 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunction space analysis of deep learning representation layers
Paper and Code
Oct 09, 2017

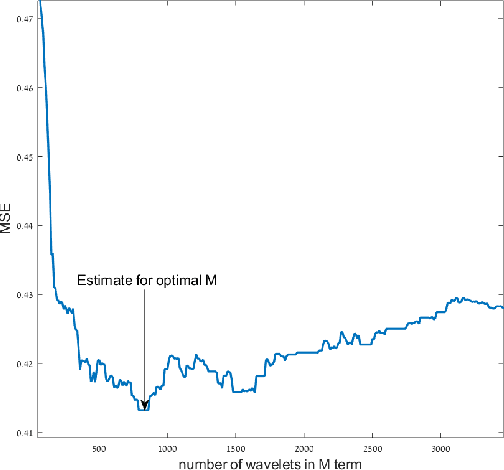
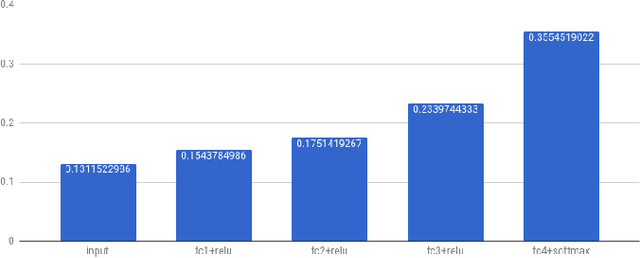
In this paper we propose a function space approach to Representation Learning and the analysis of the representation layers in deep learning architectures. We show how to compute a weak-type Besov smoothness index that quantifies the geometry of the clustering in the feature space. This approach was already applied successfully to improve the performance of machine learning algorithms such as the Random Forest and tree-based Gradient Boosting. Our experiments demonstrate that in well-known and well-performing trained networks, the Besov smoothness of the training set, measured in the corresponding hidden layer feature map representation, increases from layer to layer. We also contribute to the understanding of generalization by showing how the Besov smoothness of the representations, decreases as we add more mis-labeling to the training data. We hope this approach will contribute to the de-mystification of some aspects of deep learning.