 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Learners for Correction of AI Errors with Provable Performance Guarantees
Feb 06, 2024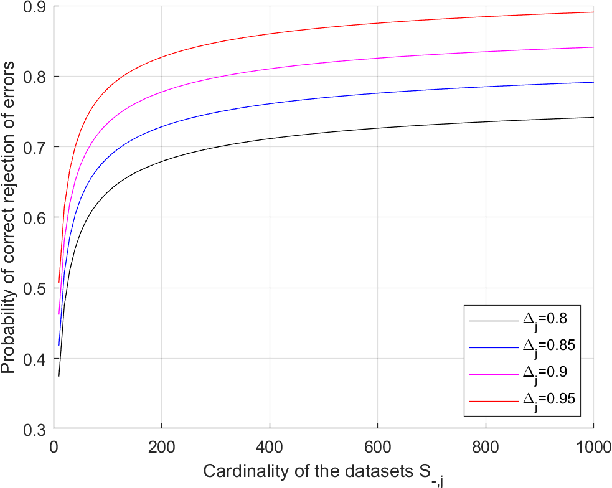

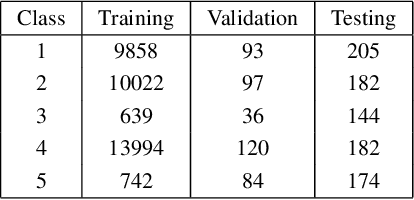
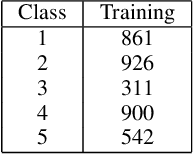
We present a new methodology for handling AI errors by introducing weakly supervised AI error correctors with a priori performance guarantees. These AI correctors are auxiliary maps whose role is to moderate the decisions of some previously constructed underlying classifier by either approving or rejecting its decisions. The rejection of a decision can be used as a signal to suggest abstaining from making a decision. A key technical focus of the work is in providing performance guarantees for these new AI correctors through bounds on the probabilities of incorrect decisions. These bounds are distribution agnostic and do not rely on assumptions on the data dimension. Our empirical example illustrates how the framework can be applied to improve the performance of an image classifier in a challenging real-world task where training data are scarce.
Invariant template matching in systems with spatiotemporal coding: a vote for instability
Feb 14, 2007

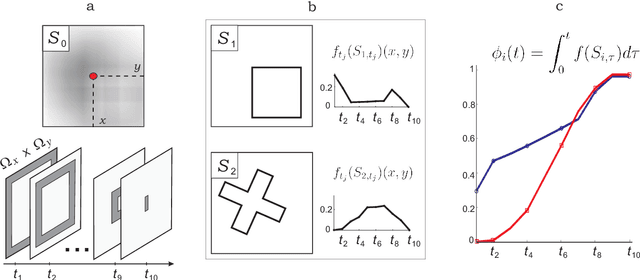

We consider the design of a pattern recognition that matches templates to images, both of which are spatially sampled and encoded as temporal sequences. The image is subject to a combination of various perturbations. These include ones that can be modeled as parameterized uncertainties such as image blur, luminance, translation, and rotation as well as unmodeled ones. Biological and neural systems require that these perturbations be processed through a minimal number of channels by simple adaptation mechanisms. We found that the most suitable mathematical framework to meet this requirement is that of weakly attracting sets. This framework provides us with a normative and unifying solution to the pattern recognition problem. We analyze the consequences of its explicit implementation in neural systems. Several properties inherent to the systems designed in accordance with our normative mathematical argument coincide with known empirical facts. This is illustrated in mental rotation, visual search and blur/intensity adaptation. We demonstrate how our results can be applied to a range of practical problems in template matching and pattern recognition.
* 52 pages, 12 figures