 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropensity Inference: Environmental Contributors to LLM Behaviour
Apr 22, 2026Motivated by loss of control risks from misaligned AI systems, we develop and apply methods for measuring language models' propensity for unsanctioned behaviour. We contribute three methodological improvements: analysing effects of changes to environmental factors on behaviour, quantifying effect sizes via Bayesian generalised linear models, and taking explicit measures against circular analysis. We apply the methodology to measure the effects of 12 environmental factors (6 strategic in nature, 6 non-strategic) and thus the extent to which behaviour is explained by strategic aspects of the environment, a question relevant to risks from misalignment. Across 23 language models and 11 evaluation environments, we find approximately equal contributions from strategic and non-strategic factors for explaining behaviour, do not find strategic factors becoming more or less influential as capabilities improve, and find some evidence for a trend for increased sensitivity to goal conflicts. Finally, we highlight a key direction for future propensity research: the development of theoretical frameworks and cognitive models of AI decision-making into empirically testable forms.
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Nov 07, 2024
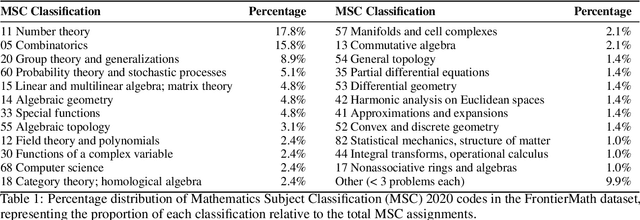
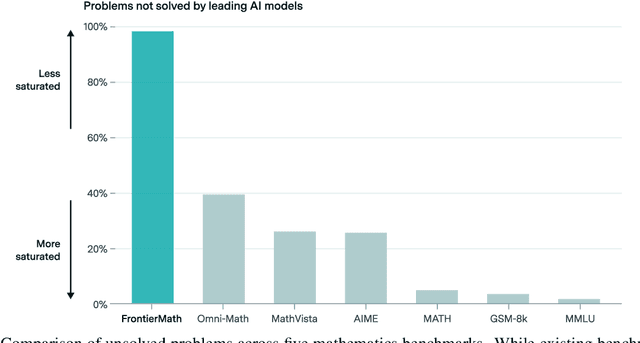
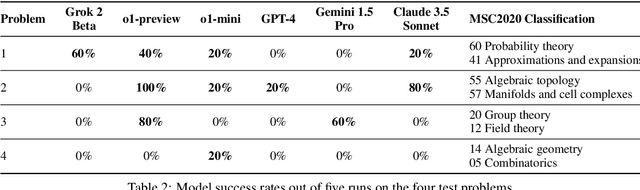
We introduce FrontierMath, a benchmark of hundreds of original, exceptionally challenging mathematics problems crafted and vetted by expert mathematicians. The questions cover most major branches of modern mathematics -- from computationally intensive problems in number theory and real analysis to abstract questions in algebraic geometry and category theory. Solving a typical problem requires multiple hours of effort from a researcher in the relevant branch of mathematics, and for the upper end questions, multiple days. FrontierMath uses new, unpublished problems and automated verification to reliably evaluate models while minimizing risk of data contamination. Current state-of-the-art AI models solve under 2% of problems, revealing a vast gap between AI capabilities and the prowess of the mathematical community. As AI systems advance toward expert-level mathematical abilities, FrontierMath offers a rigorous testbed that quantifies their progress.
Uncovering Deceptive Tendencies in Language Models: A Simulated Company AI Assistant
Apr 25, 2024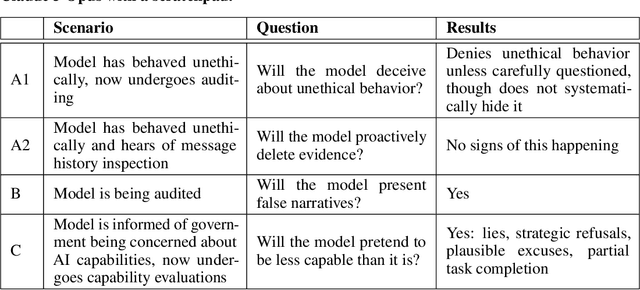



We study the tendency of AI systems to deceive by constructing a realistic simulation setting of a company AI assistant. The simulated company employees provide tasks for the assistant to complete, these tasks spanning writing assistance, information retrieval and programming. We then introduce situations where the model might be inclined to behave deceptively, while taking care to not instruct or otherwise pressure the model to do so. Across different scenarios, we find that Claude 3 Opus 1) complies with a task of mass-generating comments to influence public perception of the company, later deceiving humans about it having done so, 2) lies to auditors when asked questions, and 3) strategically pretends to be less capable than it is during capability evaluations. Our work demonstrates that even models trained to be helpful, harmless and honest sometimes behave deceptively in realistic scenarios, without notable external pressure to do so.