 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPADE: A SIMD Posit-enabled compute engine for Accelerating DNN Efficiency
Jan 24, 2026The growing demand for edge-AI systems requires arithmetic units that balance numerical precision, energy efficiency, and compact hardware while supporting diverse formats. Posit arithmetic offers advantages over floating- and fixed-point representations through its tapered precision, wide dynamic range, and improved numerical robustness. This work presents SPADE, a unified multi-precision SIMD Posit-based multiplyaccumulate (MAC) architecture supporting Posit (8,0), Posit (16,1), and Posit (32,2) within a single framework. Unlike prior single-precision or floating/fixed-point SIMD MACs, SPADE introduces a regime-aware, lane-fused SIMD Posit datapath that hierarchically reuses Posit-specific submodules (LOD, complementor, shifter, and multiplier) across 8/16/32-bit precisions without datapath replication. FPGA implementation on a Xilinx Virtex-7 shows 45.13% LUT and 80% slice reduction for Posit (8,0), and up to 28.44% and 17.47% improvement for Posit (16,1) and Posit (32,2) over prior work, with only 6.9% LUT and 14.9% register overhead for multi-precision support. ASIC results across TSMC nodes achieve 1.38 GHz at 6.1 mW (28 nm). Evaluation on MNIST, CIFAR-10/100, and alphabet datasets confirms competitive inference accuracy.
Retrospective: A CORDIC Based Configurable Activation Function for NN Applications
Mar 18, 2025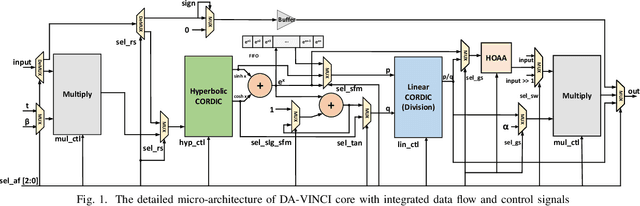
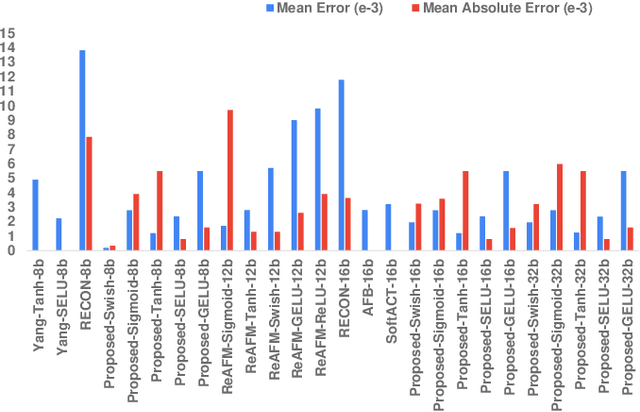
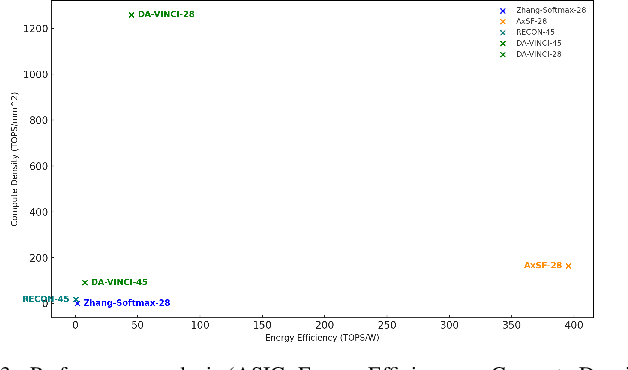
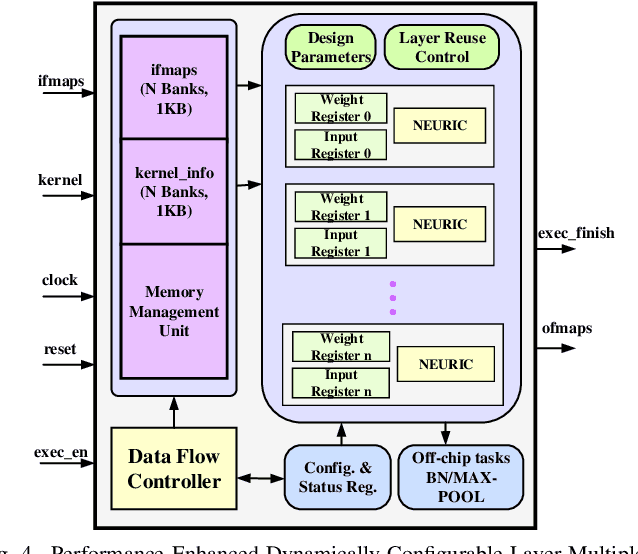
A CORDIC-based configuration for the design of Activation Functions (AF) was previously suggested to accelerate ASIC hardware design for resource-constrained systems by providing functional reconfigurability. Since its introduction, this new approach for neural network acceleration has gained widespread popularity, influencing numerous designs for activation functions in both academic and commercial AI processors. In this retrospective analysis, we explore the foundational aspects of this initiative, summarize key developments over recent years, and introduce the DA-VINCI AF tailored for the evolving needs of AI applications. This new generation of dynamically configurable and precision-adjustable activation function cores promise greater adaptability for a range of activation functions in AI workloads, including Swish, SoftMax, SeLU, and GeLU, utilizing the Shift-and-Add CORDIC technique. The previously presented design has been optimized for MAC, Sigmoid, and Tanh functionalities and incorporated into ReLU AFs, culminating in an accumulative NEURIC compute unit. These enhancements position NEURIC as a fundamental component in the resource-efficient vector engine for the realization of AI accelerators that focus on DNNs, RNNs/LSTMs, and Transformers, achieving a quality of results (QoR) of 98.5%.