previously seen information poses a significant challenge. In this study, we compare two common approaches: fine-tuning and retrieval-augmented generation (RAG). We evaluate both approaches on a variety of knowledge-intensive tasks across different topics. Our findings reveal that while fine-tuning offers some improvement, RAG consistently outperforms it, both for existing knowledge encountered during training and entirely new knowledge. Moreover, we find that LLMs struggle to learn new factual information through fine-tuning, and that exposing them to numerous variations of the same fact during training could alleviate this problem.
Predicting Unplanned Readmissions in the Intensive Care Unit: A Multimodality Evaluation
May 14, 2023A hospital readmission is when a patient who was discharged from the hospital is admitted again for the same or related care within a certain period. Hospital readmissions are a significant problem in the healthcare domain, as they lead to increased hospitalization costs, decreased patient satisfaction, and increased risk of adverse outcomes such as infections, medication errors, and even death. The problem of hospital readmissions is particularly acute in intensive care units (ICUs), due to the severity of the patients' conditions, and the substantial risk of complications. Predicting Unplanned Readmissions in ICUs is a challenging task, as it involves analyzing different data modalities, such as static data, unstructured free text, sequences of diagnoses and procedures, and multivariate time-series. Here, we investigate the effectiveness of each data modality separately, then alongside with others, using state-of-the-art machine learning approaches in time-series analysis and natural language processing. Using our evaluation process, we are able to determine the contribution of each data modality, and for the first time in the context of readmission, establish a hierarchy of their predictive value. Additionally, we demonstrate the impact of Temporal Abstractions in enhancing the performance of time-series approaches to readmission prediction. Due to conflicting definitions in the literature, we also provide a clear definition of the term Unplanned Readmission to enhance reproducibility and consistency of future research and to prevent any potential misunderstandings that could result from diverse interpretations of the term. Our experimental results on a large benchmark clinical data set show that Discharge Notes written by physicians, have better capabilities for readmission prediction than all other modalities.
MessageNet: Message Classification using Natural Language Processing and Meta-data
Jan 04, 2023



In this paper we propose a new Deep Learning (DL) approach for message classification. Our method is based on the state-of-the-art Natural Language Processing (NLP) building blocks, combined with a novel technique for infusing the meta-data input that is typically available in messages such as the sender information, timestamps, attached image, audio, affiliations, and more. As we demonstrate throughout the paper, going beyond the mere text by leveraging all available channels in the message, could yield an improved representation and higher classification accuracy. To achieve message representation, each type of input is processed in a dedicated block in the neural network architecture that is suitable for the data type. Such an implementation enables training all blocks together simultaneously, and forming cross channels features in the network. We show in the Experiments Section that in some cases, message's meta-data holds an additional information that cannot be extracted just from the text, and when using this information we achieve better performance. Furthermore, we demonstrate that our multi-modality block approach outperforms other approaches for injecting the meta data to the the text classifier.
Low Latency Privacy Preserving Inference
Dec 27, 2018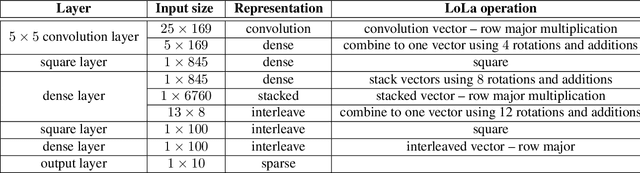
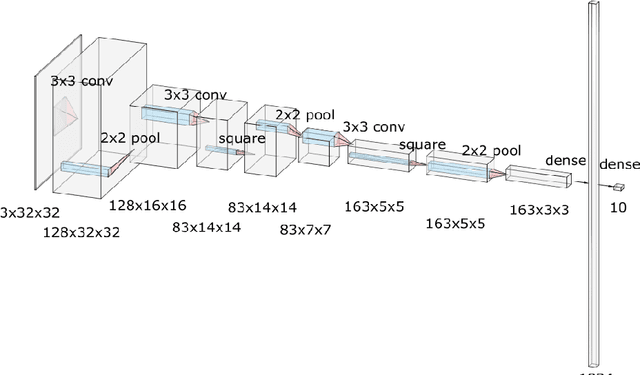
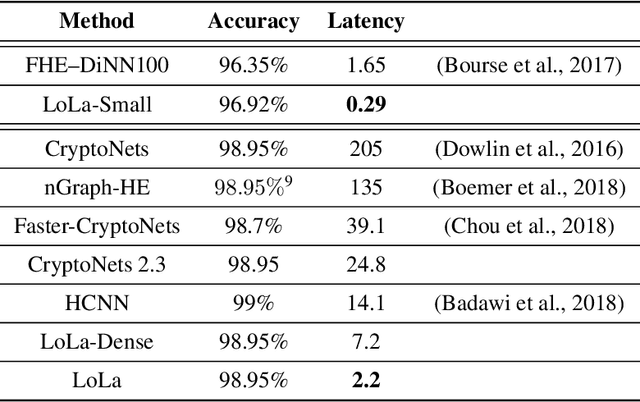
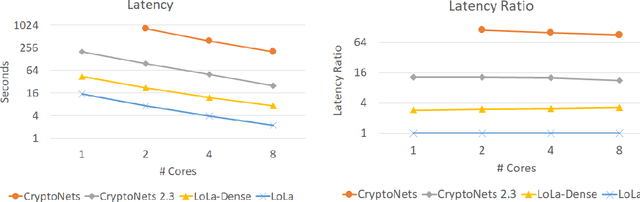
When applying machine learning to sensitive data, one has to balance between accuracy, information leakage, and computational-complexity. Recent studies have shown that Homomorphic Encryption (HE) can be used for protecting against information leakage while applying neural networks. However, this comes with the cost of limiting the width and depth of neural networks that can be used (and hence the accuracy) and with latency of the order of several minutes even for relatively simple networks. In this study we provide two solutions that address these limitations. In the first solution, we present more than $10\times$ improvement in latency and enable inference on wider networks compared to prior attempts with the same level of security. The improved performance is achieved via a collection of methods to better represent the data during the computation. In the second solution, we apply the method of transfer learning to provide private inference services using deep networks with latency less than 0.2 seconds. We demonstrate the efficacy of our methods on several computer vision tasks.
Wavelet Decomposition of Gradient Boosting
May 07, 2018
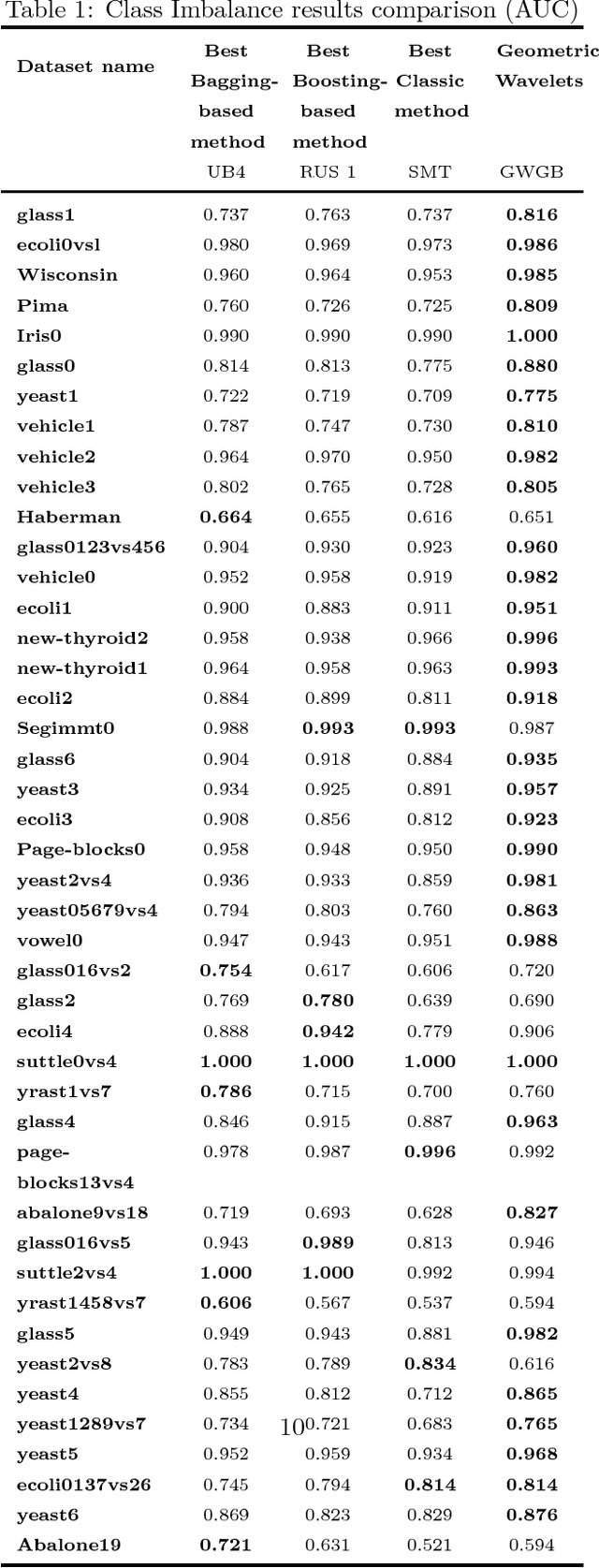
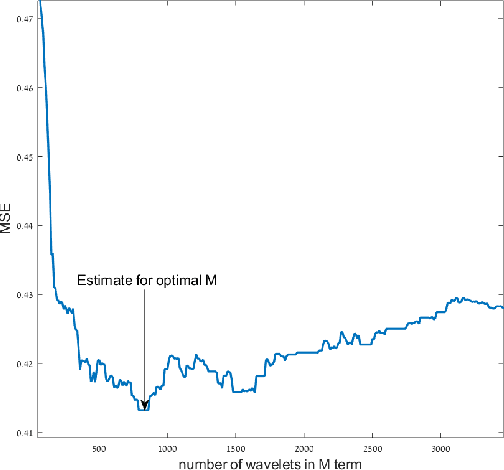
In this paper we introduce a significant improvement to the popular tree-based Stochastic Gradient Boosting algorithm using a wavelet decomposition of the trees. This approach is based on harmonic analysis and approximation theoretical elements, and as we show through extensive experimentation, our wavelet based method generally outperforms existing methods, particularly in difficult scenarios of class unbalance and mislabeling in the training data.
Function space analysis of deep learning representation layers
Oct 09, 2017

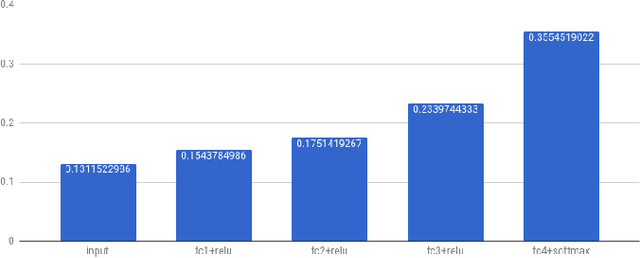
In this paper we propose a function space approach to Representation Learning and the analysis of the representation layers in deep learning architectures. We show how to compute a weak-type Besov smoothness index that quantifies the geometry of the clustering in the feature space. This approach was already applied successfully to improve the performance of machine learning algorithms such as the Random Forest and tree-based Gradient Boosting. Our experiments demonstrate that in well-known and well-performing trained networks, the Besov smoothness of the training set, measured in the corresponding hidden layer feature map representation, increases from layer to layer. We also contribute to the understanding of generalization by showing how the Besov smoothness of the representations, decreases as we add more mis-labeling to the training data. We hope this approach will contribute to the de-mystification of some aspects of deep learning.