 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Measure of Similarity in Textual Data Using Spearman's Rank Correlation Coefficient
Nov 26, 2019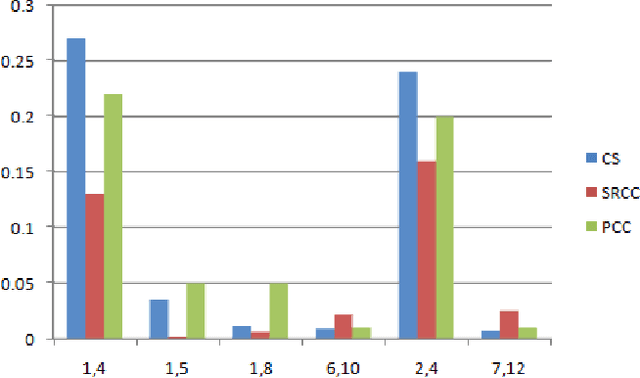
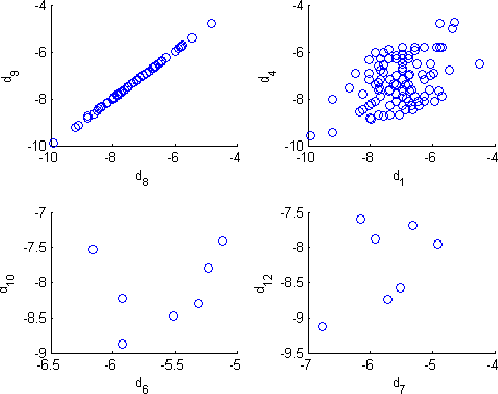
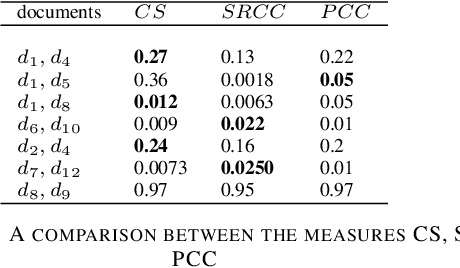
In the last decade, many diverse advances have occurred in the field of information extraction from data. Information extraction in its simplest form takes place in computing environments, where structured data can be extracted through a series of queries. The continuous expansion of quantities of data have therefore provided an opportunity for knowledge extraction (KE) from a textual document (TD). A typical problem of this kind is the extraction of common characteristics and knowledge from a group of TDs, with the possibility to group such similar TDs in a process known as clustering. In this paper we present a technique for such KE among a group of TDs related to the common characteristics and meaning of their content. Our technique is based on the Spearman's Rank Correlation Coefficient (SRCC), for which the conducted experiments have proven to be comprehensive measure to achieve a high-quality KE.