Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis of Arabic Tweets: Feature Engineering and A Hybrid Approach
May 22, 2018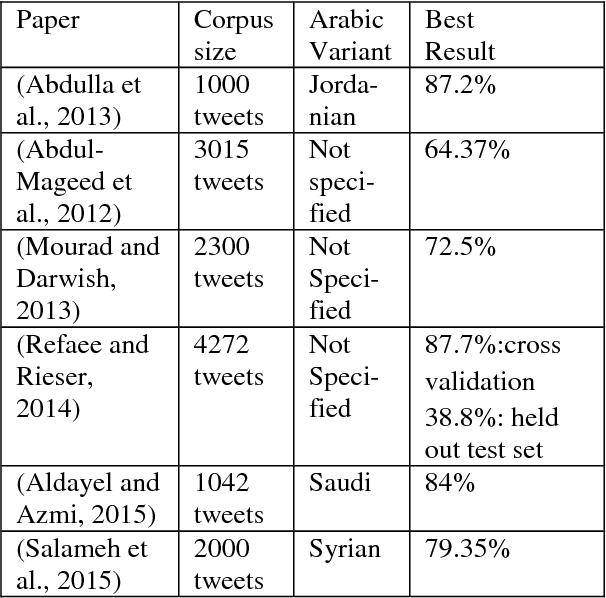
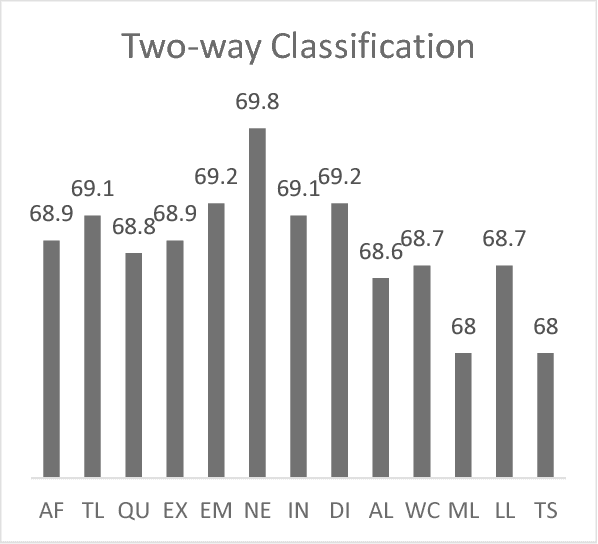
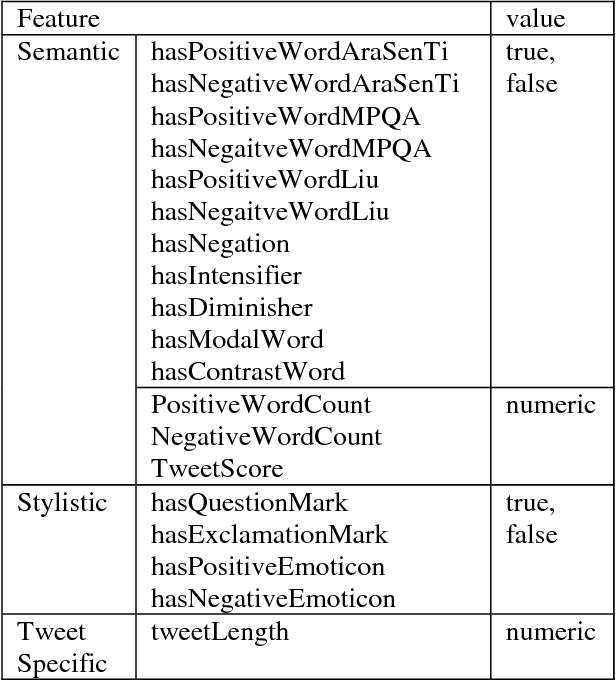

Sentiment Analysis in Arabic is a challenging task due to the rich morphology of the language. Moreover, the task is further complicated when applied to Twitter data that is known to be highly informal and noisy. In this paper, we develop a hybrid method for sentiment analysis for Arabic tweets for a specific Arabic dialect which is the Saudi Dialect. Several features were engineered and evaluated using a feature backward selection method. Then a hybrid method that combines a corpus-based and lexicon-based method was developed for several classification models (two-way, three-way, four-way). The best F1-score for each of these models was (69.9,61.63,55.07) respectively.
Via