 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrospective: A CORDIC Based Configurable Activation Function for NN Applications
Mar 18, 2025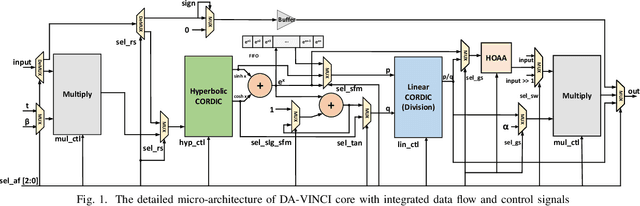
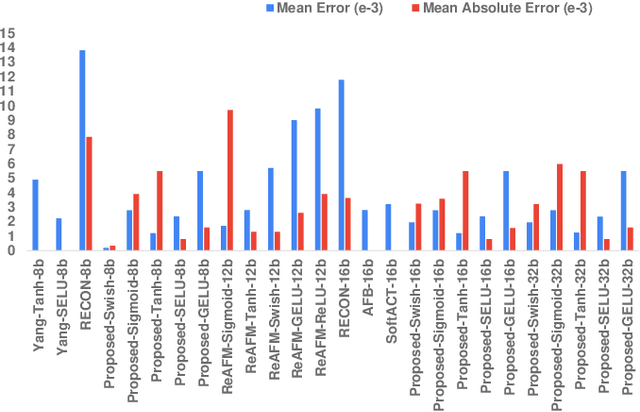
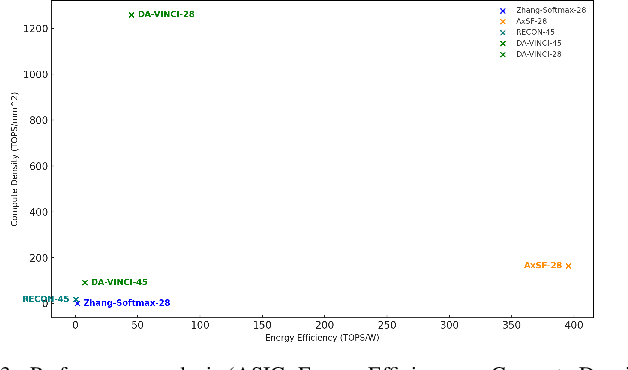
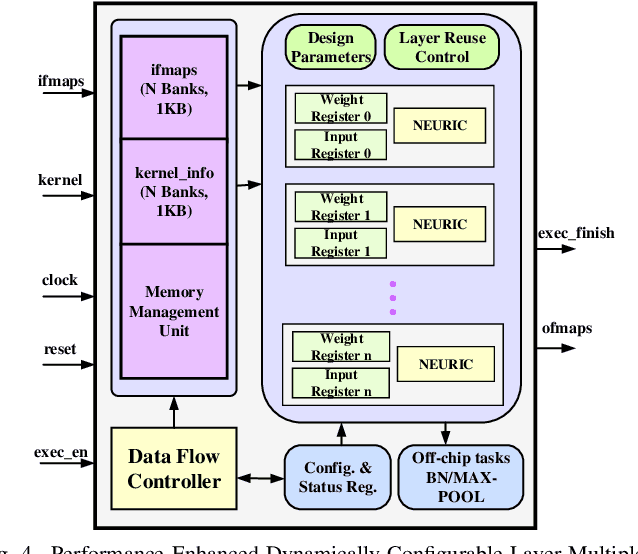
A CORDIC-based configuration for the design of Activation Functions (AF) was previously suggested to accelerate ASIC hardware design for resource-constrained systems by providing functional reconfigurability. Since its introduction, this new approach for neural network acceleration has gained widespread popularity, influencing numerous designs for activation functions in both academic and commercial AI processors. In this retrospective analysis, we explore the foundational aspects of this initiative, summarize key developments over recent years, and introduce the DA-VINCI AF tailored for the evolving needs of AI applications. This new generation of dynamically configurable and precision-adjustable activation function cores promise greater adaptability for a range of activation functions in AI workloads, including Swish, SoftMax, SeLU, and GeLU, utilizing the Shift-and-Add CORDIC technique. The previously presented design has been optimized for MAC, Sigmoid, and Tanh functionalities and incorporated into ReLU AFs, culminating in an accumulative NEURIC compute unit. These enhancements position NEURIC as a fundamental component in the resource-efficient vector engine for the realization of AI accelerators that focus on DNNs, RNNs/LSTMs, and Transformers, achieving a quality of results (QoR) of 98.5%.
HOAA: Hybrid Overestimating Approximate Adder for Enhanced Performance Processing Engine
Jul 29, 2024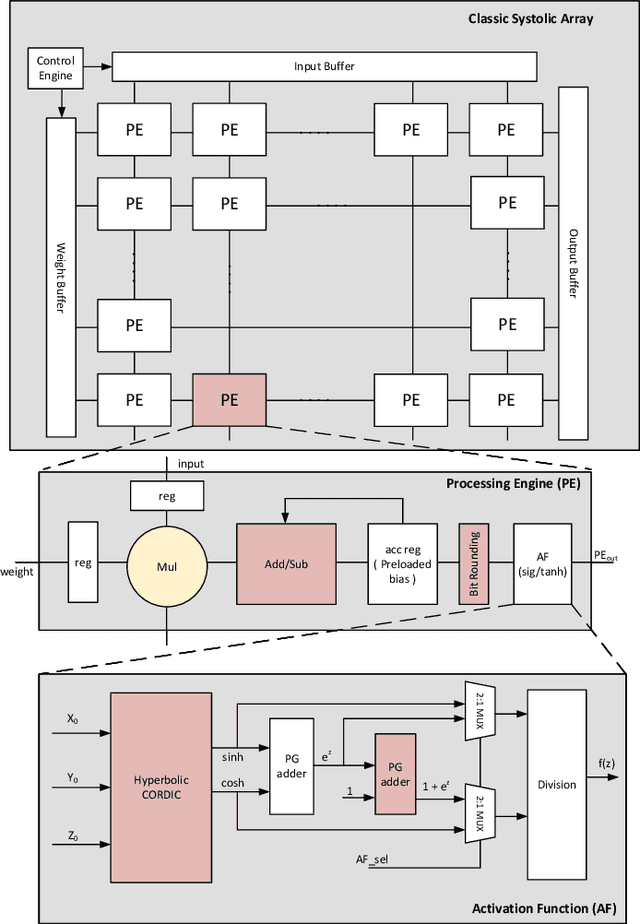
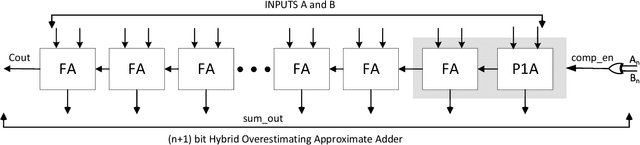
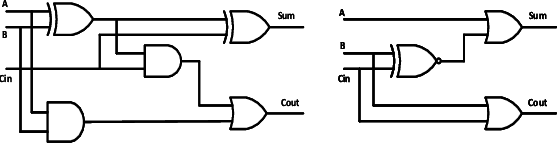
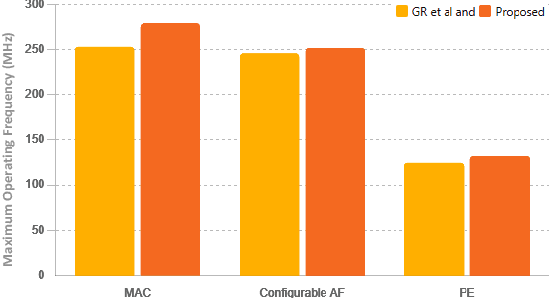
This paper presents the Hybrid Overestimating Approximate Adder designed to enhance the performance in processing engines, specifically focused on edge AI applications. A novel Plus One Adder design is proposed as an incremental adder in the RCA chain, incorporating a Full Adder with an excess 1 alongside inputs A, B, and Cin. The design approximates outputs to 2 bit values to reduce hardware complexity and improve resource efficiency. The Plus One Adder is integrated into a dynamically reconfigurable HOAA, allowing runtime interchangeability between accurate and approximate overestimation modes. The proposed design is demonstrated for multiple applications, such as Twos complement subtraction and Rounding to even, and the Configurable Activation function, which are critical components of the Processing engine. Our approach shows 21 percent improvement in area efficiency and 33 percent reduction in power consumption, compared to state of the art designs with minimal accuracy loss. Thus, the proposed HOAA could be a promising solution for resource-constrained environments, offering ideal trade-offs between hardware efficiency vs computational accuracy.