 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Clustering of Known and Emerging Malware Families
May 06, 2024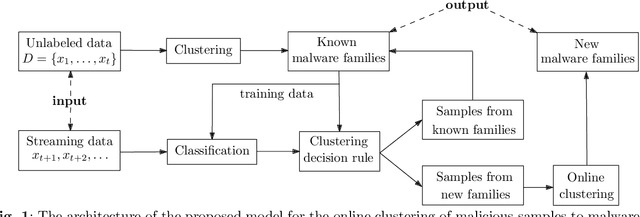
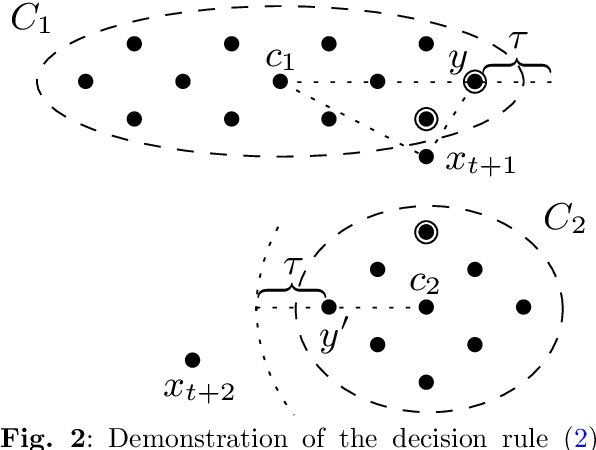

Malware attacks have become significantly more frequent and sophisticated in recent years. Therefore, malware detection and classification are critical components of information security. Due to the large amount of malware samples available, it is essential to categorize malware samples according to their malicious characteristics. Clustering algorithms are thus becoming more widely used in computer security to analyze the behavior of malware variants and discover new malware families. Online clustering algorithms help us to understand malware behavior and produce a quicker response to new threats. This paper introduces a novel machine learning-based model for the online clustering of malicious samples into malware families. Streaming data is divided according to the clustering decision rule into samples from known and new emerging malware families. The streaming data is classified using the weighted k-nearest neighbor classifier into known families, and the online k-means algorithm clusters the remaining streaming data and achieves a purity of clusters from 90.20% for four clusters to 93.34% for ten clusters. This work is based on static analysis of portable executable files for the Windows operating system. Experimental results indicate that the proposed online clustering model can create high-purity clusters corresponding to malware families. This allows malware analysts to receive similar malware samples, speeding up their analysis.
A Comparison of Adversarial Learning Techniques for Malware Detection
Aug 19, 2023Machine learning has proven to be a useful tool for automated malware detection, but machine learning models have also been shown to be vulnerable to adversarial attacks. This article addresses the problem of generating adversarial malware samples, specifically malicious Windows Portable Executable files. We summarize and compare work that has focused on adversarial machine learning for malware detection. We use gradient-based, evolutionary algorithm-based, and reinforcement-based methods to generate adversarial samples, and then test the generated samples against selected antivirus products. We compare the selected methods in terms of accuracy and practical applicability. The results show that applying optimized modifications to previously detected malware can lead to incorrect classification of the file as benign. It is also known that generated malware samples can be successfully used against detection models other than those used to generate them and that using combinations of generators can create new samples that evade detection. Experiments show that the Gym-malware generator, which uses a reinforcement learning approach, has the greatest practical potential. This generator achieved an average sample generation time of 5.73 seconds and the highest average evasion rate of 44.11%. Using the Gym-malware generator in combination with itself improved the evasion rate to 58.35%.
Keystroke Dynamics for User Identification
Jul 07, 2023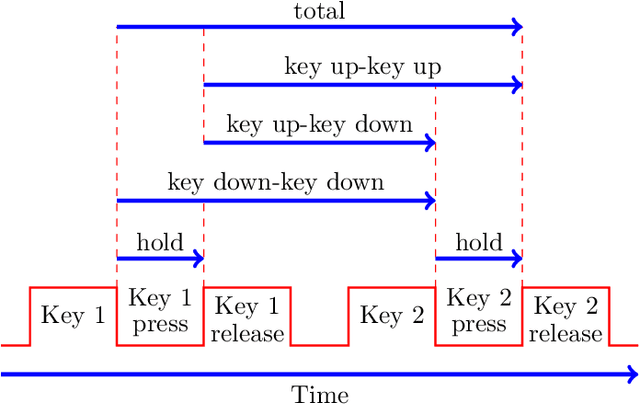

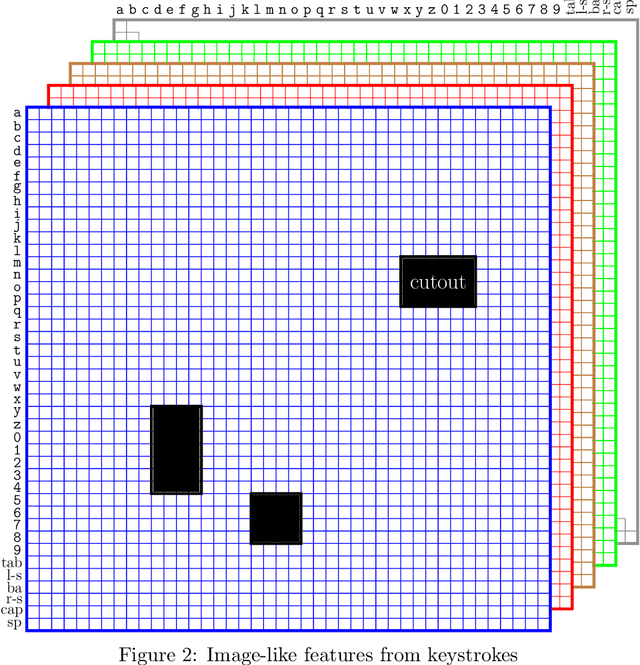

In previous research, keystroke dynamics has shown promise for user authentication, based on both fixed-text and free-text data. In this research, we consider the more challenging multiclass user identification problem, based on free-text data. We experiment with a complex image-like feature that has previously been used to achieve state-of-the-art authentication results over free-text data. Using this image-like feature and multiclass Convolutional Neural Networks, we are able to obtain a classification (i.e., identification) accuracy of 0.78 over a set of 148 users. However, we find that a Random Forest classifier trained on a slightly modified version of this same feature yields an accuracy of 0.93.
Creating Valid Adversarial Examples of Malware
Jun 23, 2023Machine learning is becoming increasingly popular as a go-to approach for many tasks due to its world-class results. As a result, antivirus developers are incorporating machine learning models into their products. While these models improve malware detection capabilities, they also carry the disadvantage of being susceptible to adversarial attacks. Although this vulnerability has been demonstrated for many models in white-box settings, a black-box attack is more applicable in practice for the domain of malware detection. We present a generator of adversarial malware examples using reinforcement learning algorithms. The reinforcement learning agents utilize a set of functionality-preserving modifications, thus creating valid adversarial examples. Using the proximal policy optimization (PPO) algorithm, we achieved an evasion rate of 53.84% against the gradient-boosted decision tree (GBDT) model. The PPO agent previously trained against the GBDT classifier scored an evasion rate of 11.41% against the neural network-based classifier MalConv and an average evasion rate of 2.31% against top antivirus programs. Furthermore, we discovered that random application of our functionality-preserving portable executable modifications successfully evades leading antivirus engines, with an average evasion rate of 11.65%. These findings indicate that machine learning-based models used in malware detection systems are vulnerable to adversarial attacks and that better safeguards need to be taken to protect these systems.
Classification and Online Clustering of Zero-Day Malware
May 01, 2023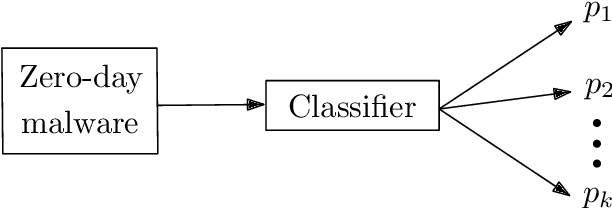
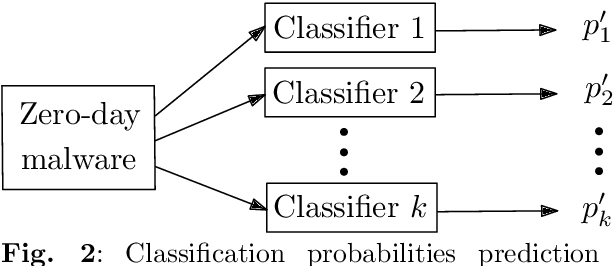
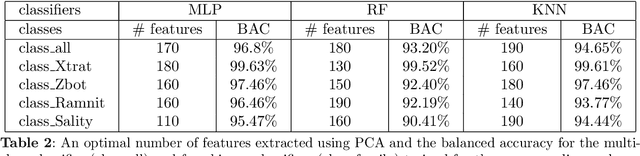
A large amount of new malware is constantly being generated, which must not only be distinguished from benign samples, but also classified into malware families. For this purpose, investigating how existing malware families are developed and examining emerging families need to be explored. This paper focuses on the online processing of incoming malicious samples to assign them to existing families or, in the case of samples from new families, to cluster them. We experimented with seven prevalent malware families from the EMBER dataset, with four in the training set and three additional new families in the test set. Based on the classification score of the multilayer perceptron, we determined which samples would be classified and which would be clustered into new malware families. We classified 97.21% of streaming data with a balanced accuracy of 95.33%. Then, we clustered the remaining data using a self-organizing map, achieving a purity from 47.61% for four clusters to 77.68% for ten clusters. These results indicate that our approach has the potential to be applied to the classification and clustering of zero-day malware into malware families.
Combining Generators of Adversarial Malware Examples to Increase Evasion Rate
Apr 14, 2023Antivirus developers are increasingly embracing machine learning as a key component of malware defense. While machine learning achieves cutting-edge outcomes in many fields, it also has weaknesses that are exploited by several adversarial attack techniques. Many authors have presented both white-box and black-box generators of adversarial malware examples capable of bypassing malware detectors with varying success. We propose to combine contemporary generators in order to increase their potential. Combining different generators can create more sophisticated adversarial examples that are more likely to evade anti-malware tools. We demonstrated this technique on five well-known generators and recorded promising results. The best-performing combination of AMG-random and MAB-Malware generators achieved an average evasion rate of 15.9% against top-tier antivirus products. This represents an average improvement of more than 36% and 627% over using only the AMG-random and MAB-Malware generators, respectively. The generator that benefited the most from having another generator follow its procedure was the FGSM injection attack, which improved the evasion rate on average between 91.97% and 1,304.73%, depending on the second generator used. These results demonstrate that combining different generators can significantly improve their effectiveness against leading antivirus programs.
Parallel Instance Filtering for Malware Detection
Jun 28, 2022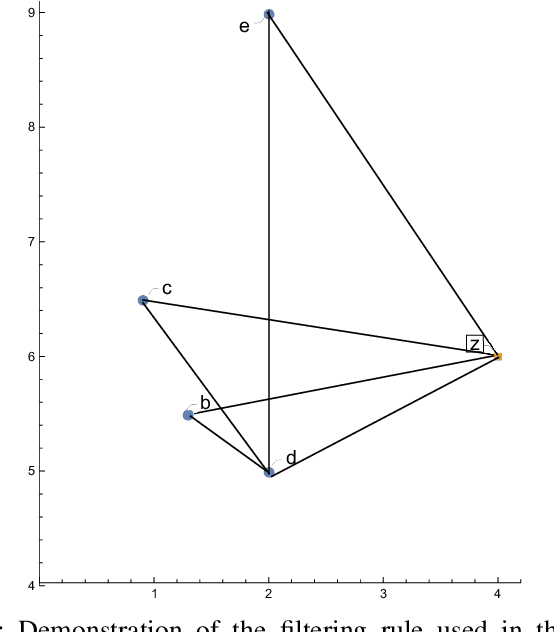
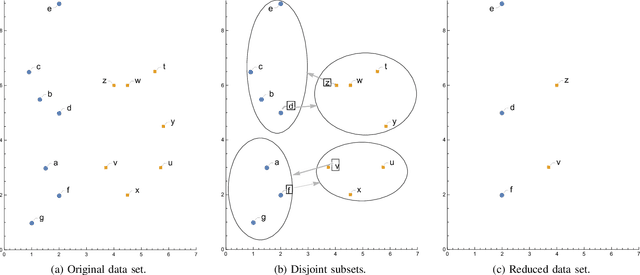
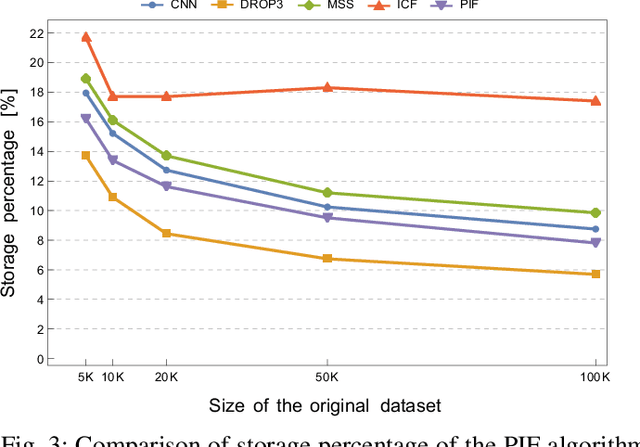
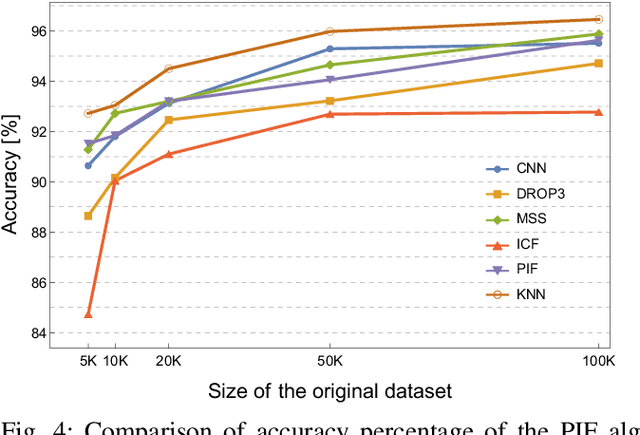
Machine learning algorithms are widely used in the area of malware detection. With the growth of sample amounts, training of classification algorithms becomes more and more expensive. In addition, training data sets may contain redundant or noisy instances. The problem to be solved is how to select representative instances from large training data sets without reducing the accuracy. This work presents a new parallel instance selection algorithm called Parallel Instance Filtering (PIF). The main idea of the algorithm is to split the data set into non-overlapping subsets of instances covering the whole data set and apply a filtering process for each subset. Each subset consists of instances that have the same nearest enemy. As a result, the PIF algorithm is fast since subsets are processed independently of each other using parallel computation. We compare the PIF algorithm with several state-of-the-art instance selection algorithms on a large data set of 500,000 malicious and benign samples. The feature set was extracted using static analysis, and it includes metadata from the portable executable file format. Our experimental results demonstrate that the proposed instance selection algorithm reduces the size of a training data set significantly with the only slightly decreased accuracy. The PIF algorithm outperforms existing instance selection methods used in the experiments in terms of the ratio between average classification accuracy and storage percentage.