 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPADE: A SIMD Posit-enabled compute engine for Accelerating DNN Efficiency
Jan 24, 2026The growing demand for edge-AI systems requires arithmetic units that balance numerical precision, energy efficiency, and compact hardware while supporting diverse formats. Posit arithmetic offers advantages over floating- and fixed-point representations through its tapered precision, wide dynamic range, and improved numerical robustness. This work presents SPADE, a unified multi-precision SIMD Posit-based multiplyaccumulate (MAC) architecture supporting Posit (8,0), Posit (16,1), and Posit (32,2) within a single framework. Unlike prior single-precision or floating/fixed-point SIMD MACs, SPADE introduces a regime-aware, lane-fused SIMD Posit datapath that hierarchically reuses Posit-specific submodules (LOD, complementor, shifter, and multiplier) across 8/16/32-bit precisions without datapath replication. FPGA implementation on a Xilinx Virtex-7 shows 45.13% LUT and 80% slice reduction for Posit (8,0), and up to 28.44% and 17.47% improvement for Posit (16,1) and Posit (32,2) over prior work, with only 6.9% LUT and 14.9% register overhead for multi-precision support. ASIC results across TSMC nodes achieve 1.38 GHz at 6.1 mW (28 nm). Evaluation on MNIST, CIFAR-10/100, and alphabet datasets confirms competitive inference accuracy.
Bio-RV: Low-Power Resource-Efficient RISC-V Processor for Biomedical Applications
Jan 13, 2026This work presents Bio-RV, a compact and resource-efficient RISC-V processor intended for biomedical control applications, such as accelerator-based biomedical SoCs and implantable pacemaker systems. The proposed Bio-RV is a multi-cycle RV32I core that provides explicit execution control and external instruction loading with capabilities that enable controlled firmware deployment, ASIC bring-up, and post-silicon testing. In addition to coordinating accelerator configuration and data transmission in heterogeneous systems, Bio-RV is designed to function as a lightweight host controller, handling interfaces with pacing, sensing, electrogram (EGM), telemetry, and battery management modules. With 708 LUTs and 235 flip-flops on FPGA prototypes, Bio-RV, implemented in a 180 nm CMOS technology, operate at 50 MHz and feature a compact hardware footprint. According to post-layout results, the proposed architectural decisions align with minimal energy use. Ultimately, Bio-RV prioritises deterministic execution, minimal hardware complexity, and integration flexibility over peak computing speed to meet the demands of ultra-low-power, safety-critical biomedical systems.
FERMI-ML: A Flexible and Resource-Efficient Memory-In-Situ SRAM Macro for TinyML acceleration
Nov 16, 2025The growing demand for low-power and area-efficient TinyML inference on AIoT devices necessitates memory architectures that minimise data movement while sustaining high computational efficiency. This paper presents FERMI-ML, a Flexible and Resource-Efficient Memory-In-Situ (MIS) SRAM macro designed for TinyML acceleration. The proposed 9T XNOR-based RX9T bit-cell integrates a 5T storage cell with a 4T XNOR compute unit, enabling variable-precision MAC and CAM operations within the same array. A 22-transistor (C22T) compressor-tree-based accumulator facilitates logarithmic 1-64-bit MAC computation with reduced delay and power compared to conventional adder trees. The 4 KB macro achieves dual functionality for in-situ computation and CAM-based lookup operations, supporting Posit-4 or FP-4 precision. Post-layout results at 65 nm show operation at 350 MHz with 0.9 V, delivering a throughput of 1.93 TOPS and an energy efficiency of 364 TOPS/W, while maintaining a Quality-of-Result (QoR) above 97.5% with InceptionV4 and ResNet-18. FERMI-ML thus demonstrates a compact, reconfigurable, and energy-aware digital Memory-In-Situ macro capable of supporting mixed-precision TinyML workloads.
RAMAN: Resource-efficient ApproxiMate Posit Processing for Algorithm-Hardware Co-desigN
Oct 26, 2025Edge-AI applications still face considerable challenges in enhancing computational efficiency in resource-constrained environments. This work presents RAMAN, a resource-efficient and approximate posit(8,2)-based Multiply-Accumulate (MAC) architecture designed to improve hardware efficiency within bandwidth limitations. The proposed REAP (Resource-Efficient Approximate Posit) MAC engine, which is at the core of RAMAN, uses approximation in the posit multiplier to achieve significant area and power reductions with an impact on accuracy. To support diverse AI workloads, this MAC unit is incorporated in a scalable Vector Execution Unit (VEU), which permits hardware reuse and parallelism among deep neural network layers. Furthermore, we propose an algorithm-hardware co-design framework incorporating approximation-aware training to evaluate the impact of hardware-level approximation on application-level performance. Empirical validation on FPGA and ASIC platforms shows that the proposed REAP MAC achieves up to 46% in LUT savings and 35.66% area, 31.28% power reduction, respectively, over the baseline Posit Dot-Product Unit (PDPU) design, while maintaining high accuracy (98.45%) for handwritten digit recognition. RAMAN demonstrates a promising trade-off between hardware efficiency and learning performance, making it suitable for next-generation edge intelligence.
Res-DPU: Resource-shared Digital Processing-in-memory Unit for Edge-AI Workloads
Oct 22, 2025Processing-in-memory (PIM) has emerged as the go to solution for addressing the von Neumann bottleneck in edge AI accelerators. However, state-of-the-art (SoTA) digital PIM approaches suffer from low compute density, primarily due to the use of bulky bit cells and transistor-heavy adder trees, which impose limitations on macro scalability and energy efficiency. This work introduces Res-DPU, a resource-shared digital PIM unit, with a dual-port 5T SRAM latch and shared 2T AND compute logic. This reflects the per-bit multiplication cost to just 5.25T and reduced the transistor count of the PIM array by up to 56% over the SoTA works. Furthermore, a Transistor-Reduced 2D Interspersed Adder Tree (TRAIT) with FA-7T and PG-FA-26T helps reduce the power consumption of the adder tree by up to 21.35% and leads to improved energy efficiency by 59% compared to conventional 28T RCA designs. We propose a Cycle-controlled Iterative Approximate-Accurate Multiplication (CIA2M) approach, enabling run-time accuracy-latency trade-offs without requiring error-correction circuitry. The 16 KB REP-DPIM macro achieves 0.43 TOPS throughput and 87.22 TOPS/W energy efficiency in TSMC 65nm CMOS, with 96.85% QoR for ResNet-18 or VGG-16 on CIFAR-10, including 30% pruning. The proposed results establish a Res-DPU module for highly scalable and energy-efficient real-time edge AI accelerators.
POLARON: Precision-aware On-device Learning and Adaptive Runtime-cONfigurable AI acceleration
Jun 10, 2025The increasing complexity of AI models requires flexible hardware capable of supporting diverse precision formats, particularly for energy-constrained edge platforms. This work presents PARV-CE, a SIMD-enabled, multi-precision MAC engine that performs efficient multiply-accumulate operations using a unified data-path for 4/8/16-bit fixed-point, floating point, and posit formats. The architecture incorporates a layer adaptive precision strategy to align computational accuracy with workload sensitivity, optimizing both performance and energy usage. PARV-CE integrates quantization-aware execution with a reconfigurable SIMD pipeline, enabling high-throughput processing with minimal overhead through hardware-software co-design. The results demonstrate up to 2x improvement in PDP and 3x reduction in resource usage compared to SoTA designs, while retaining accuracy within 1.8% FP32 baseline. The architecture supports both on-device training and inference across a range of workloads, including DNNs, RNNs, RL, and Transformer models. The empirical analysis establish PARVCE incorporated POLARON as a scalable and energy-efficient solution for precision-adaptive AI acceleration at edge.
QForce-RL: Quantized FPGA-Optimized Reinforcement Learning Compute Engine
Jun 08, 2025Reinforcement Learning (RL) has outperformed other counterparts in sequential decision-making and dynamic environment control. However, FPGA deployment is significantly resource-expensive, as associated with large number of computations in training agents with high-quality images and possess new challenges. In this work, we propose QForce-RL takes benefits of quantization to enhance throughput and reduce energy footprint with light-weight RL architecture, without significant performance degradation. QForce-RL takes advantages from E2HRL to reduce overall RL actions to learn desired policy and QuaRL for quantization based SIMD for hardware acceleration. We have also provided detailed analysis for different RL environments, with emphasis on model size, parameters, and accelerated compute ops. The architecture is scalable for resource-constrained devices and provide parametrized efficient deployment with flexibility in latency, throughput, power, and energy efficiency. The proposed QForce-RL provides performance enhancement up to 2.3x and better FPS - 2.6x compared to SoTA works.
Retrospective: A CORDIC Based Configurable Activation Function for NN Applications
Mar 18, 2025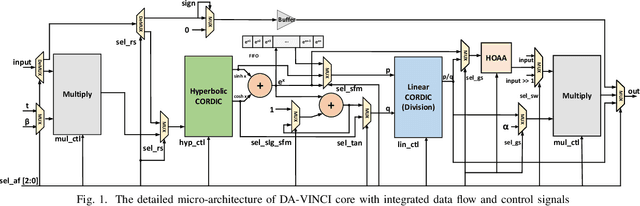
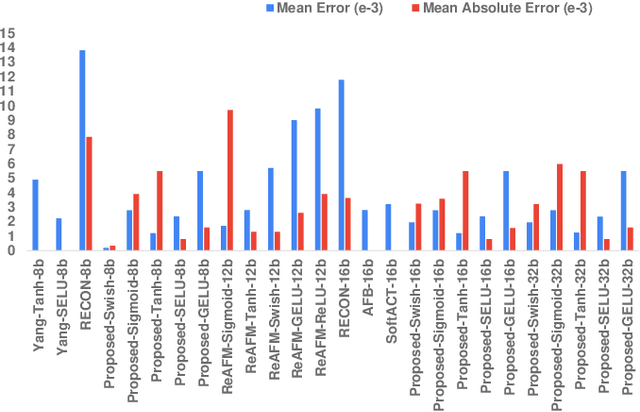
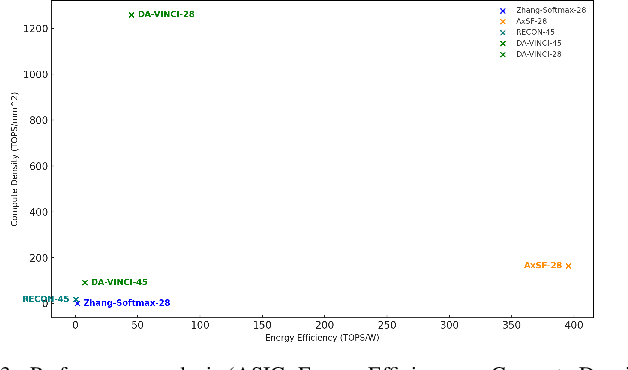
A CORDIC-based configuration for the design of Activation Functions (AF) was previously suggested to accelerate ASIC hardware design for resource-constrained systems by providing functional reconfigurability. Since its introduction, this new approach for neural network acceleration has gained widespread popularity, influencing numerous designs for activation functions in both academic and commercial AI processors. In this retrospective analysis, we explore the foundational aspects of this initiative, summarize key developments over recent years, and introduce the DA-VINCI AF tailored for the evolving needs of AI applications. This new generation of dynamically configurable and precision-adjustable activation function cores promise greater adaptability for a range of activation functions in AI workloads, including Swish, SoftMax, SeLU, and GeLU, utilizing the Shift-and-Add CORDIC technique. The previously presented design has been optimized for MAC, Sigmoid, and Tanh functionalities and incorporated into ReLU AFs, culminating in an accumulative NEURIC compute unit. These enhancements position NEURIC as a fundamental component in the resource-efficient vector engine for the realization of AI accelerators that focus on DNNs, RNNs/LSTMs, and Transformers, achieving a quality of results (QoR) of 98.5%.
Flex-PE: Flexible and SIMD Multi-Precision Processing Element for AI Workloads
Dec 16, 2024The rapid adaptation of data driven AI models, such as deep learning inference, training, Vision Transformers (ViTs), and other HPC applications, drives a strong need for runtime precision configurable different non linear activation functions (AF) hardware support. Existing solutions support diverse precision or runtime AF reconfigurability but fail to address both simultaneously. This work proposes a flexible and SIMD multiprecision processing element (FlexPE), which supports diverse runtime configurable AFs, including sigmoid, tanh, ReLU and softmax, and MAC operation. The proposed design achieves an improved throughput of up to 16X FxP4, 8X FxP8, 4X FxP16 and 1X FxP32 in pipeline mode with 100% time multiplexed hardware. This work proposes an area efficient multiprecision iterative mode in the SIMD systolic arrays for edge AI use cases. The design delivers superior performance with up to 62X and 371X reductions in DMA reads for input feature maps and weight filters in VGG16, with an energy efficiency of 8.42 GOPS / W within the accuracy loss of 2%. The proposed architecture supports emerging 4-bit computations for DL inference while enhancing throughput in FxP8/16 modes for transformers and other HPC applications. The proposed approach enables future energy-efficient AI accelerators in edge and cloud environments.
HYDRA: Hybrid Data Multiplexing and Run-time Layer Configurable DNN Accelerator
Sep 08, 2024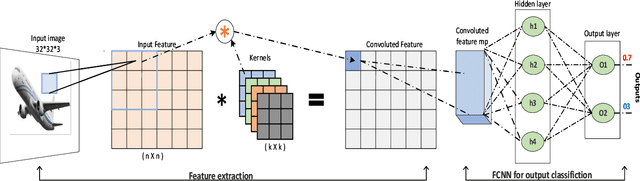
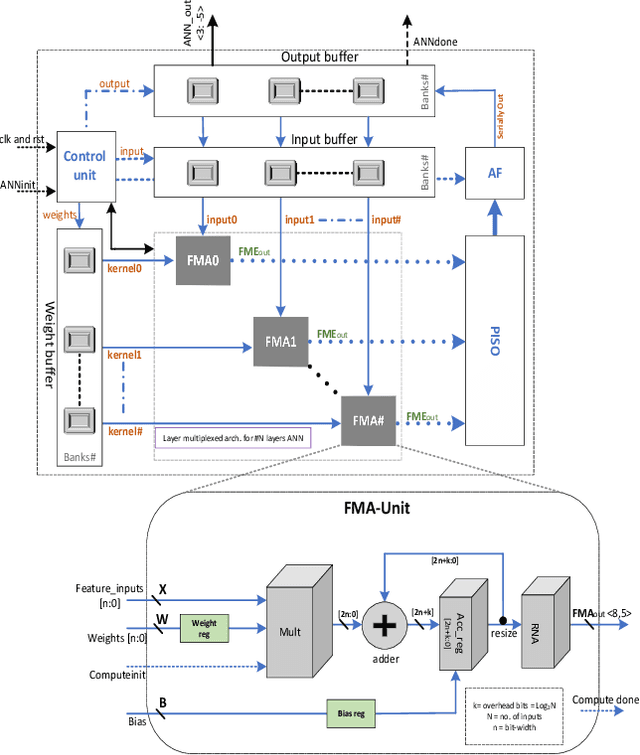
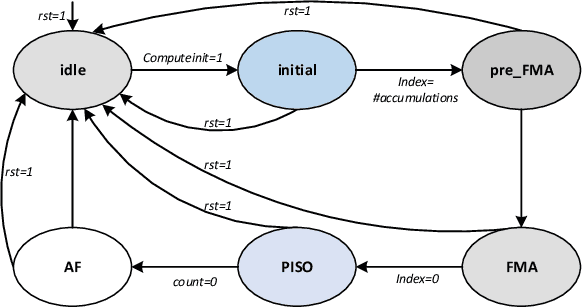
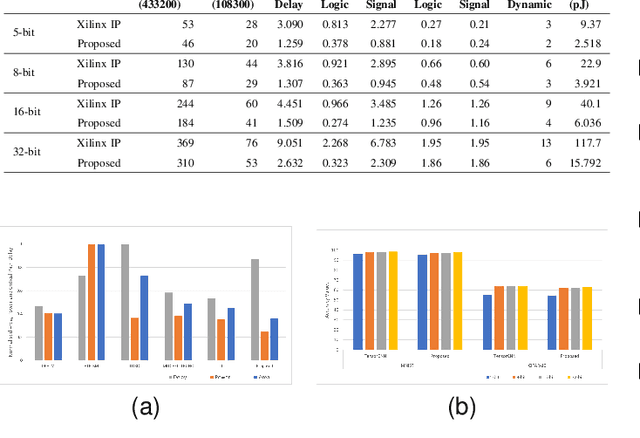
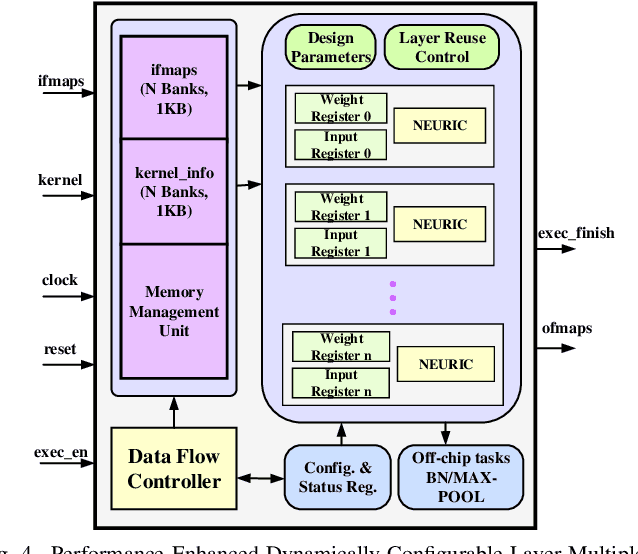
Deep neural networks (DNNs) offer plenty of challenges in executing efficient computation at edge nodes, primarily due to the huge hardware resource demands. The article proposes HYDRA, hybrid data multiplexing, and runtime layer configurable DNN accelerators to overcome the drawbacks. The work proposes a layer-multiplexed approach, which further reuses a single activation function within the execution of a single layer with improved Fused-Multiply-Accumulate (FMA). The proposed approach works in iterative mode to reuse the same hardware and execute different layers in a configurable fashion. The proposed architectures achieve reductions over 90% of power consumption and resource utilization improvements of state-of-the-art works, with 35.21 TOPSW. The proposed architecture reduces the area overhead (N-1) times required in bandwidth, AF and layer architecture. This work shows HYDRA architecture supports optimal DNN computations while improving performance on resource-constrained edge devices.