 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration Attention: Instance-wise Temperature Scaling for Vision Transformers
Aug 12, 2025Probability calibration is critical when Vision Transformers are deployed in risk-sensitive applications. The standard fix, post-hoc temperature scaling, uses a single global scalar and requires a held-out validation set. We introduce Calibration Attention (CalAttn), a drop-in module that learns an adaptive, per-instance temperature directly from the ViT's CLS token. Across CIFAR-10/100, MNIST, Tiny-ImageNet, and ImageNet-1K, CalAttn reduces calibration error by up to 4x on ViT-224, DeiT, and Swin, while adding under 0.1 percent additional parameters. The learned temperatures cluster tightly around 1.0, in contrast to the large global values used by standard temperature scaling. CalAttn is simple, efficient, and architecture-agnostic, and yields more trustworthy probabilities without sacrificing accuracy. Code: [https://github.com/EagleAdelaide/CalibrationAttention-CalAttn-](https://github.com/EagleAdelaide/CalibrationAttention-CalAttn-)
Rethinking Gating Mechanism in Sparse MoE: Handling Arbitrary Modality Inputs with Confidence-Guided Gate
May 26, 2025Effectively managing missing modalities is a fundamental challenge in real-world multimodal learning scenarios, where data incompleteness often results from systematic collection errors or sensor failures. Sparse Mixture-of-Experts (SMoE) architectures have the potential to naturally handle multimodal data, with individual experts specializing in different modalities. However, existing SMoE approach often lacks proper ability to handle missing modality, leading to performance degradation and poor generalization in real-world applications. We propose Conf-SMoE to introduce a two-stage imputation module to handle the missing modality problem for the SMoE architecture and reveal the insight of expert collapse from theoretical analysis with strong empirical evidence. Inspired by our theoretical analysis, Conf-SMoE propose a novel expert gating mechanism by detaching the softmax routing score to task confidence score w.r.t ground truth. This naturally relieves expert collapse without introducing additional load balance loss function. We show that the insights of expert collapse aligns with other gating mechanism such as Gaussian and Laplacian gate. We also evaluate the proposed method on four different real world dataset with three different experiment settings to conduct comprehensive the analysis of Conf-SMoE on modality fusion and resistance to missing modality.
We Care Each Pixel: Calibrating on Medical Segmentation Model
Mar 07, 2025Medical image segmentation is fundamental for computer-aided diagnostics, providing accurate delineation of anatomical structures and pathological regions. While common metrics such as Accuracy, DSC, IoU, and HD primarily quantify spatial agreement between predictions and ground-truth labels, they do not assess the calibration quality of segmentation models, which is crucial for clinical reliability. To address this limitation, we propose pixel-wise Expected Calibration Error (pECE), a novel metric that explicitly measures miscalibration at the pixel level, thereby ensuring both spatial precision and confidence reliability. We further introduce a morphological adaptation strategy that applies morphological operations to ground-truth masks before computing calibration losses, particularly benefiting margin-based losses such as Margin SVLS and NACL. Additionally, we present the Signed Distance Calibration Loss (SDC), which aligns boundary geometry with calibration objectives by penalizing discrepancies between predicted and ground-truth signed distance functions (SDFs). Extensive experiments demonstrate that our method not only enhances segmentation performance but also improves calibration quality, yielding more trustworthy confidence estimates. Code is available at: https://github.com/EagleAdelaide/SDC-Loss.
PostHoc FREE Calibrating on Kolmogorov Arnold Networks
Mar 03, 2025Kolmogorov Arnold Networks (KANs) are neural architectures inspired by the Kolmogorov Arnold representation theorem that leverage B Spline parameterizations for flexible, locally adaptive function approximation. Although KANs can capture complex nonlinearities beyond those modeled by standard MultiLayer Perceptrons (MLPs), they frequently exhibit miscalibrated confidence estimates manifesting as overconfidence in dense data regions and underconfidence in sparse areas. In this work, we systematically examine the impact of four critical hyperparameters including Layer Width, Grid Order, Shortcut Function, and Grid Range on the calibration of KANs. Furthermore, we introduce a novel TemperatureScaled Loss (TSL) that integrates a temperature parameter directly into the training objective, dynamically adjusting the predictive distribution during learning. Both theoretical analysis and extensive empirical evaluations on standard benchmarks demonstrate that TSL significantly reduces calibration errors, thereby improving the reliability of probabilistic predictions. Overall, our study provides actionable insights into the design of spline based neural networks and establishes TSL as a robust loss solution for enhancing calibration.
Free-Knots Kolmogorov-Arnold Network: On the Analysis of Spline Knots and Advancing Stability
Jan 16, 2025



Kolmogorov-Arnold Neural Networks (KANs) have gained significant attention in the machine learning community. However, their implementation often suffers from poor training stability and heavy trainable parameter. Furthermore, there is limited understanding of the behavior of the learned activation functions derived from B-splines. In this work, we analyze the behavior of KANs through the lens of spline knots and derive the lower and upper bound for the number of knots in B-spline-based KANs. To address existing limitations, we propose a novel Free Knots KAN that enhances the performance of the original KAN while reducing the number of trainable parameters to match the trainable parameter scale of standard Multi-Layer Perceptrons (MLPs). Additionally, we introduce new a training strategy to ensure $C^2$ continuity of the learnable spline, resulting in smoother activation compared to the original KAN and improve the training stability by range expansion. The proposed method is comprehensively evaluated on 8 datasets spanning various domains, including image, text, time series, multimodal, and function approximation tasks. The promising results demonstrates the feasibility of KAN-based network and the effectiveness of proposed method.
Revisited Large Language Model for Time Series Analysis through Modality Alignment
Oct 16, 2024Large Language Models have demonstrated impressive performance in many pivotal web applications such as sensor data analysis. However, since LLMs are not designed for time series tasks, simpler models like linear regressions can often achieve comparable performance with far less complexity. In this study, we perform extensive experiments to assess the effectiveness of applying LLMs to key time series tasks, including forecasting, classification, imputation, and anomaly detection. We compare the performance of LLMs against simpler baseline models, such as single-layer linear models and randomly initialized LLMs. Our results reveal that LLMs offer minimal advantages for these core time series tasks and may even distort the temporal structure of the data. In contrast, simpler models consistently outperform LLMs while requiring far fewer parameters. Furthermore, we analyze existing reprogramming techniques and show, through data manifold analysis, that these methods fail to effectively align time series data with language and display pseudo-alignment behaviour in embedding space. Our findings suggest that the performance of LLM-based methods in time series tasks arises from the intrinsic characteristics and structure of time series data, rather than any meaningful alignment with the language model architecture.
Irregularity-Informed Time Series Analysis: Adaptive Modelling of Spatial and Temporal Dynamics
Oct 16, 2024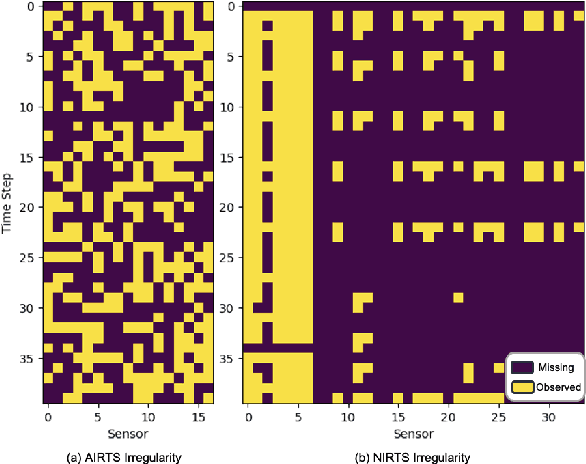

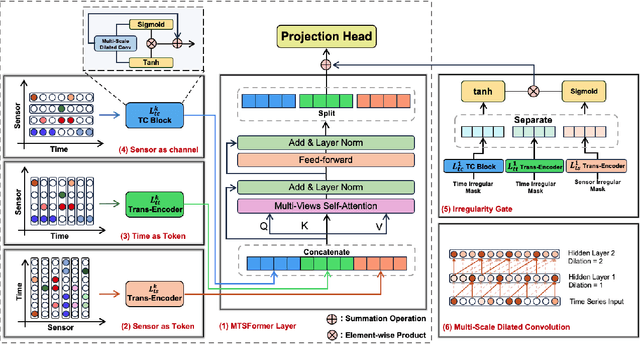
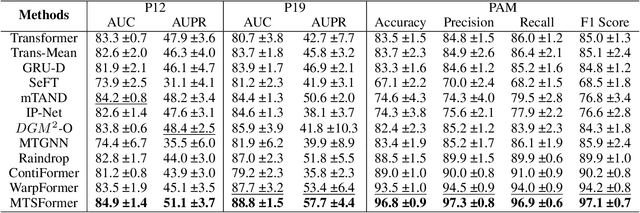
Irregular Time Series Data (IRTS) has shown increasing prevalence in real-world applications. We observed that IRTS can be divided into two specialized types: Natural Irregular Time Series (NIRTS) and Accidental Irregular Time Series (AIRTS). Various existing methods either ignore the impacts of irregular patterns or statically learn the irregular dynamics of NIRTS and AIRTS data and suffer from limited data availability due to the sparsity of IRTS. We proposed a novel transformer-based framework for general irregular time series data that treats IRTS from four views: Locality, Time, Spatio and Irregularity to motivate the data usage to the highest potential. Moreover, we design a sophisticated irregularity-gate mechanism to adaptively select task-relevant information from irregularity, which improves the generalization ability to various IRTS data. We implement extensive experiments to demonstrate the resistance of our work to three highly missing ratio datasets (88.4\%, 94.9\%, 60\% missing value) and investigate the significance of the irregularity information for both NIRTS and AIRTS by additional ablation study. We release our implementation in https://github.com/IcurasLW/MTSFormer-Irregular_Time_Series.git