 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Co-Evolution of Malware and Detection Models: A Bilevel Optimization Perspective
Apr 24, 2026Machine learning-based malware detectors are increasingly vulnerable to adversarial examples. Traditional defenses, such as one-shot adversarial training, often fail against adaptive attackers who use reinforcement learning to bypass detection. This paper proposes a robust defense framework based on bilevel optimization, explicitly modeling the strategic interaction between a defender and an attacker as an adversarial co-evolutionary process. We evaluate our approach using the MAB-malware framework against three distinct malware families: Mokes, Strab, and DCRat. Our experimental results demonstrate that while standard classifiers and basic adversarial retraining often remain vulnerable, showing evasion rates as high as 90 %, the proposed bilevel optimization approach consistently achieves near-total immunity, reducing evasion rates to 0 - 1.89 %. Furthermore, the iterative framework significantly increases the attacker's query complexity, raising the average cost of successful evasion by up to two orders of magnitude. These findings suggest that modeling the iterative cycle of attack and defense through bilevel optimization is essential for developing resilient malware detection systems capable of withstanding evolving adversarial threats.
Online Clustering of Known and Emerging Malware Families
May 06, 2024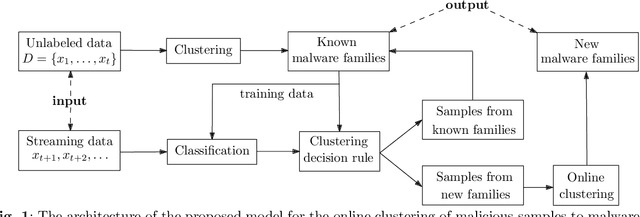
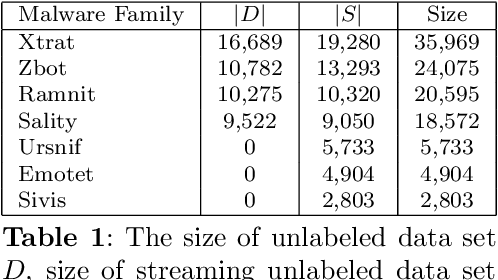
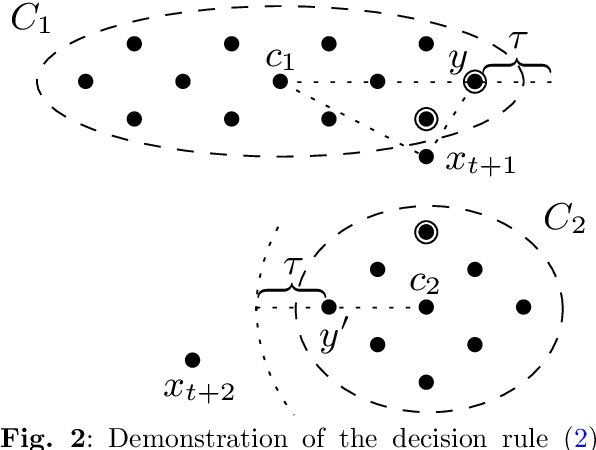

Malware attacks have become significantly more frequent and sophisticated in recent years. Therefore, malware detection and classification are critical components of information security. Due to the large amount of malware samples available, it is essential to categorize malware samples according to their malicious characteristics. Clustering algorithms are thus becoming more widely used in computer security to analyze the behavior of malware variants and discover new malware families. Online clustering algorithms help us to understand malware behavior and produce a quicker response to new threats. This paper introduces a novel machine learning-based model for the online clustering of malicious samples into malware families. Streaming data is divided according to the clustering decision rule into samples from known and new emerging malware families. The streaming data is classified using the weighted k-nearest neighbor classifier into known families, and the online k-means algorithm clusters the remaining streaming data and achieves a purity of clusters from 90.20% for four clusters to 93.34% for ten clusters. This work is based on static analysis of portable executable files for the Windows operating system. Experimental results indicate that the proposed online clustering model can create high-purity clusters corresponding to malware families. This allows malware analysts to receive similar malware samples, speeding up their analysis.
A Natural Language Processing Approach to Malware Classification
Jul 07, 2023Many different machine learning and deep learning techniques have been successfully employed for malware detection and classification. Examples of popular learning techniques in the malware domain include Hidden Markov Models (HMM), Random Forests (RF), Convolutional Neural Networks (CNN), Support Vector Machines (SVM), and Recurrent Neural Networks (RNN) such as Long Short-Term Memory (LSTM) networks. In this research, we consider a hybrid architecture, where HMMs are trained on opcode sequences, and the resulting hidden states of these trained HMMs are used as feature vectors in various classifiers. In this context, extracting the HMM hidden state sequences can be viewed as a form of feature engineering that is somewhat analogous to techniques that are commonly employed in Natural Language Processing (NLP). We find that this NLP-based approach outperforms other popular techniques on a challenging malware dataset, with an HMM-Random Forrest model yielding the best results.
Steganographic Capacity of Deep Learning Models
Jun 25, 2023As machine learning and deep learning models become ubiquitous, it is inevitable that there will be attempts to exploit such models in various attack scenarios. For example, in a steganographic-based attack, information could be hidden in a learning model, which might then be used to distribute malware, or for other malicious purposes. In this research, we consider the steganographic capacity of several learning models. Specifically, we train a Multilayer Perceptron (MLP), Convolutional Neural Network (CNN), and Transformer model on a challenging malware classification problem. For each of the resulting models, we determine the number of low-order bits of the trained parameters that can be altered without significantly affecting the performance of the model. We find that the steganographic capacity of the learning models tested is surprisingly high, and that in each case, there is a clear threshold after which model performance rapidly degrades.
Classification and Online Clustering of Zero-Day Malware
May 01, 2023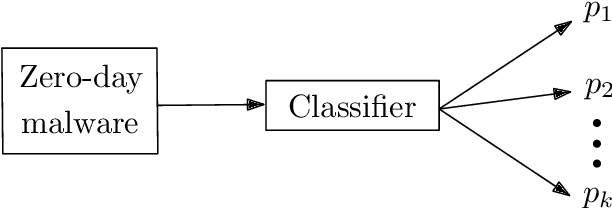
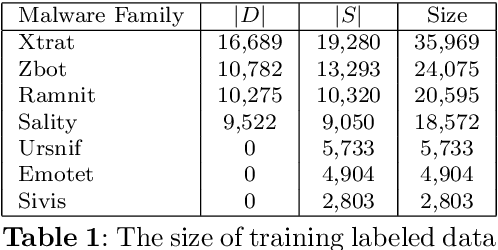
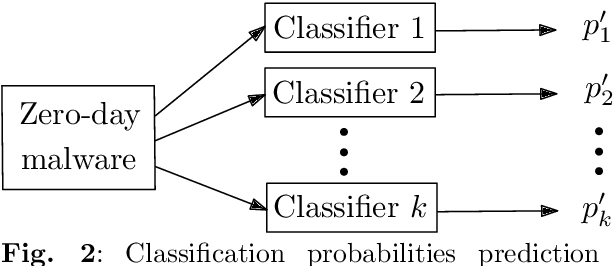
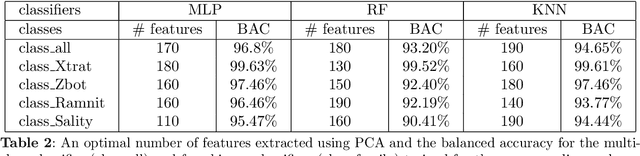
A large amount of new malware is constantly being generated, which must not only be distinguished from benign samples, but also classified into malware families. For this purpose, investigating how existing malware families are developed and examining emerging families need to be explored. This paper focuses on the online processing of incoming malicious samples to assign them to existing families or, in the case of samples from new families, to cluster them. We experimented with seven prevalent malware families from the EMBER dataset, with four in the training set and three additional new families in the test set. Based on the classification score of the multilayer perceptron, we determined which samples would be classified and which would be clustered into new malware families. We classified 97.21% of streaming data with a balanced accuracy of 95.33%. Then, we clustered the remaining data using a self-organizing map, achieving a purity from 47.61% for four clusters to 77.68% for ten clusters. These results indicate that our approach has the potential to be applied to the classification and clustering of zero-day malware into malware families.
Parallel Instance Filtering for Malware Detection
Jun 28, 2022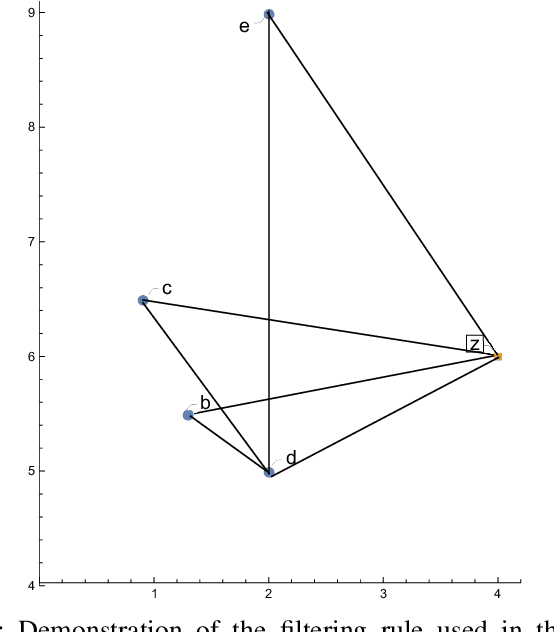
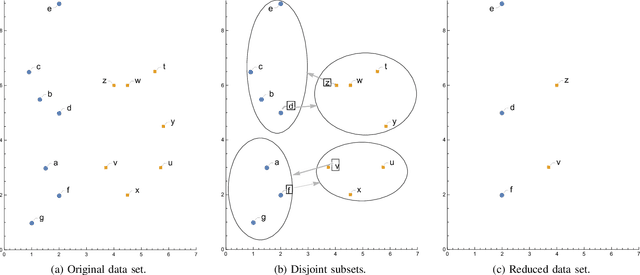
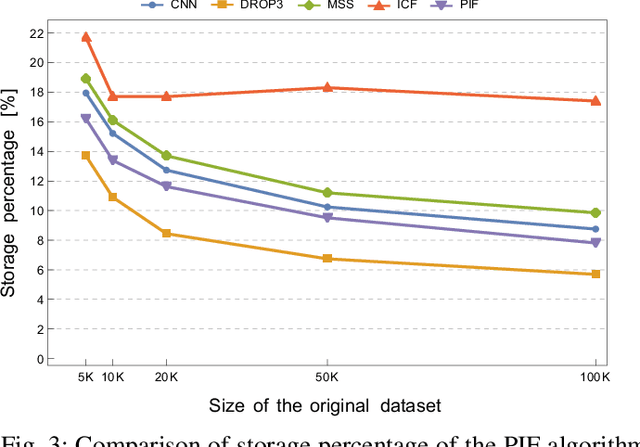
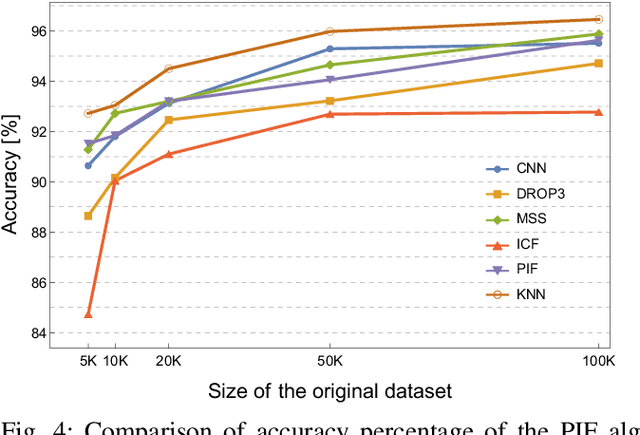
Machine learning algorithms are widely used in the area of malware detection. With the growth of sample amounts, training of classification algorithms becomes more and more expensive. In addition, training data sets may contain redundant or noisy instances. The problem to be solved is how to select representative instances from large training data sets without reducing the accuracy. This work presents a new parallel instance selection algorithm called Parallel Instance Filtering (PIF). The main idea of the algorithm is to split the data set into non-overlapping subsets of instances covering the whole data set and apply a filtering process for each subset. Each subset consists of instances that have the same nearest enemy. As a result, the PIF algorithm is fast since subsets are processed independently of each other using parallel computation. We compare the PIF algorithm with several state-of-the-art instance selection algorithms on a large data set of 500,000 malicious and benign samples. The feature set was extracted using static analysis, and it includes metadata from the portable executable file format. Our experimental results demonstrate that the proposed instance selection algorithm reduces the size of a training data set significantly with the only slightly decreased accuracy. The PIF algorithm outperforms existing instance selection methods used in the experiments in terms of the ratio between average classification accuracy and storage percentage.