 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrospective: A CORDIC Based Configurable Activation Function for NN Applications
Mar 18, 2025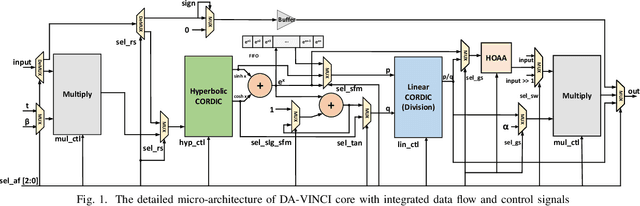
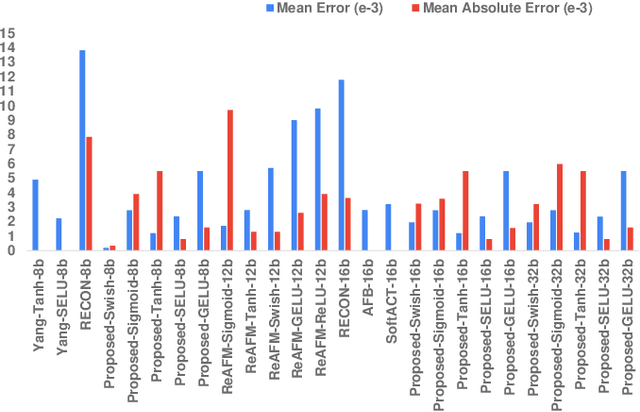
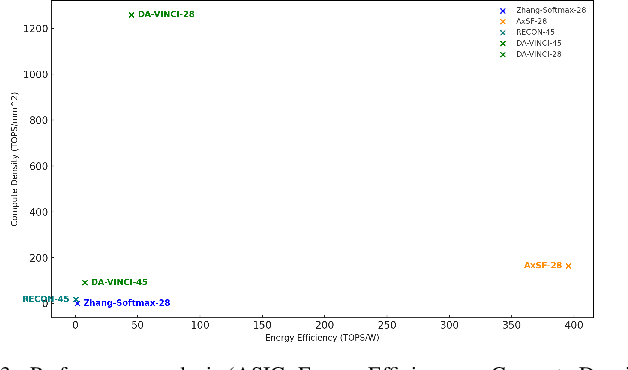
A CORDIC-based configuration for the design of Activation Functions (AF) was previously suggested to accelerate ASIC hardware design for resource-constrained systems by providing functional reconfigurability. Since its introduction, this new approach for neural network acceleration has gained widespread popularity, influencing numerous designs for activation functions in both academic and commercial AI processors. In this retrospective analysis, we explore the foundational aspects of this initiative, summarize key developments over recent years, and introduce the DA-VINCI AF tailored for the evolving needs of AI applications. This new generation of dynamically configurable and precision-adjustable activation function cores promise greater adaptability for a range of activation functions in AI workloads, including Swish, SoftMax, SeLU, and GeLU, utilizing the Shift-and-Add CORDIC technique. The previously presented design has been optimized for MAC, Sigmoid, and Tanh functionalities and incorporated into ReLU AFs, culminating in an accumulative NEURIC compute unit. These enhancements position NEURIC as a fundamental component in the resource-efficient vector engine for the realization of AI accelerators that focus on DNNs, RNNs/LSTMs, and Transformers, achieving a quality of results (QoR) of 98.5%.
Flex-PE: Flexible and SIMD Multi-Precision Processing Element for AI Workloads
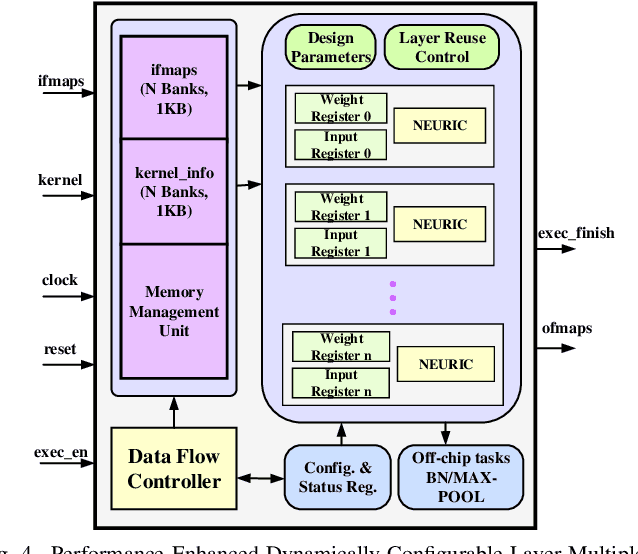
Dec 16, 2024The rapid adaptation of data driven AI models, such as deep learning inference, training, Vision Transformers (ViTs), and other HPC applications, drives a strong need for runtime precision configurable different non linear activation functions (AF) hardware support. Existing solutions support diverse precision or runtime AF reconfigurability but fail to address both simultaneously. This work proposes a flexible and SIMD multiprecision processing element (FlexPE), which supports diverse runtime configurable AFs, including sigmoid, tanh, ReLU and softmax, and MAC operation. The proposed design achieves an improved throughput of up to 16X FxP4, 8X FxP8, 4X FxP16 and 1X FxP32 in pipeline mode with 100% time multiplexed hardware. This work proposes an area efficient multiprecision iterative mode in the SIMD systolic arrays for edge AI use cases. The design delivers superior performance with up to 62X and 371X reductions in DMA reads for input feature maps and weight filters in VGG16, with an energy efficiency of 8.42 GOPS / W within the accuracy loss of 2%. The proposed architecture supports emerging 4-bit computations for DL inference while enhancing throughput in FxP8/16 modes for transformers and other HPC applications. The proposed approach enables future energy-efficient AI accelerators in edge and cloud environments.
HYDRA: Hybrid Data Multiplexing and Run-time Layer Configurable DNN Accelerator
Sep 08, 2024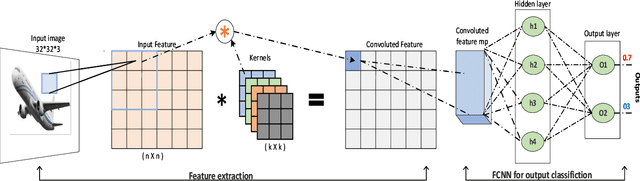
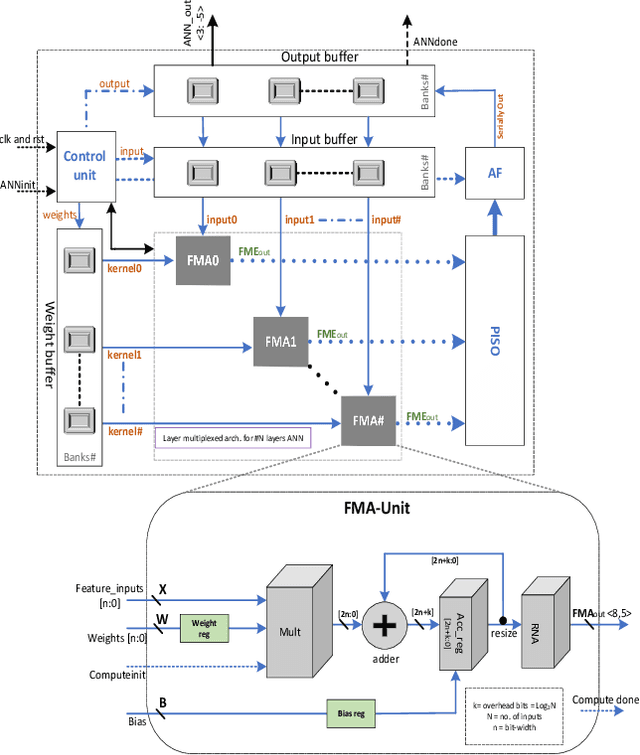
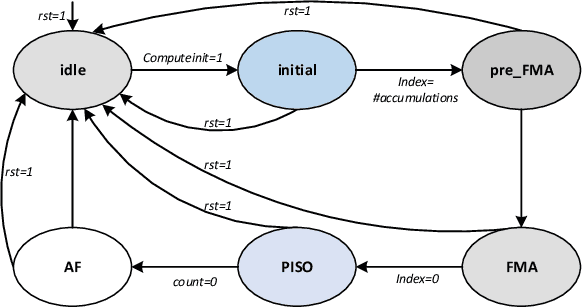
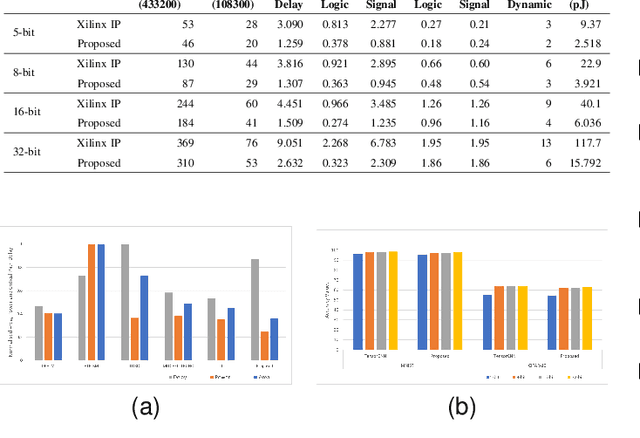
Deep neural networks (DNNs) offer plenty of challenges in executing efficient computation at edge nodes, primarily due to the huge hardware resource demands. The article proposes HYDRA, hybrid data multiplexing, and runtime layer configurable DNN accelerators to overcome the drawbacks. The work proposes a layer-multiplexed approach, which further reuses a single activation function within the execution of a single layer with improved Fused-Multiply-Accumulate (FMA). The proposed approach works in iterative mode to reuse the same hardware and execute different layers in a configurable fashion. The proposed architectures achieve reductions over 90% of power consumption and resource utilization improvements of state-of-the-art works, with 35.21 TOPSW. The proposed architecture reduces the area overhead (N-1) times required in bandwidth, AF and layer architecture. This work shows HYDRA architecture supports optimal DNN computations while improving performance on resource-constrained edge devices.