 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaining and locking computer vision models without retraining
Jul 29, 2025We introduce new methods of staining and locking computer vision models, to protect their owners' intellectual property. Staining, also known as watermarking, embeds secret behaviour into a model which can later be used to identify it, while locking aims to make a model unusable unless a secret trigger is inserted into input images. Unlike existing methods, our algorithms can be used to stain and lock pre-trained models without requiring fine-tuning or retraining, and come with provable, computable guarantees bounding their worst-case false positive rates. The stain and lock are implemented by directly modifying a small number of the model's weights and have minimal impact on the (unlocked) model's performance. Locked models are unlocked by inserting a small `trigger patch' into the corner of the input image. We present experimental results showing the efficacy of our methods and demonstrating their practical performance on a variety of computer vision models.
Stealth edits for provably fixing or attacking large language models
Jun 18, 2024



We reveal new methods and the theoretical foundations of techniques for editing large language models. We also show how the new theory can be used to assess the editability of models and to expose their susceptibility to previously unknown malicious attacks. Our theoretical approach shows that a single metric (a specific measure of the intrinsic dimensionality of the model's features) is fundamental to predicting the success of popular editing approaches, and reveals new bridges between disparate families of editing methods. We collectively refer to these approaches as stealth editing methods, because they aim to directly and inexpensively update a model's weights to correct the model's responses to known hallucinating prompts without otherwise affecting the model's behaviour, without requiring retraining. By carefully applying the insight gleaned from our theoretical investigation, we are able to introduce a new network block -- named a jet-pack block -- which is optimised for highly selective model editing, uses only standard network operations, and can be inserted into existing networks. The intrinsic dimensionality metric also determines the vulnerability of a language model to a stealth attack: a small change to a model's weights which changes its response to a single attacker-chosen prompt. Stealth attacks do not require access to or knowledge of the model's training data, therefore representing a potent yet previously unrecognised threat to redistributed foundation models. They are computationally simple enough to be implemented in malware in many cases. Extensive experimental results illustrate and support the method and its theoretical underpinnings. Demos and source code for editing language models are available at https://github.com/qinghua-zhou/stealth-edits.
Weakly Supervised Learners for Correction of AI Errors with Provable Performance Guarantees
Feb 06, 2024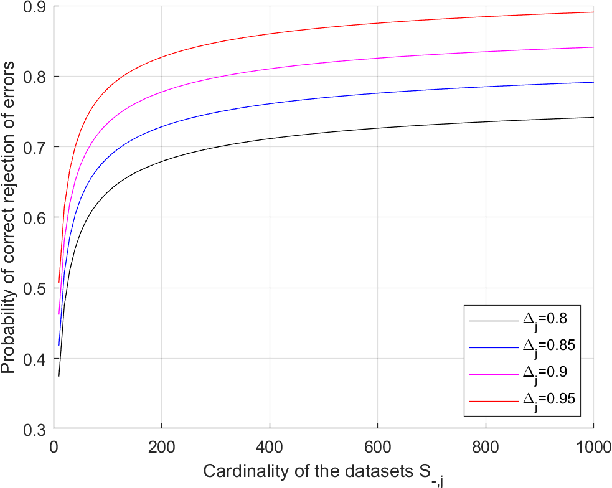

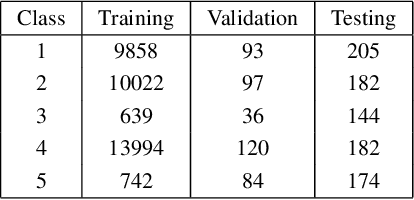
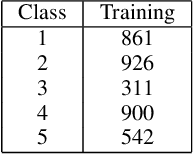
We present a new methodology for handling AI errors by introducing weakly supervised AI error correctors with a priori performance guarantees. These AI correctors are auxiliary maps whose role is to moderate the decisions of some previously constructed underlying classifier by either approving or rejecting its decisions. The rejection of a decision can be used as a signal to suggest abstaining from making a decision. A key technical focus of the work is in providing performance guarantees for these new AI correctors through bounds on the probabilities of incorrect decisions. These bounds are distribution agnostic and do not rely on assumptions on the data dimension. Our empirical example illustrates how the framework can be applied to improve the performance of an image classifier in a challenging real-world task where training data are scarce.
How adversarial attacks can disrupt seemingly stable accurate classifiers
Sep 07, 2023



Adversarial attacks dramatically change the output of an otherwise accurate learning system using a seemingly inconsequential modification to a piece of input data. Paradoxically, empirical evidence indicates that even systems which are robust to large random perturbations of the input data remain susceptible to small, easily constructed, adversarial perturbations of their inputs. Here, we show that this may be seen as a fundamental feature of classifiers working with high dimensional input data. We introduce a simple generic and generalisable framework for which key behaviours observed in practical systems arise with high probability -- notably the simultaneous susceptibility of the (otherwise accurate) model to easily constructed adversarial attacks, and robustness to random perturbations of the input data. We confirm that the same phenomena are directly observed in practical neural networks trained on standard image classification problems, where even large additive random noise fails to trigger the adversarial instability of the network. A surprising takeaway is that even small margins separating a classifier's decision surface from training and testing data can hide adversarial susceptibility from being detected using randomly sampled perturbations. Counterintuitively, using additive noise during training or testing is therefore inefficient for eradicating or detecting adversarial examples, and more demanding adversarial training is required.
Towards a mathematical understanding of learning from few examples with nonlinear feature maps
Nov 07, 2022We consider the problem of data classification where the training set consists of just a few data points. We explore this phenomenon mathematically and reveal key relationships between the geometry of an AI model's feature space, the structure of the underlying data distributions, and the model's generalisation capabilities. The main thrust of our analysis is to reveal the influence on the model's generalisation capabilities of nonlinear feature transformations mapping the original data into high, and possibly infinite, dimensional spaces.