 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Stable Black Box Explanations
Nov 12, 2020

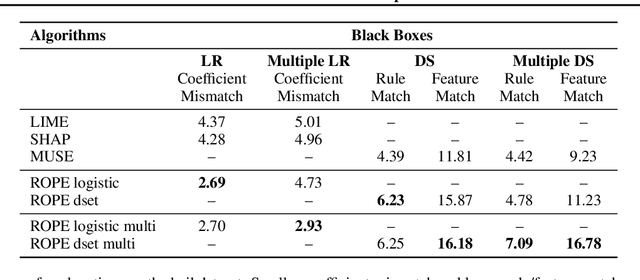
As machine learning black boxes are increasingly being deployed in real-world applications, there has been a growing interest in developing post hoc explanations that summarize the behaviors of these black boxes. However, existing algorithms for generating such explanations have been shown to lack stability and robustness to distribution shifts. We propose a novel framework for generating robust and stable explanations of black box models based on adversarial training. Our framework optimizes a minimax objective that aims to construct the highest fidelity explanation with respect to the worst-case over a set of adversarial perturbations. We instantiate this algorithm for explanations in the form of linear models and decision sets by devising the required optimization procedures. To the best of our knowledge, this work makes the first attempt at generating post hoc explanations that are robust to a general class of adversarial perturbations that are of practical interest. Experimental evaluation with real-world and synthetic datasets demonstrates that our approach substantially improves robustness of explanations without sacrificing their fidelity on the original data distribution.
A Measure of Similarity in Textual Data Using Spearman's Rank Correlation Coefficient
Nov 26, 2019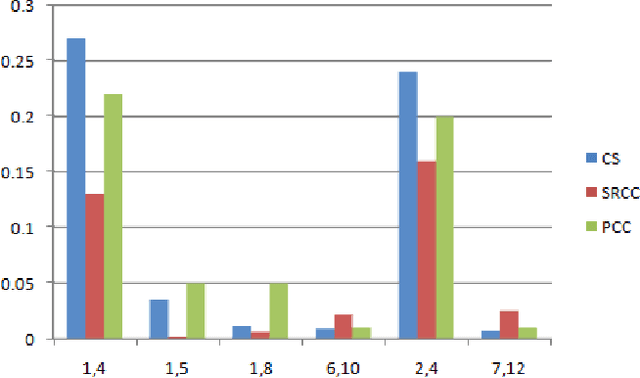
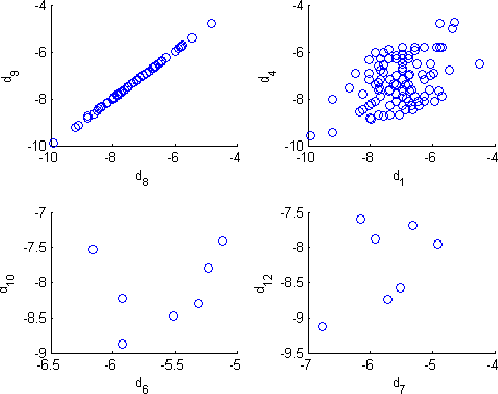
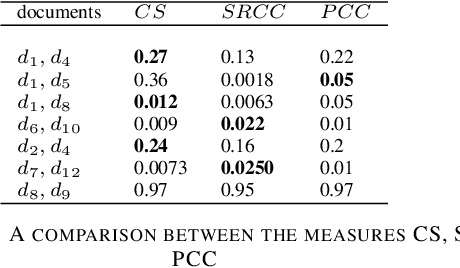
In the last decade, many diverse advances have occurred in the field of information extraction from data. Information extraction in its simplest form takes place in computing environments, where structured data can be extracted through a series of queries. The continuous expansion of quantities of data have therefore provided an opportunity for knowledge extraction (KE) from a textual document (TD). A typical problem of this kind is the extraction of common characteristics and knowledge from a group of TDs, with the possibility to group such similar TDs in a process known as clustering. In this paper we present a technique for such KE among a group of TDs related to the common characteristics and meaning of their content. Our technique is based on the Spearman's Rank Correlation Coefficient (SRCC), for which the conducted experiments have proven to be comprehensive measure to achieve a high-quality KE.
Network Embedding: An Overview
Nov 26, 2019

Networks are one of the most powerful structures for modeling problems in the real world. Downstream machine learning tasks defined on networks have the potential to solve a variety of problems. With link prediction, for instance, one can predict whether two persons will become friends on a social network. Many machine learning algorithms, however, require that each input example is a real vector. Network embedding encompasses various methods for unsupervised, and sometimes supervised, learning of feature representations of nodes and links in a network. Typically, embedding methods are based on the assumption that the similarity between nodes in the network should be reflected in the learned feature representations. In this paper, we review significant contributions to network embedding in the last decade. In particular, we look at four methods: Spectral Clustering, DeepWalk, Large-scale Information Network Embedding (LINE), and node2vec. We describe each method and list its advantages and shortcomings. In addition, we give examples of real-world machine learning problems on networks in which the embedding is critical in order to maximize the predictive performance of the machine learning task. Finally, we take a look at research trends and state-of-the art methods in the research on network embedding.
Prediction of Horizontal Data Partitioning Through Query Execution Cost Estimation
Nov 26, 2019

The excessively increased volume of data in modern data management systems demands an improved system performance, frequently provided by data distribution, system scalability and performance optimization techniques. Optimized horizontal data partitioning has a significant influence of distributed data management systems. An optimally partitioned schema found in the early phase of logical database design without loading of real data in the system and its adaptation to changes of business environment are very important for a successful implementation, system scalability and performance improvement. In this paper we present a novel approach for finding an optimal horizontally partitioned schema that manifests a minimal total execution cost of a given database workload. Our approach is based on a formal model that enables abstraction of the predicates in the workload queries, and are subsequently used to define all relational fragments. This approach has predictive features acquired by simulation of horizontal partitioning, without loading any data into the partitions, but instead, altering the statistics in the database catalogs. We define an optimization problem and employ a genetic algorithm (GA) to find an approximately optimal horizontally partitioned schema. The solutions to the optimization problem are evaluated using PostgreSQL's query optimizer. The initial experimental evaluation of our approach confirms its efficiency and correctness, and the numbers imply that the approach is effective in reducing the workload execution cost.
Stability of decision trees and logistic regression
Mar 03, 2019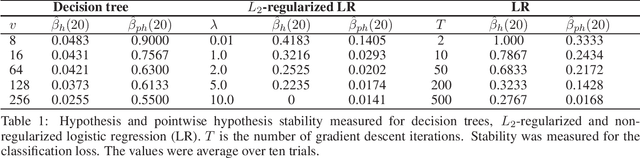
Decision trees and logistic regression are one of the most popular and well-known machine learning algorithms, frequently used to solve a variety of real-world problems. Stability of learning algorithms is a powerful tool to analyze their performance and sensitivity and subsequently allow researchers to draw reliable conclusions. The stability of these two algorithms has remained obscure. To that end, in this paper, we derive two stability notions for decision trees and logistic regression: hypothesis and pointwise hypothesis stability. Additionally, we derive these notions for L2-regularized logistic regression and confirm existing findings that it is uniformly stable. We show that the stability of decision trees depends on the number of leaves in the tree, i.e., its depth, while for logistic regression, it depends on the smallest eigenvalue of the Hessian matrix of the cross-entropy loss. We show that logistic regression is not a stable learning algorithm. We construct the upper bounds on the generalization error of all three algorithms. Moreover, we present a novel stability measuring framework that allows one to measure the aforementioned notions of stability. The measures are equivalent to estimates of expected loss differences at an input example and then leverage bootstrap sampling to yield statistically reliable estimates. Finally, we apply this framework to the three algorithms analyzed in this paper to confirm our theoretical findings and, in addition, we discuss the possibilities of developing new training techniques to optimize the stability of logistic regression, and hence decrease its generalization error.
Stacking and stability
Jan 26, 2019
Stacking is a general approach for combining multiple models toward greater predictive accuracy. It has found various application across different domains, ensuing from its meta-learning nature. Our understanding, nevertheless, on how and why stacking works remains intuitive and lacking in theoretical insight. In this paper, we use the stability of learning algorithms as an elemental analysis framework suitable for addressing the issue. To this end, we analyze the hypothesis stability of stacking, bag-stacking, and dag-stacking and establish a connection between bag-stacking and weighted bagging. We show that the hypothesis stability of stacking is a product of the hypothesis stability of each of the base models and the combiner. Moreover, in bag-stacking and dag-stacking, the hypothesis stability depends on the sampling strategy used to generate the training set replicates. Our findings suggest that 1) subsampling and bootstrap sampling improve the stability of stacking, and 2) stacking improves the stability of both subbagging and bagging.