 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Instance Filtering for Malware Detection
Paper and Code
Jun 28, 2022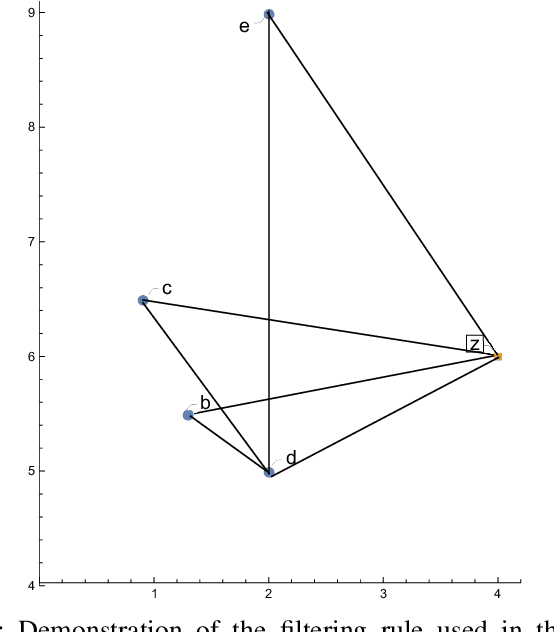
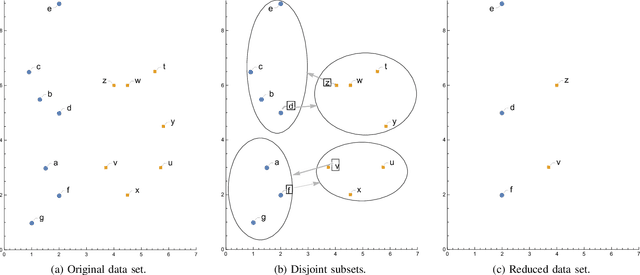
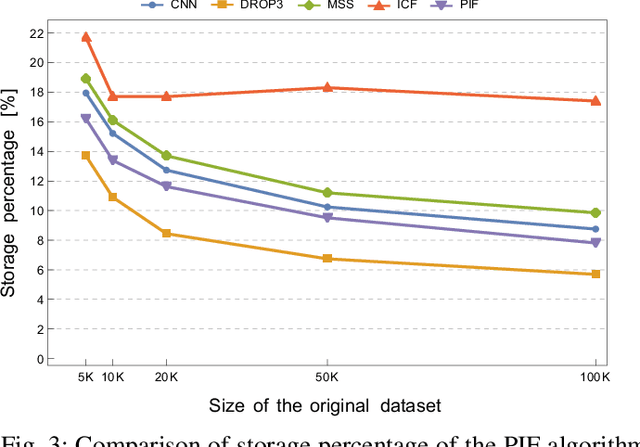
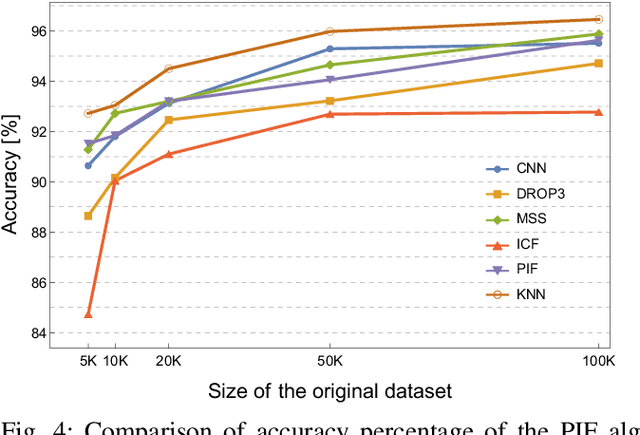
Machine learning algorithms are widely used in the area of malware detection. With the growth of sample amounts, training of classification algorithms becomes more and more expensive. In addition, training data sets may contain redundant or noisy instances. The problem to be solved is how to select representative instances from large training data sets without reducing the accuracy. This work presents a new parallel instance selection algorithm called Parallel Instance Filtering (PIF). The main idea of the algorithm is to split the data set into non-overlapping subsets of instances covering the whole data set and apply a filtering process for each subset. Each subset consists of instances that have the same nearest enemy. As a result, the PIF algorithm is fast since subsets are processed independently of each other using parallel computation. We compare the PIF algorithm with several state-of-the-art instance selection algorithms on a large data set of 500,000 malicious and benign samples. The feature set was extracted using static analysis, and it includes metadata from the portable executable file format. Our experimental results demonstrate that the proposed instance selection algorithm reduces the size of a training data set significantly with the only slightly decreased accuracy. The PIF algorithm outperforms existing instance selection methods used in the experiments in terms of the ratio between average classification accuracy and storage percentage.