 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALLaM: Large Language Models for Arabic and English
Jul 22, 2024



We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.
Sentiment Analysis of Arabic Tweets: Feature Engineering and A Hybrid Approach
May 22, 2018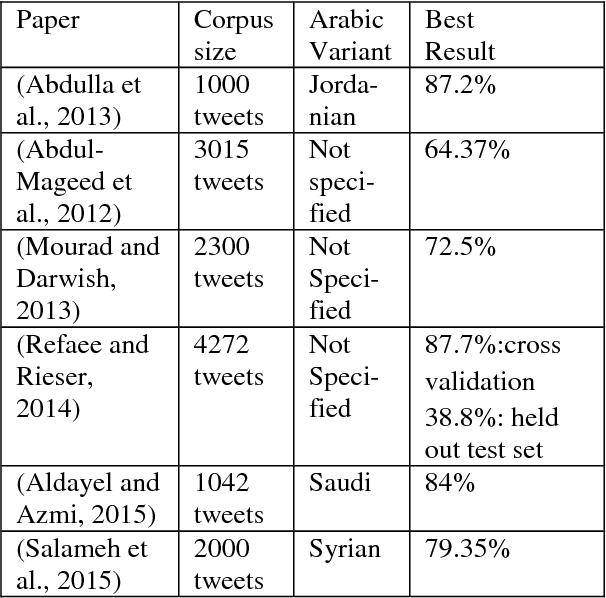
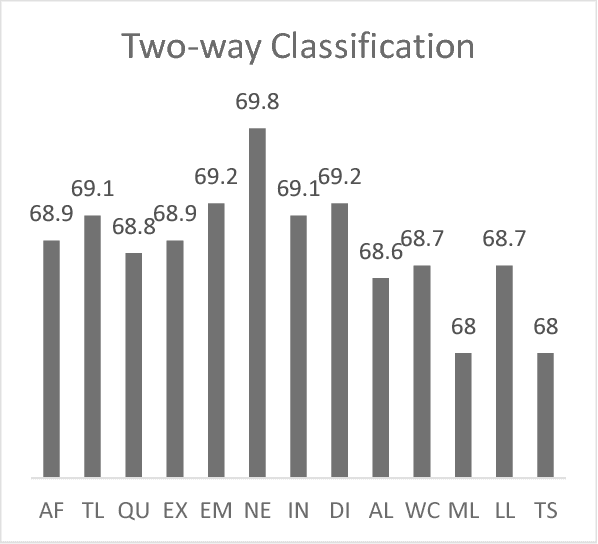
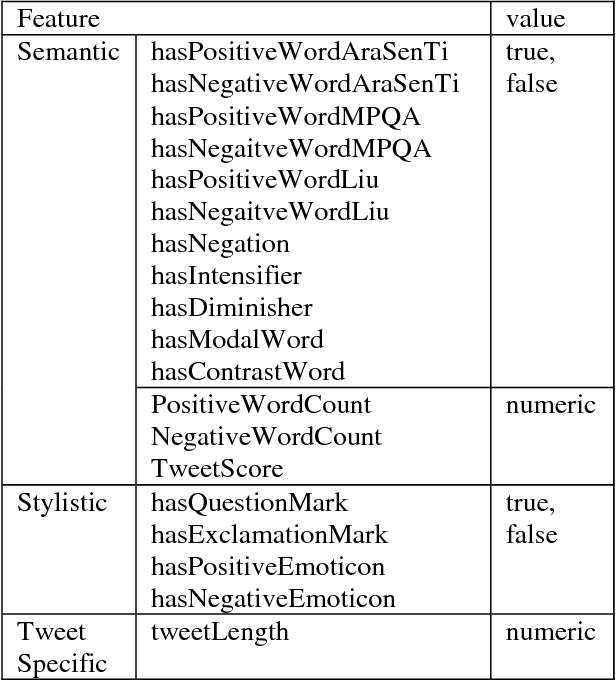

Sentiment Analysis in Arabic is a challenging task due to the rich morphology of the language. Moreover, the task is further complicated when applied to Twitter data that is known to be highly informal and noisy. In this paper, we develop a hybrid method for sentiment analysis for Arabic tweets for a specific Arabic dialect which is the Saudi Dialect. Several features were engineered and evaluated using a feature backward selection method. Then a hybrid method that combines a corpus-based and lexicon-based method was developed for several classification models (two-way, three-way, four-way). The best F1-score for each of these models was (69.9,61.63,55.07) respectively.